谷歌把 Gemma 4 12B 塞进 Mac:本地多模态终于像样了

谷歌正式把 AI Edge Gallery 带上 macOS,同步发布 120 亿参数的 Gemma 4 12B 多模态模型,16GB 内存的 MacBook 就能跑起来。配套还上线了离线听写应用 Eloquent。
谷歌这次没开发布会,悄悄把 AI Edge Gallery 推上了 macOS。6 月 3 日,这个原本只在 Android 和 iOS 上存在的本地模型运行器,终于补齐了桌面端的最后一块拼图。一起发布的还有它的当家新模型 Gemma 4 12B,以及一个叫 Eloquent 的本地听写应用。
这套组合拳的指向很明确:把端侧 AI 从「能跑」推到「能用」。过去两年大家都在卷云端千亿参数,本地模型一直处于一种「玩具」状态——7B、9B 跑起来勉强,让它真去干活就露怯。Gemma 4 12B 是谷歌第一次正面回应这个问题。
这次不是又一个 Ollama
先把定位说清楚。AI Edge Gallery 不是来抢 Ollama 和 LM Studio 饭碗的,至少现在不是。
Ollama 和 LM Studio 的优势是开放——Hugging Face 上几千个模型,只要硬件兼容你都能装。AI Edge Gallery 反过来,目前只支持谷歌自家的 5 个模型,全部是 instruction-tuned 版本。
这听上去像个减分项,但谷歌的逻辑是另一套:不追求「什么都能跑」,而是「跑得最好的那个」。Gemma 系列在自家工具链里做了深度优化,配合 LiteRT-LM 运行时,理论上比通用平台调度自家模型要省内存、快一截。这跟苹果做 Core ML 是一个思路——闭环换性能。
对开发者来说,结论也很简单:想折腾各种开源模型,继续用 Ollama;想要一个开箱即用、稳定跑 Gemma 的桌面端,装这个。两者不冲突。
Gemma 4 12B:谷歌的「能用」拐点
真正的主角是 Gemma 4 12B。
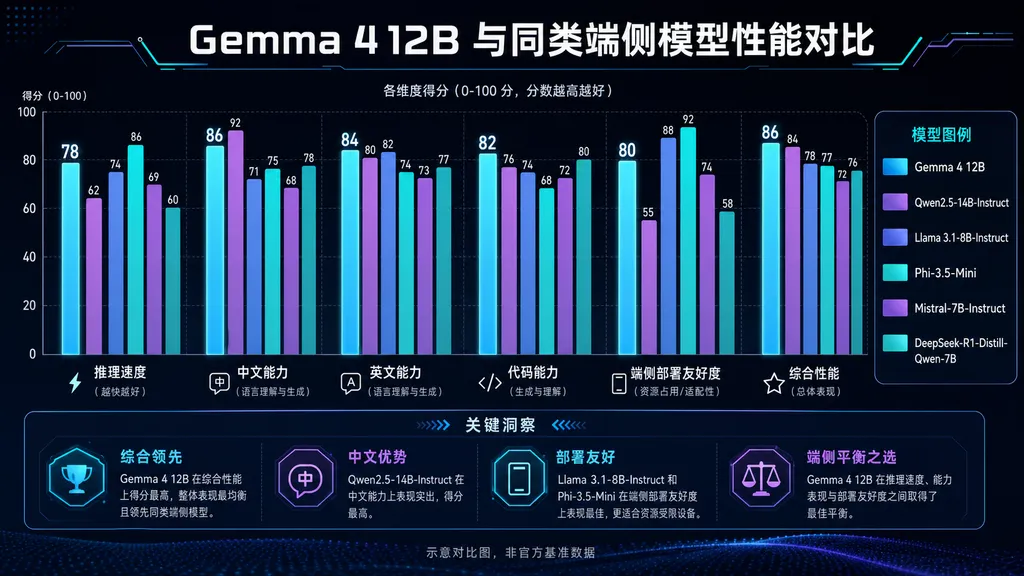
按谷歌自己的说法,这个 120 亿参数的稠密模型,性能对标他们 260 亿参数的 MoE 版本。这话听着像营销,但如果属实,意味着同等任务下,端侧模型的能力天花板被实质性抬高了一档。
几个关键参数:
- 参数量:12B(稠密)
- 硬件门槛:16GB 内存的消费级笔记本
- 模态支持:文本、视觉、音频
- 定位:agentic + multimodal,对标本地编程和数据分析场景
16GB 这个数字是有讲究的。当前主流 MacBook Air 标配从 16GB 起步,M 系列芯片的统一内存架构对大模型推理特别友好——显存即内存,不用来回搬数据。换句话说,这个模型不是给开发机准备的,是给「普通用户的笔记本」准备的。
多模态这块更值得说。过去端侧多模态基本是阉割版,要么只支持图片不支持音频,要么处理速度慢到没法用。Gemma 4 12B 直接打包了三种模态,而且谷歌的官方博客原话是「直接在设备上从数据中提取有价值的洞察」——这句话翻译过来就是:他们想让本地模型干 RAG 和数据分析的活。
端侧 AI 的三个老问题,这次能解决多少
本地模型的三大卖点没变:离线可用、性能跟硬件成正比、数据不出本地。但过去两年这三点反复被提及,进展并不快。这次谷歌的发布,实际推进了哪些?
**第一是隐私。**这一点本来就没争议,本地就是本地。但 Eloquent 这个听写应用把场景做实了——把语音转录、口头禅清理、文风润色全放在本地,对企业用户、法律和医疗从业者来说,这是一个能直接落地的需求。云端听写应用过去几年一直有合规疑虑,本地化是唯一解。
**第二是性能。**Apple Silicon 是这场游戏的最大变量。M3、M4 的 NPU 和统一内存让 12B 模型在普通笔记本上跑起来不再是奢望。配合谷歌的 LiteRT-LM 运行时,首 token 延迟和生成速度据说能逼近一些 7B 的云端调用体验。当然这要等实测。
**第三是能力。**这是过去最大的短板。Gemma 4 12B 如果真能达到 260 亿 MoE 的水平,端侧第一次有了可以认真用来写代码、做分析的模型。不再是「玩玩看」。
Eloquent:被低估的那个发布
比起 Gemma 4 12B 的高调,Eloquent 像是顺手发的,但它可能是这次最有产品感的东西。
核心功能就一句话:本地实时听写 + 文本润色。但细节做得很有想法——
- 自动去除「嗯」「啊」「那个」这类口头禅
- 轻度编辑,让口语化表达变得清晰
- 支持多种写作风格切换
- 自定义词库,避免专有名词被改错
最后一点尤其关键。任何用过苹果原生听写的人都知道,输入「LangChain」「Anthropic」这类词基本是灾难,每次都得手动改。Eloquent 让用户自己加词典,等于把这个长期痛点直接解决了。
这个产品对市面上一票听写 SaaS 是降维打击。Otter、Rev 这些云端服务的核心价值就是转录质量和编辑功能,现在谷歌把它免费、本地、隐私安全地打包送出去了。
谷歌的端侧战略浮出水面
把这几个发布拼起来看,谷歌在端侧 AI 上的路线图越来越清楚:
- 模型层:Gemma 系列持续迭代,每代把可用门槛降一档(3B → 9B → 12B,性能等价于云端更大的模型)
- 运行时:LiteRT-LM 统一调度,跨平台(Android/iOS/macOS)
- 应用层:AI Edge Gallery 当展示橱窗,Eloquent 做杀手级应用示范
- 开发者生态:Hugging Face 上的 litert-community 仓库开放模型权重
这个组合的对手不是 OpenAI 或 Anthropic,是苹果的 Apple Intelligence。苹果用自家小模型 + 私有云推理在做闭环,谷歌则用开源 Gemma + 本地运行时做开放生态。在 macOS 这块苹果的主场,谷歌反而比苹果更早把「12B 多模态本地跑」这件事做出来了,挺有意思。
开发者该不该跟进
几个建议:
- 如果你在做本地 AI 应用,Gemma 4 12B 值得测一下。120 亿参数 + 多模态 + 16GB 门槛,这个组合在当前开源模型里没有直接对手。
- 如果你已经在用 Ollama 跑 Llama 3 或者 Qwen,没必要立刻切换,但可以装一个 AI Edge Gallery 对比下推理速度。谷歌的运行时优化大概率比通用方案快。
- Eloquent 直接装,免费,对写作和会议记录场景有实打实的提升。
- 如果你做的是 agentic 工作流,谷歌官方博客明确把 Gemma 4 12B 定位成 agentic 模型,function calling 和工具调用能力是重点优化方向。这块可以重点测。
开源模型这边,Gemma 4 12B 的权重已经在 Hugging Face 上放出。如果你想接入云端调用做混合架构,OpenAI Hub 这类聚合平台也支持 Gemma 系列的调用,配合本地版本可以做云端兜底、端侧优先的部署策略。
一个还没回答的问题
谷歌没说的是:为什么 AI Edge Gallery 在 Mac 上只开放自家模型?
技术上说,LiteRT-LM 完全可以跑其他开源模型。但谷歌选择闭口。一种猜测是先把自家体验做扎实,再逐步开放;另一种猜测是要把 Gallery 做成 Gemma 的官方 launcher,用来对抗 Ollama 这种「中立」平台。
不管哪种,对开发者来说现在的选择都不复杂:要灵活性选 Ollama,要谷歌官方调优选 AI Edge Gallery,两个都装也没问题。
端侧 AI 这件事,到 2026 年中终于不再是「未来很性感,现在很拉胯」的状态了。Gemma 4 12B 和 AI Edge Gallery 是一个明确的信号:在 16GB 内存的笔记本上跑多模态大模型,已经从 demo 进化到了生产力。
参考来源
- litert-community/gemma-4-12B-it-litert-lm · Hugging Face - Gemma 4 12B 官方模型卡与硬件规格说明


