Netflix 工程师开源 Headroom:给 AI Agent 装上「压缩机」

Netflix 高级工程师 Tejas Chopra 开源的 Headroom 在 LLM 入口处做可逆压缩,实测 Token 消耗砍掉 60%-95%,GitHub 已飙到 3.96 万星,最近在国内外 AI 圈集体爆红。
一张 287 美元的账单,捅破了 AI Agent 的成本窗户纸
Netflix 高级工程师 Tejas Chopra 大概没想到,自己年初顺手扔在 GitHub 上的一个小工具,会在六月份突然成为全球开发者社区的热门话题。截至今天,Headroom 这个项目的 Star 数已经冲到 3.96 万,仅仅是过去一周就涨了将近一万颗星。在他自己的统计里,这个工具到目前为止已经为用户省下大约 70 万美元的 API 账单,累计释放了超过 2000 亿个 Token。
故事的起点没什么传奇色彩:Chopra 在做自己的个人项目时,月底收到一张 287 美元的 API 账单。他不是没用过 LLM,但作为一名常年和分布式存储打交道的工程师,他的第一反应是去翻日志——结果发现真正花钱的不是他写的那些 prompt,而是被 Agent 自动塞进上下文的那一堆「废话」:层层嵌套的 JSON、重复打印的 API 响应、动辄几千行的日志,以及 RAG 召回时一并扔进去的整段文档。
他后来在开源峰会上引用过一个数字:AI 应用里 大约 76% 的 Token 是被「读输入」消耗掉的,而不是用来生成有用的回答。这个比例听上去夸张,但任何写过 Claude Code、Cursor、Codex Agent 集成的人,看一眼 trace 都会承认它没毛病。
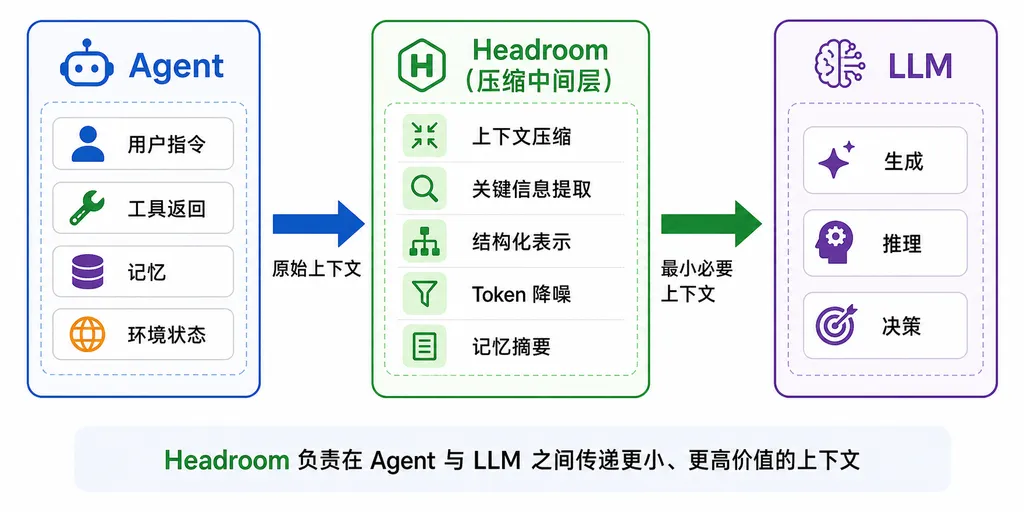
Headroom 在干一件什么事
用一句话讲清楚:在你的 Agent 把上下文丢给 LLM 之前,它先在本地做一道可逆压缩。
这听上去像是给 HTTP 加 gzip,但 LLM 的世界没那么简单——你不能指望 GPT-4 或者 Claude 去解压一段二进制流,模型读到的必须是「它认得的语言」。Headroom 的做法是把上下文里的结构化、半结构化、纯文本内容分别识别出来,针对每一种用不同的策略做语义级的瘦身:
- 工具输出(tool calls 的返回):典型的 JSON 嵌套地狱,去重、抽骨架、引用化
- 日志:模板抽取、时间戳归一、重复块折叠
- RAG 召回片段:摘要 + 关键句保留
- 历史对话:旧轮次的 tool output 用引用占位
- 代码:基于 AST 的结构压缩
压缩之后的内容仍然是模型能直接读懂的「人话」或者「半结构化文本」,但体积可能只剩原来的 10%。原始的完整数据并不会丢——它被缓存在本地的 Redis 或者 SQLite 里,等 LLM 真的需要细节的时候,再通过 Headroom 自创的 CCR(Compress, Cache and Retrieve) 机制回查。换句话说,模型看到的是「索引 + 摘要」,需要展开的时候再按需展开。
这套思路其实和数据库领域的列存压缩、查询下推一脉相承,只不过把战场从 OLAP 搬到了 LLM 的上下文窗口里。Chopra 是搞存储的,难怪一上来就奔着这个方向去。
拆开看:六种压缩算法和一条 10 阶段流水线
Headroom 在 README 里很坦诚地把内部组件都列出来了,没有藏着掖着。核心几个模块值得展开讲:
1. ContentRouter:内容类型识别
这是整个压缩管线的入口。它要做的事情说起来简单:判断当前这段输入是 JSON、是代码、是日志、是 Markdown、还是普通自然语言。但工程上很烦——很多 Agent 的 tool 返回是「带着 markdown 包装的 JSON 里嵌着一段代码」,路由器得有能力拆层判断。Headroom 用了基于启发式规则 + 轻量分类器的组合方案,比纯正则可靠很多。
2. SmartCrusher:JSON 杀手
这是 Headroom 里被讨论最多的组件。一段嵌套五六层、字段名重复出现几百次的 API JSON,丢给模型其实只需要保留结构骨架和具体值——SmartCrusher 会把 schema 抽出来一次,剩下的数据用引用方式紧凑表达。在他们公布的代码搜索场景实测里,17,765 个 Token 压到 1,408 个,节省 92%。SRE 事故调试场景里那一堆带堆栈和指标的日志,65,694 个 Token 降到 5,118 个,同样省 92%。
3. CodeCompressor:AST 感知
对代码做压缩这件事,行业里其实有不少人尝试过,但大多停留在「删空行、删注释」这种朴素层面。Headroom 走的是 AST 路线:把代码 parse 成语法树,根据当前问题的上下文判断哪些节点是「主干」(要展开)、哪些是「枝叶」(可以折叠成签名)。这个思路在面对几千行的大文件时收益尤其明显,但缺点也明显——多语言支持需要堆 parser,目前对 Python、TypeScript、Go、Rust 的覆盖比较完整,冷门语言会退化为基于规则的策略。
4. Kompress-base:小模型压缩大模型输入
这是 Headroom 比较「猛」的一手。他们训练了一个小尺寸的语言模型,专门用来把自然语言段落压成更短的形式,同时尽量保留语义。这种「用小模型省大模型的钱」的思路,跟微软之前的 LLMLingua 有点像,但 Kompress-base 据说是针对 Agent 场景重新训练的,对 tool output 和 log 这类「半结构化自然语言」的还原度更高。
5. CacheAligner:榨干 KV Cache
这一步纯属省钱黑魔法。OpenAI、Anthropic、DeepSeek 等主流 Provider 现在都对 prompt 前缀有 KV Cache 折扣,命中缓存能省 50%-90% 的输入费用。CacheAligner 做的事情是:保证压缩后的 prompt 前缀在多轮之间尽量稳定,不要因为某个时间戳或某个 ID 的变化导致整段前缀失效。这个细节非常工程师,但收益直接体现在账单上。
实测数据:60%-95% 这个区间靠谱吗
社区里已经有不少人跑过对照测试。一个比较有代表性的数字是:在 Claude Code 接 Headroom 的场景下,精度保留率大约 97%,Token 节省幅度集中在 70%-90%。也就是说,95% 这个上限确实存在,但更多出现在 JSON、日志这类「重复度极高」的场景;纯自然语言对话场景,省下来的更多是 30%-50%。
但即便按 60% 的下限算,对每天烧几十美元 Token 的 Agent 用户来说,一个月省下几百刀是稳的。Gartner 今年 3 月的预测说万亿参数模型推理成本到 2030 年会降 90%,问题是大家等不到 2030 年——现在每月账单已经在炸了。
三种集成方式,挑顺手的用
Headroom 的工程化做得相当到位,没有强行让你改代码。它提供了三种集成姿势:
# 方式一:Proxy 模式,零侵入
headroom proxy --port 8787
# 然后把你的 LLM base_url 指向 localhost:8787 即可
# 方式二:Agent Wrap,一行命令包装
headroom wrap claude
headroom wrap cursor
# 方式三:作为 MCP Server
headroom mcp --stdio
Proxy 模式最适合做评估——你只要改一个 base_url,剩下的代码完全不动,就能立刻看到节省效果。Wrap 模式是给 Claude Code、Cursor、Codex 这类 CLI Agent 用的,原作者似乎对 Claude Code 用户特别上心,wrap 之后会自动接管对话历史压缩。MCP 模式则把 Headroom 暴露成一个标准 MCP 服务,任意支持 MCP 协议的客户端都能调用其压缩/解压能力。
Python 和 TypeScript SDK 也都给了,需要在代码里精细控制压缩策略的(比如对某些字段强制保留原文)可以走 SDK 路线。
它解决了一个被低估的问题
过去半年 AI Agent 的工程实践里,大家把注意力都放在了 prompt engineering、tool use、reasoning loop 这些环节,对「上下文里塞了多少废话」反而是钝感的。Cursor、Claude Code 这些工具表面上很神,但只要你打开 Anthropic Console 看一眼 token 消耗分布,你会发现 90% 的开销都在 input tokens 上,其中又有大半是反复出现的工具调用结果。
Headroom 真正切中的痛点不是「压缩技术多牛」,而是 承认了 Agent 上下文是一个需要专门治理的资源。在它之前,开发者要么靠手写截断、要么靠粗暴的滑动窗口,本质上都是「砍信息保 Token」;Headroom 是「保信息也省 Token」,这中间差了一个工程哲学。
当然,这个工具不是没缺点。本地缓存意味着你得维护一个 Redis 或 SQLite 实例,部署复杂度上升了一档;Kompress-base 这个压缩模型本身也要占资源;对极度结构化的二进制 protocol(比如 protobuf 转字符串),目前的压缩收益反而有限。但对于绝大多数「上下文里塞满 JSON 和日志」的 Agent 场景,它确实是目前最务实的解决方案。
顺带一提
如果你想直接试一下 Headroom 在不同 LLM Provider 上的压缩效果,OpenAI Hub(openai-hub.com)一个 Key 就能同时调 GPT-4、Claude、Gemini、DeepSeek 这些模型,把 Headroom Proxy 的上游指过去就能横向对比账单——压缩率、KV cache 命中率、精度保留率,一次跑齐。
AI 的成本从来不是单点问题,是整条链路上每一个环节抠出来的。Headroom 抠的是上下文这一段,能抠出 60% 还是 95%,取决于你的 Agent 之前有多浪费。
参考来源
- IT之家:AI 账单飙升?Netflix 工程师开源项目 Headroom 爆火 —— Headroom 项目背景、技术原理及实测数据的中文报道
- 软件之家相关报道汇总 —— 关于 Headroom 项目的更多动态信息


