GitHub内部Agent实战:Qubot是怎么炼成的

GitHub官方放出内部数据分析Agent Qubot的构建复盘,从语义层、评估体系到信任建设,把企业级AI Agent落地踩过的坑讲了个遍。对正在做内部Agent的团队来说,这是一份难得的实战手册。
GitHub博客这周扔出了一篇相当扎实的复盘文章,标题朴素——《How we built an internal data analytics agent》,讲的是他们内部那只叫 Qubot 的数据分析 Agent 是怎么搭起来的。
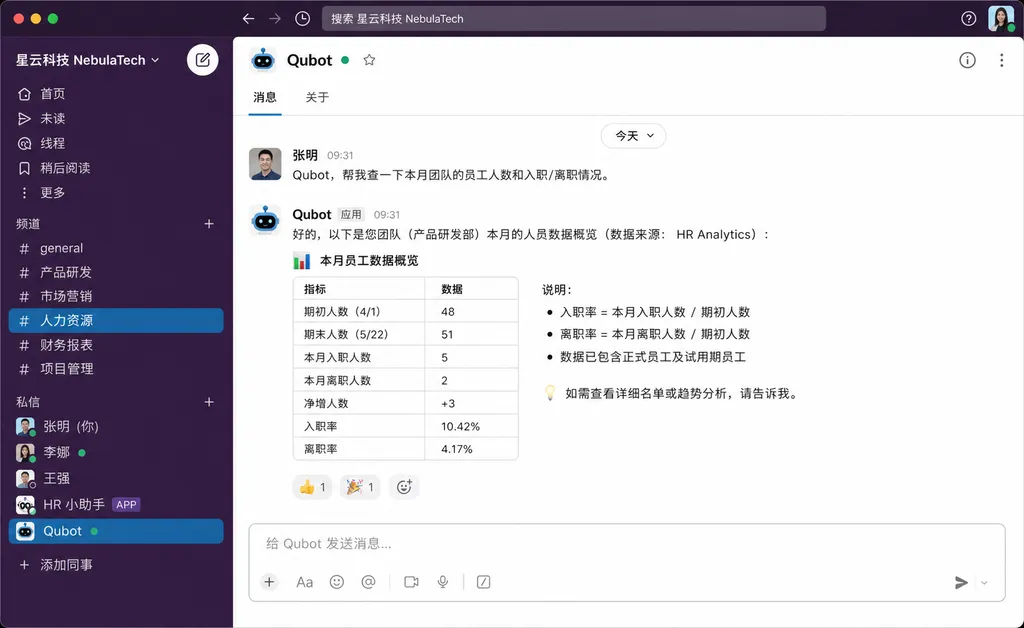
一句话概括 Qubot 的定位:GitHub 内部任何员工都可以用大白话提问,比如"上个月 Copilot 在 Enterprise 客户的 DAU 趋势怎么样"、"过去一个季度哪些仓库的 PR 合并率掉得最厉害",Qubot 会自己去查数据、跑 SQL、生成图表,最后把结论甩回来。听起来像是把 ChatGPT 的 Code Interpreter 接到内部数据仓库上——本质上确实如此,但 GitHub 这次把过程中的取舍和翻车经历都讲了,含金量比一般的产品宣传稿高不少。
这篇文章值得拿出来仔细嚼的原因很简单:现在每家公司都在搞自己的内部 Agent,大多数还停留在"接个 LLM、给个 SQL 数据库工具、Demo 跑通就上线"的阶段,然后被业务方骂得很惨。GitHub 这次把企业级 Agent 落地的几个核心矛盾——准确率 vs 覆盖度、自由度 vs 可控性、信任 vs 速度——拆得比较透。
为什么 GitHub 要自己造一个 Qubot
背景其实不复杂。GitHub 这种规模的公司,数据团队天天被各种临时性提数需求淹没。产品经理想看一个细分指标,得排队等数据分析师写 SQL;销售要看某个客户的使用情况,又得发工单。BI 工具像 Looker、Tableau 这些是有的,但报表是死的,问题是活的——新问题往往要么报表里没有,要么藏在五个看板的交叉点里。
GitHub 内部估算过,数据团队大概有 30%-40% 的时间花在这种重复性的提数上,而真正有创造性的深度分析反而被挤压。这是几乎所有大公司数据团队的通病。
Qubot 想解决的就是这件事:让员工自助查询,把数据团队从重复劳动里解放出来。但"自助式 BI"这个概念至少喊了十年,从 Tableau 到 Mode 到 Hex,没一个真正解决问题,因为非技术员工根本写不来 SQL,也搞不清字段语义。LLM 出现之后,Text-to-SQL 看起来终于有戏了——但只是看起来。
第一个坑:Text-to-SQL 在生产环境是不够用的
GitHub 团队一开始也是奔着"用 Copilot 把自然语言翻译成 SQL"这个最直觉的方案去的。然后很快就撞墙了。
问题不在于模型生成不了 SQL——GPT 系列写 SQL 早就不是问题。问题在于:模型不知道你公司的数据到底意味着什么。
举个例子。有人问"上周活跃用户数是多少"。听起来简单吧?但在 GitHub 内部:
- "活跃用户" 是指登录过的,还是有过任意 Git 操作的,还是触发过 Copilot 补全的?
- "用户" 是指 GitHub 账户,还是 Enterprise 席位,还是去重后的真人?
- "上周" 用的是 UTC 还是 PST?是自然周还是滚动 7 天?
- 用哪张表?fact_user_activity 还是 dim_users 还是某个 dbt 模型?
这些定义散落在数据团队的脑子里、Confluence 文档里、dbt 的 yml 文件里。一个新入职的数据分析师都得花两周才能搞清楚,让 LLM 一上来就答对,纯属做梦。
直接结果是:早期版本 Qubot 的 SQL 经常"语法正确、逻辑乱来"——查出来的数字看起来像那么回事,但其实口径完全错了。这种错误比直接报错更危险,因为没人发现。
解法:语义层是 Agent 的灵魂
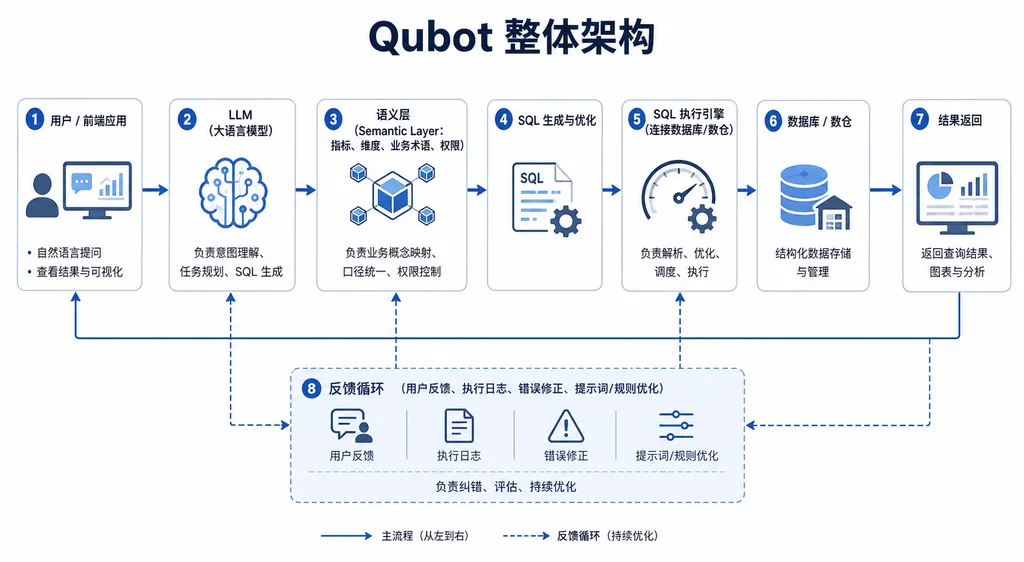
GitHub 给出的核心答案,也是这篇文章最值钱的部分——语义层(Semantic Layer)才是企业 Agent 的核心,不是 LLM 本身。
他们的做法是构建了一套结构化的元数据体系,把每个业务指标、每个维度、每张表的口径明确地写下来,让 LLM 在生成查询前先去"查字典"。这套语义层包括:
- 指标定义:每个 metric 一个唯一名字,比如
copilot_weekly_active_users,对应一段经过审核的 SQL 模板 - 维度字典:可以按哪些维度切分(plan_type、region、team_size 等),每个维度的允许取值
- 同义词映射:"DAU"、"日活"、"daily active" 都指向同一个指标
- 关系图谱:哪些表能 join、通过哪个键 join
这听起来很像 Cube.js、LookML、dbt Metrics 那套东西——本质上确实是。但 GitHub 的关键认知是:语义层不是给 BI 工具用的,而是给 Agent 用的。当 Agent 拿到一个自然语言问题,它先要做的不是写 SQL,而是把问题映射到语义层里的具体指标和维度,映射不上就反问用户澄清,而不是瞎猜。
这个顺序的变化非常关键。前者是"先生成、后校验",后者是"先约束、后生成"。前者错误率高且难发现,后者覆盖度低但每个回答都站得住。GitHub 明确选了后者。
评估体系:没有 eval 就没有迭代
文章里另一个被反复强调的点是评估(evaluation)。这事儿在做 Agent 的团队里说了一万遍,但真正做扎实的没几个。
GitHub 的做法分了几层:
- 黄金问题集:数据团队人肉标注了几百个典型问题和对应的正确答案,作为回归测试
- 分类评估:把问题按难度、类型分类,分别看准确率,避免被简单问题拉高平均分
- 离线 + 在线:离线跑 benchmark,线上用真实用户反馈做隐式信号(用户有没有重新提问、有没有点踩)
- 失败案例归档:每个翻车 case 都进 backlog,要么改 prompt,要么补语义层,要么承认 Agent 搞不定
这套东西看着朴素,但 GitHub 强调一点:Agent 的迭代速度完全取决于评估速度。如果你改了 prompt 不知道是变好还是变坏,那基本就是在赌博。
信任建设:让用户看见 Agent 的思考过程
这是我个人最欣赏 GitHub 这套设计的地方。Qubot 在回答问题时,不是直接甩出一个数字,而是会展示:
- 我把你的问题理解成了哪个指标、哪些维度
- 我用的是哪个 SQL 模板
- 实际跑出来的 SQL 长这样
- 数据是从哪张表来的,最后更新时间
用户可以在每一步质疑或修正。如果 Agent 把"活跃用户"理解成了登录用户,但你其实想问的是 Copilot 用户,你可以一键改正,Agent 会记住这次澄清。
这个设计的本质是:在企业场景下,Agent 的可解释性比响应速度重要 10 倍。员工拿这个数字去开会、做决策、写汇报,如果不知道数字怎么来的,没人敢用。Looker 这些工具用户敢用,是因为他们知道数据团队建了模型;Qubot 想被信任,就得把同样的透明度做出来。
反观市面上一堆 Text-to-SQL 产品,恨不得把过程藏起来显得自己"智能",结果就是没人敢把它放进决策流程。
工具调用与 Agent 编排
技术架构上,Qubot 是个比较典型的 ReAct-style Agent。核心工具集大概包括:
search_metrics(query):在语义层里搜匹配的指标get_metric_definition(name):拿到指标的完整定义run_query(metric, dimensions, filters):参数化执行查询visualize(data, chart_type):生成图表ask_clarification(question):反问用户
注意这里没有 run_raw_sql 这种万能工具。GitHub 故意限制了 Agent 的自由度——只能调用语义层里已经定义好的指标,不能瞎写 SQL。这又是一次"用约束换可靠性"的决策。
代价是覆盖度低。语义层里没定义的问题,Qubot 就答不了,得等数据团队补。但 GitHub 认为这个权衡是值得的:与其让 Agent 偶尔答对、经常错得离谱,不如让它答得少但每个都对。
几个值得国内团队抄作业的点
看完这篇博客,几条经验放在国内做企业 Agent 的团队这里同样成立:
- 别迷信端到端 LLM。把 LLM 当推理引擎,把业务逻辑放在结构化的语义层里。
- 先做评估再做产品。没有 eval pipeline 就别上线,否则就是在用户身上做 A/B test。
- 可解释性优先。把 Agent 的每一步都暴露出来,让用户敢用。
- 限制自由度。给 Agent 一个受控的工具集,比给它一个"什么都能干"的环境靠谱得多。
- 冷启动靠人肉。语义层、黄金问题集、典型 case 这些都得靠人工标注,没有捷径。
第 5 点尤其值得提。很多团队幻想着"上一个 Agent 就能省人力",结果是省了下游的人力(提数的),但前期得砸更多人力(建语义层、做评估、标 case)。GitHub 团队也明说了,Qubot 项目早期数据团队的工作量不降反升,要等语义层覆盖度够了才开始回本。
这事儿对开发者意味着什么
GitHub 这篇文章其实给出了一个企业级 Agent 的参考架构。Copilot 现在自己已经在做 Agent Mode、第三方 Agent 接入这些事,Qubot 是 GitHub 把同一套方法论用在内部场景的样本。
更广的意义在于:2026 年这个时间点,Agent 已经过了"能不能 work"的阶段,进入"怎么做才能在生产环境里可靠 work"的阶段。LLM 本身的能力不再是瓶颈,工程化、评估体系、领域知识沉淀才是。
对正在做类似产品的团队来说,这篇博客比看十篇 Twitter 上的 Agent 框架介绍都有用。Qubot 不是什么花哨的新概念,它是一套被实际部署、被几千名 GitHub 员工真实使用、被迭代了一年多的系统——这种实战经验放出来的密度,比论文还高。
参考来源
- GitHub features - Copilot Agents:GitHub Copilot Agents 官方介绍页,可看到 Copilot 在 Agent 方向的整体产品布局
- github-agent-driven-development-translation.md:GitHub Agent 驱动开发的中文译文,对理解 Copilot Agent 工作流有帮助
- GitHub Copilot 和 AI Agent 如何拯救传统系统:知乎上关于 Copilot Agent 在传统系统现代化场景的实战分享


