DVD-JEPA 开源:一个会预测的最小世界模型

一个 16×16 像素的弹跳 DVD logo,被一个 32 维的潜空间完整建模出来。DVD-JEPA 用最简陋的实验,把 LeCun 的 JEPA 思想讲清楚了——并且全程可复现。
一个 16×16 的「世界」,把 JEPA 讲明白了
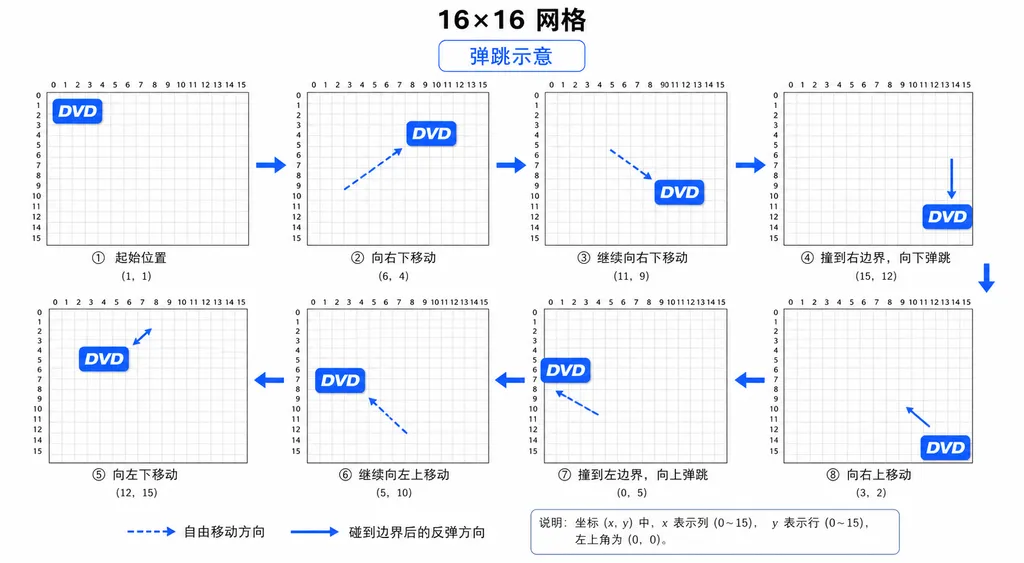
这两天 r/MachineLearning 上一个叫 DVD-JEPA 的项目突然冒头,同时挂在 paperswithcode 的 Anomaly Detection 趋势榜上。作者把它定位成「我们能造出来的、对 JEPA 思想最小但最诚实的演示」——世界就是一个在 16×16 网格里弹来弹去的 DVD logo,没有标签、没有 decoder,只用一个 32 维的潜空间,去预测下一帧的「表示」而不是像素。
听起来像个玩具,但这正是它有意思的地方。过去两年关于「世界模型」的讨论越来越多,V-JEPA、V-JEPA 2、再到去年底 Meta 推出的 VL-JEPA,整个 JEPA 路线被 Yann LeCun 推得很猛。问题是,几乎所有公开复现都需要几百块 GPU、几亿参数、海量视频。普通研究者想真正理解「预测表示,而不是预测像素」到底意味着什么,几乎没有入口。DVD-JEPA 把这个门槛压到了一台笔记本能跑的程度。
先把 JEPA 的赌注说清楚
传统视频世界模型的做法,是逐帧逐像素地预测未来。给你前 t 帧,模型吐出第 t+1 帧的 RGB。这条路线最大的问题不是算力,而是目标函数本身就是错的。
想象一段有树叶在风中抖动的视频。每一片叶子下一秒会怎么动,从物理上讲是不可预测的——它依赖于湍流、温度、甚至昆虫扰动。一个像素级目标函数会逼着模型去拟合这些噪声,结果就是:模型把大量容量浪费在「猜叶子」,反而忽略了真正重要的高层结构(比如那个人要走过来了)。
JEPA 的赌注是:不要预测像素,预测表示。让编码器自由地丢弃那些它预测不了的东西,只保留可预测的部分。这件事 LeCun 在 2022 年那篇 A Path Towards Autonomous Machine Intelligence 里讲得很清楚,但论文从来都是论文,真正能把它跑通并讲清楚的最小案例一直缺位。I-JEPA、V-JEPA 都太重,看完之后你还是不知道核心机制是不是真的在起作用,还是被规模掩盖了。
DVD-JEPA 就是冲着这个空缺去的。
它是怎么搭的
架构非常标准的 JEPA 三件套:
- Context Encoder:吃当前观测,输出 32 维潜向量
- EMA Target Encoder:context encoder 的指数滑动平均副本,用来给「未来」打标签
- Latent Predictor:在 32 维潜空间里,从当前向量预测下一时刻向量
训练目标就是让 predictor 输出的向量逼近 target encoder 输出的向量。没有解码器,没有重建 loss,没有标签。这是 JEPA 的标志:损失函数完全活在 embedding 空间里。
为了防止「表示崩塌」(representation collapse,所有输入都映射到同一个向量这种作弊解),DVD-JEPA 沿用了 V-JEPA 那一套:EMA 目标网络 + 不对称结构。这是 JEPA 系列最微妙也最关键的工程细节,过去在大模型里被很多噪音盖住,在这个 16×16 的世界里反而能看得一清二楚。
obs_t ──► ContextEncoder ──► z_t ──┐
├──► Predictor ──► ẑ_{t+1}
│ │
obs_{t+1} ──► TargetEncoder(EMA) ──► z_{t+1} ◄──── L2 loss ─┘
世界本身的物理也极简:一个 logo,遇到墙就反弹,速度恒定。换句话说,真实的世界状态可以被 4 个数完全描述(x、y、vx、vy)。这给了一个非常硬的验证基线:如果你的 32 维潜空间真的学到了世界,那 4 个自由度应该能被线性解码出来。
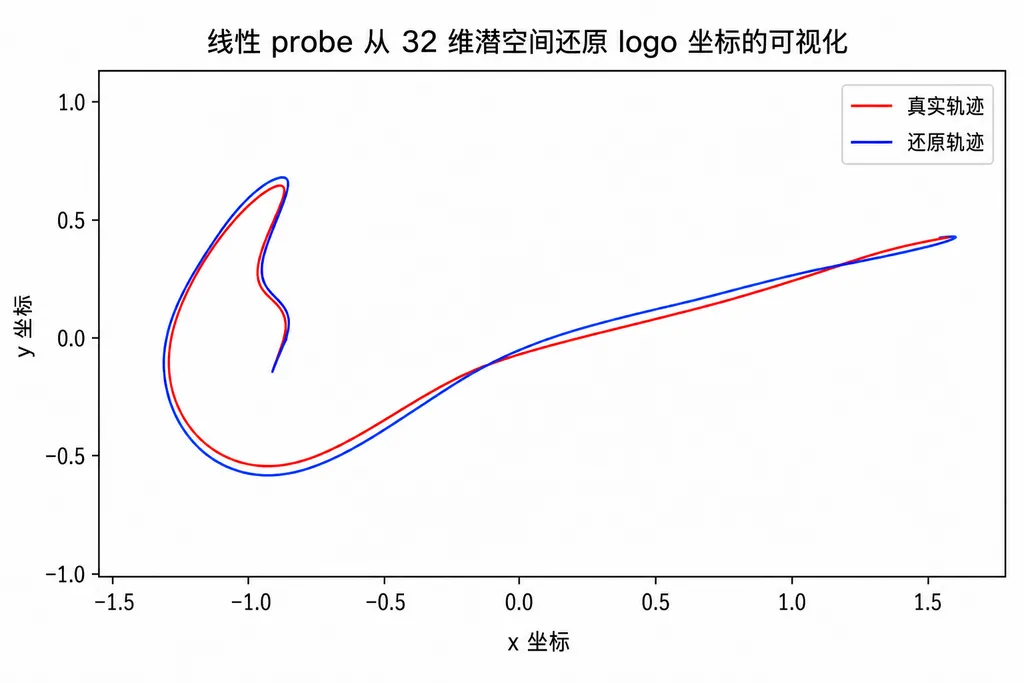
结果:32 维里藏着完整的物理
训练完之后,作者冻结 encoder,在那 32 维潜向量上挂一个线性 probe,让它去回归 logo 的真实 (y, x) 坐标。
结果是 0.73 像素的平均误差。
注意几件事:
- 训练全程没有给过坐标标签。模型完全是自监督的。
- 线性 probe,意味着位置信息在潜空间里几乎是线性可分的——这是表示学习能拿到的最干净的结果,比 MLP probe 强得多。
- 0.73 px 在 16×16 网格上,相当于 4.5% 的相对误差。考虑到 logo 本身也有大小,这基本就是「学会了」。
更进一步,速度方向(vx、vy)同样能从单帧潜向量里解出来——这意味着 encoder 不只是记住了「现在在哪」,还记住了「正在往哪走」,因为只有这样 predictor 才能预测下一帧。这件事 V-JEPA 论文里也讲过,但放在一个 16×16 的玩具世界里看,反而格外有说服力。
为什么这个玩具值得认真看
如果只是「JEPA 在小世界能 work」,那这事最多发个推就完了。DVD-JEPA 之所以值得写一篇,是因为它把 JEPA 从一个口号还原成了可解剖的实验。
现在做 JEPA 复现有几个长期痛点:
- 崩塌很隐蔽。在大模型里,损失看起来在下降,但你不知道 encoder 到底有没有偷懒。DVD-JEPA 用线性 probe 给出了一个硬指标——能解出坐标,就是真的学到了。
- EMA momentum、predictor 容量、潜空间维度这些超参的作用,在大模型里被噪声盖住。在 32 维世界里,你改一个超参马上能看出区别。
- 可复现成本极低。读者可以跑通整个训练在分钟级,这对教学和早期研究都非常重要。
这种「最小可解释实验」在 ML 圈一直是稀缺品。上一次类似的工作大概是 toy transformer 那波 mechanistic interpretability,把注意力头拆得明明白白。DVD-JEPA 在世界模型这条线上扮演的就是类似角色。
它跟 V-JEPA 2、VL-JEPA 是什么关系
顺手把这条线捋一遍,因为读者大概率在不同语境下见过这些名字:
| 模型 | 时间 | 定位 | |---|---|---| | I-JEPA | 2023 | 图像,单帧表示预测 | | V-JEPA | 2024 | 视频,引入时空 mask | | V-JEPA 2 | 2025 | 加入机器人交互数据,可做规划 | | VL-JEPA | 2025 末 | 视觉-语言联合,对标 VLM | | DVD-JEPA | 2026.06 | 最小复现,教学/研究友好 |
V-JEPA 2 已经能在真实机器人上做规划了,VL-JEPA 用 V-JEPA 2 + Llama 3.2 拼出了一个比传统 VLM 训练快 2.85 倍的视觉语言模型。这条线的工程价值越来越显现,但门槛也越来越高。DVD-JEPA 反过来走,把架构的本质压到最小。从产品意义上讲,它不会有任何下游用途;但从「让更多人真正搞懂 JEPA 在做什么」的角度,它的价值可能比任何一个 7B 复现都大。
几个值得追问的问题
看完作者的 demo 我有几个直接的疑问,也是这个项目接下来值得扩展的方向:
1. 当物理变得不可预测,潜空间会怎么变?
现在的 DVD logo 是确定性的——给定状态,下一帧唯一确定。这意味着 JEPA 的「丢弃不可预测信息」的能力其实没有被真正测试。如果给 logo 加上随机扰动(比如每帧速度有小幅高斯噪声),encoder 是否还能保持稳定?理论上 JEPA 应该会自动忽略噪声的精确数值,只保留「大致方向」。这是一个可以非常干净地验证 LeCun 那句口号的实验。
2. 32 维是不是过度参数化?
这个世界的真实自由度只有 4。如果把潜空间压到 4 维、6 维、8 维,模型还能学吗?什么时候开始崩?这种「信息瓶颈」实验在大模型里几乎没法做,但在 DVD-JEPA 上是一行代码的事。
3. Predictor 学到的是不是物理?
这是最有意思的问题。如果你把 predictor 单独抽出来,迭代地运行 N 步,看潜空间轨迹是否和真实物理保持一致——这就是「世界模型」的真正考验。如果潜空间里 predictor 能稳定跑很多步,那么这个 32 维空间就不只是表示空间,它本身就是一个学到的物理引擎。
一个开源项目的真正姿势
现在 AI 圈大部分「开源」其实是「释出权重」。代码经常是残缺的,数据准备脚本不全,训练超参不公开,复现率惨不忍睹。DVD-JEPA 走的是另一条路——fully-reproducible,作者在 README 里强调你可以从零跑完整个 pipeline,包括数据生成(毕竟 DVD logo 是程序生成的)、训练、评测。这个姿态本身就值得欣赏。
这种「教学级开源」对开发者的价值,可能比再多一个 7B 模型要高。你想搞清楚 LeCun 那套世界模型理论到底有没有戏,与其去读 100 页论文,不如花一个下午把 DVD-JEPA 跑一遍,把 EMA momentum 从 0.99 改到 0.5 看看会发生什么。这是「直觉」长出来的地方。
给开发者的一句话
如果你在做 RL、做机器人、做任何形式的视频理解,JEPA 这条线值得严肃跟一下。它和主流 LLM 路线在哲学上是分叉的:LLM 押注「预测下一个 token 足够通向 AGI」,JEPA 押注「世界的本质是表示而不是数据」。两条路线现在都没分出胜负。但在物理世界相关的任务里,JEPA 的归纳偏置(inductive bias)明显更对。
DVD-JEPA 不会让你直接做出什么产品,但它会让你对「世界模型」这四个字祛魅。在 2026 年这个所有人都在喊 world model 的时间点,能有一个 16×16 的玩具把核心机制讲清楚,是难得的清流。
参考来源
- DVD-JEPA: an open-source, fully-reproducible JEPA world model (Reddit r/MachineLearning) — 项目原帖,作者对架构、实验设置和线性 probe 结果的完整说明
- Meta 世界模型 V-JEPA 2:自监督视频模型实现理解、预测与规划(知乎) — V-JEPA 2 的中文解读,可以对照看大模型版本的工程取舍


