OpenAI 让 GPT 偷师你的工作流,Skills 进入自动生成时代

OpenAI 把 Skills 从手写 prompt 推进到"观察即生成":ChatGPT 看着你怎么干活,自动打包成可复用的技能。这是 Agent 工程化路线上的一次关键跃迁。
这一次,GPT 自己学会了"抄你的作业"
6 月这两天 OpenAI 又往 ChatGPT 里塞了点新东西,外界关注度一般,但开发者社区已经先炸了:Skills(技能)模块开始进入"观察—生成"模式。简单说,你不用再手写一段 Markdown 告诉 ChatGPT"遇到这类任务请这样做",而是把它挂在一边,让它看你怎么干完一遍活,它自己把流程抽象成一个可复用、可分享的 Skill。
这是去年底那波 Skills for Codex 之后,OpenAI 在 Agent 工程化这条路上踩下的第二脚油门。代号 Hazelnut(榛果)的功能链路被一些开发者扒了出来,OpenAI Help Center 的中文文档也悄悄更新了 Skills 的 Beta 说明,覆盖 Business、Enterprise、Edu、Teachers 和 Healthcare 五条线,Codex 和 API 同步支持。
看起来是个小更新,实际上是 prompt 时代向 skill 时代的过渡信号。
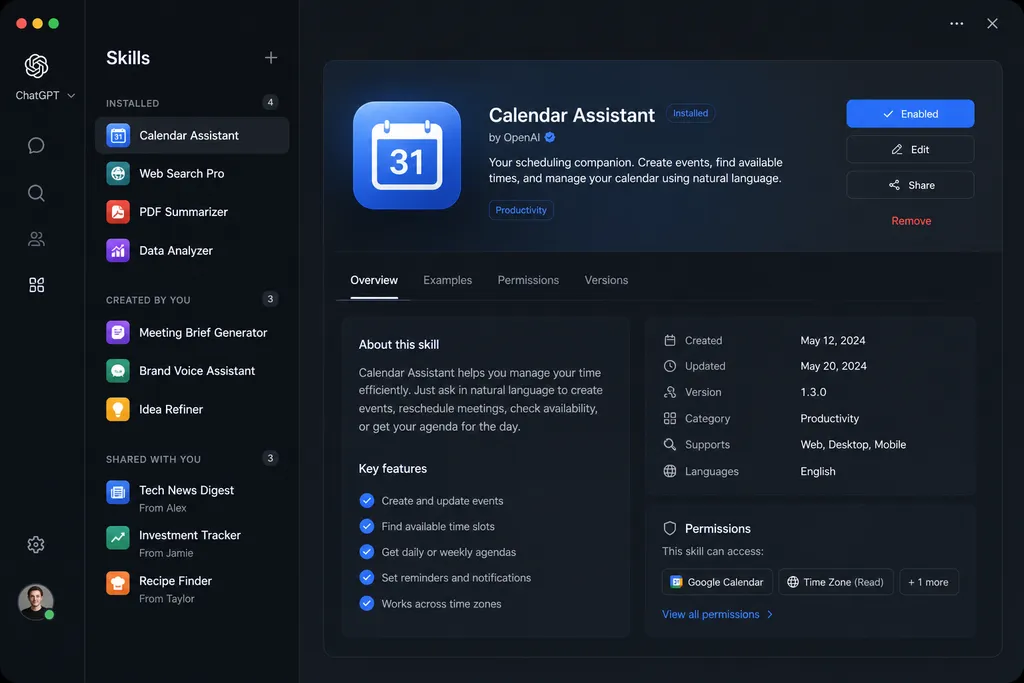
Skill 到底是什么,别再和 MCP、Sub-Agent 搅在一起
这套术语这半年快被玩烂了,先把账算清楚。
- Skill:可复用的工作流程包,本质是"指令 + 示例 + 代码/资源"的组合。你可以理解为给模型写的一份 SOP,告诉它"这种活按这个套路来"。
- Sub-Agent:模型的多实例分身,用来把一个大任务拆给几个"工人"并行干。
- MCP:Model Context Protocol,是模型连接外部系统的插座,让它能读 Linear 的 ticket、改 GitHub 的 PR。
用做菜打比方:Skill 是菜谱,Sub-Agent 是后厨多请的两个帮工,MCP 是煤气和冰箱。三者解决的根本不是一个层级的问题,但凑在一起才能跑出像样的 Agent。
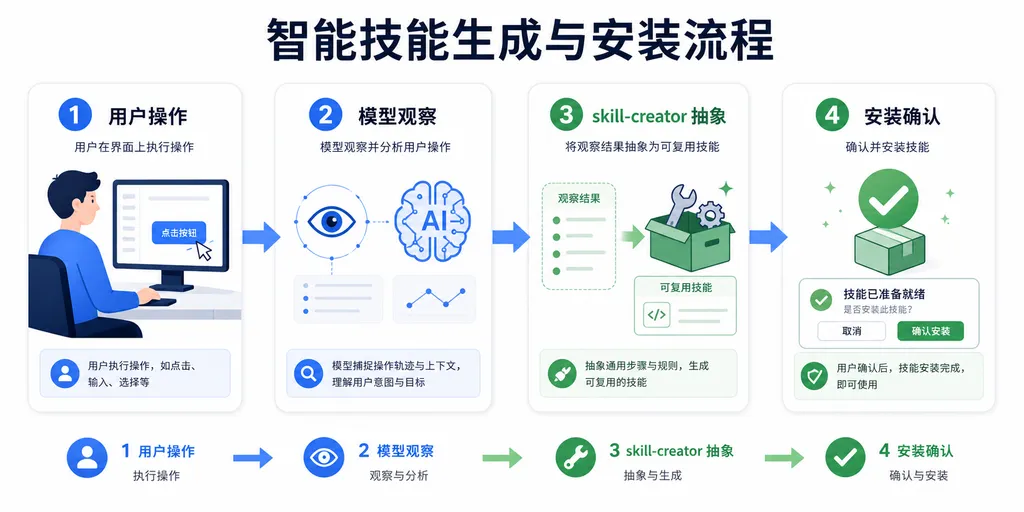
OpenAI 这次升级的核心是菜谱怎么写。以前你得自己坐下来一条条敲,新模式里 ChatGPT 在你完成一次任务后,会主动问一句"要不要把刚才这套流程存成 Skill?"——然后它用内置的 skill-creator 这个元 skill,把对话里那些隐含的判断、调用顺序、文件结构全部抽出来,生成一份你可以直接安装的技能包。
为什么这件事值得多看两眼
prompt 工程的最大痛点不是写不出,是写不一致、传不出去、复用不掉。
团队里十个人有十种 prompt 风格,同一个生成报告的活,A 用一段两千字的咒语,B 用三句白话,C 干脆每次现编。结果就是"模型表现不稳定"——其实模型挺稳定,是你们的输入不稳定。
Skill 的设计思路是把 prompt 工程从"个人手艺"变成"团队工程资产":
- 可版本化:Skill 本质是文件,能 review、能 diff、能回滚。
- 可分享:通过工作区共享,团队里所有人都用同一份"标准答案"。
- 可自动调用:装好之后,ChatGPT 判断当前任务和某个 Skill 匹配,会自动套用,不用你每次手动
@。 - 跨产品迁移:Skills 遵循 Agent Skills 开放标准,理论上 ChatGPT 里建好的 Skill 可以下载下来塞进 Codex 或 API 里跑。
而"观察工作流自动生成"这一步,把这套体系的最后一道门槛拆了——以前你得是个有 prompt 工程经验的人才能产出高质量 Skill,现在普通业务用户干完一次活,系统帮你打包。
这是 Anthropic 那边 Claude Projects、Skills 一直在做的方向,OpenAI 这一波属于补课加超车。
实际能干什么:从 CI 修 bug 到 ticket 流转
开发者社区已经晒出了几类典型用例:
- GitHub CI 自动修复:观察你过去几次怎么定位、修复 CI 错误,生成一个 "CI Doctor" Skill。下次红了,它直接照着流程跑——拉日志、定位、改配置、提 PR。
- Linear/Jira ticket 流转:把 ticket 状态变更、补充信息、关联 PR 的那套 SOP 固化成 Skill,配合 MCP 调用,基本不用人盯。
- 代码审查模板:团队的 review checklist 做成 Skill,每次 PR 进来自动按这套规则过一遍。
- 报告生成:财务、运营周报这种结构化输出,Skill 能保证每次产出格式都一致,避免模型"自由发挥"。
注意一个细节:Skill 可以包含代码。这意味着它不只是文本指令,而是可执行的工作流单元。这把它和传统意义上的 prompt 拉开了一个身位——更像"可被模型调度的轻量函数"。
Beta 的几个坑,必须先说
别看官方文档写得漂亮,现阶段 Skills 有几个明确的硬伤:
- 跨产品不同步:文档里白纸黑字写着 "Skills 尚未在各产品间同步"。ChatGPT 里建好的 Skill 想搬到 Codex,得手动下载再上传。开放标准是个好事,但用户体验上还差一截。
- Enterprise/Edu 默认关闭:管理员得显式开权限,这是出于安全考虑,但也意味着大公司推进会慢。
- 上传 Skill 的安全审查:OpenAI 会扫描上传内容,可疑的标 "Needs Review",高风险的直接 "Blocked"。但官方明确表态"扫描不能替代你自己的判断"——换句话说,出了事自己担。
- 个人 Plus/Pro 用户暂时无缘:目前还是企业/教育/医疗这几条线在测,散户开发者只能看 Codex 和 API 那边的版本。
第三方上传 Skill 这件事尤其要警惕。它能携带代码,意味着供应链攻击的口子已经开了——一个伪装成"自动化部署助手"的 Skill 里塞段恶意脚本,团队成员一安装就可能被打穿。社区已经有人在讨论要不要搞个"Skill 审计工具",类似 npm audit。
和 Anthropic、Google 比,OpenAI 这一手算什么水位
横向看一眼:
- Anthropic 早就在 Claude 里推 Projects + Skills 组合拳,Agent Skills 的开放标准本来就是他们带头搞的。
- Google Gemini Gems 走的是"自定义助手"路子,更偏个人用,工程化味道淡。
- OpenAI 这次的特别之处在于自动生成——观察工作流抽象 Skill,这一步别家还没有以这种产品化的形式释出。
但 OpenAI 的劣势也很明显:开放标准是别人定的,自己跑得反而要兼容。这种姿势在历史上不太常见,能看出 OpenAI 在 Agent 互操作性上的态度有所软化——毕竟没人想再造一个孤岛。
更深一层看,Skills 实际上是在为 Agent Marketplace 铺路。当 Skill 足够标准化、可分发、可计费,下一步就是把它做成市场——开发者写 Skill,企业付费安装,平台抽成。这套商业模式在 GPTs 上已经试过一次,效果一般,但 Skills 因为是工程化资产、面向 B 端,故事可能比 GPTs 更好讲。
给开发者的几个实操建议
如果你手头有企业账号能摸到这个功能,几条经验:
- 不要一次性把整个工作流塞给它生成。Skill 越大越难维护,把任务切成原子级的小流程,每个生成一个 Skill,组合调用。
- 重视 examples。Skill 里附带的示例对模型的影响远大于纯指令,挑两三个有代表性的真实案例放进去。
- 代码部分尽量幂等。Skill 自动调用意味着可能在你不知道的时候触发,写代码时假定它会被反复执行。
- 建立 Skill review 流程。团队共享前过一遍人工 review,至少看一眼里面有没有写死的 token、内部地址、奇怪的依赖。
另外多嘴一句,OpenAI Hub(openai-hub.com)这边目前对 Skills 相关的 API 调用是直接兼容的,国内开发者想本地起个环境测一下 Skill 在 API 模式下怎么跑,一个 Key 就能搞定 GPT、Claude、Gemini、DeepSeek 这些主流模型,省去翻墙和多平台配置的麻烦。
写在最后
2024 年大家在卷模型能力,2025 年在卷 Agent,2026 年这个上半年,重头戏已经转向"Agent 怎么工程化"——怎么让 Agent 的能力可复制、可分享、可治理。
Skill 是这条路上的一块关键拼图。它不性感,没有发布会,没有 benchmark 数字,但每个团队真正用 AI 提效的时候,都会撞上"prompt 资产化"这个坎。OpenAI 用"观察生成"这一手,让这道坎的门槛降到了普通业务人员也能跨过去。
模型层的军备竞赛已经进入边际递减区间,工程层的竞争才刚开始。这场仗,Skills 只是第一枪。
参考来源
- OpenAI开启GPT观察你的工作流程并自动生成skill的新模式 - linux.do — 国内开发者社区对该功能的最早讨论帖,包含实际截图与体验反馈


