minFLUX发布:把FLUX扒到最小,让你真正看懂扩散模型

开发者Saurabh Purohit开源了minFLUX项目,用极简PyTorch代码重写了FLUX.1和FLUX.2的核心架构,每一行都对应diffusers源码,让啃不动官方库的研究者有了一条捷径。
diffusers太重,有人忍不下去了
如果你最近在啃 FLUX 的源码,大概率有过这种经历:在 diffusers 仓库里点开一个 FluxTransformer2DModel,然后被七八层的 Mixin、Config、PipelineCallback、PEFT 包装绕到怀疑人生——明明只想看一眼 transformer block 里 modulation 是怎么算的,却得先翻完三个文件的继承链。
6月19日,一位叫 Saurabh Purohit 的开发者在 r/MachineLearning 上贴出了自己的解决方案:minFLUX,一个去掉所有抽象、只保留核心架构和数学的 FLUX 精简实现。项目已在 GitHub 开源,定位非常明确——不是给你拿去训生产模型的,是给你拿去读的。
这事的逻辑跟当年 Karpathy 写 minGPT 一脉相承。HuggingFace 的库做得很全,工程上无可挑剔,但对想理解模型本身的人来说,封装层就是噪音。minFLUX 干的就是把噪音剥掉,把 FLUX.1 和 FLUX.2 的骨架摊在你面前。
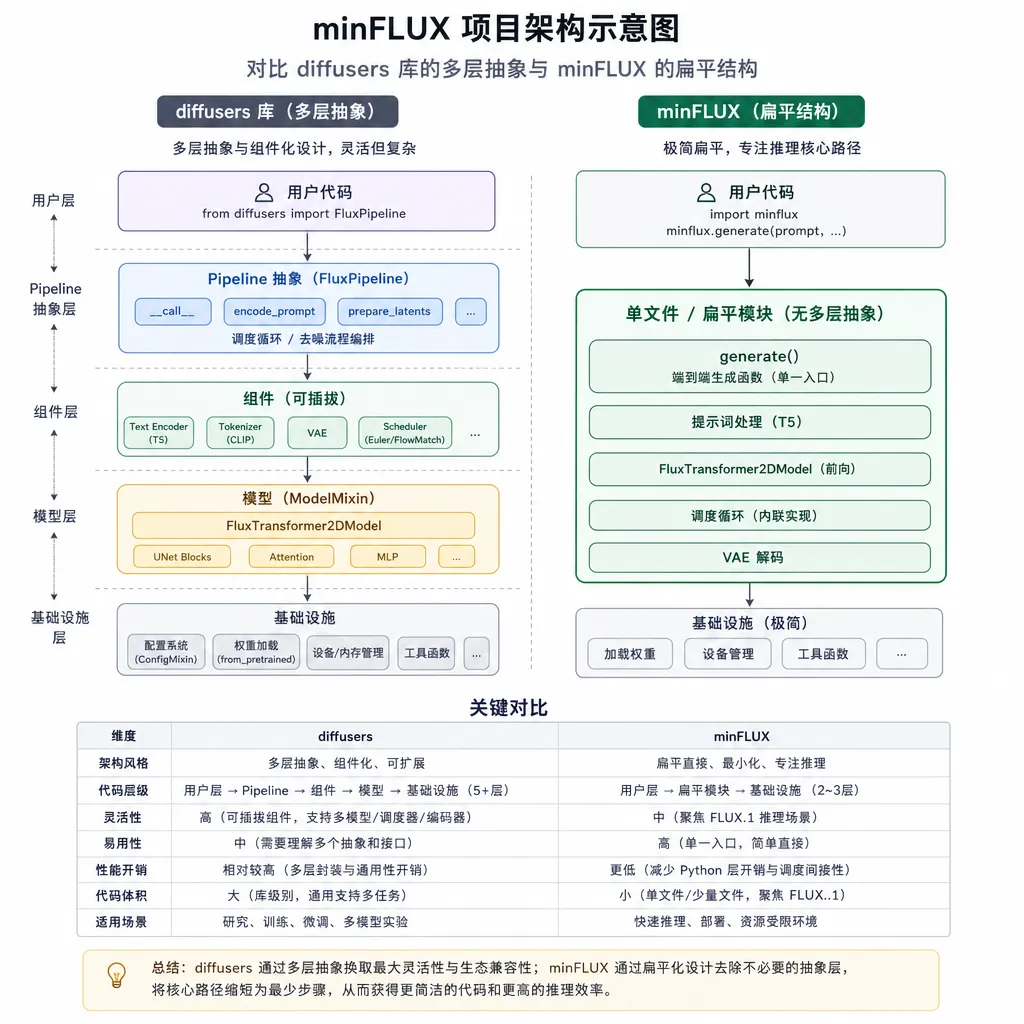
它到底装了什么
按作者的 README,minFLUX 提供的东西其实非常克制:
- FLUX.1 + FLUX.2 的最小可运行实现,包含 VAE 和 transformer 主干
- 每一行代码都标注了 HuggingFace diffusers 的对应位置——这点是 minFLUX 最值钱的地方,你可以一边读简化版,一边对照官方实现的复杂版
- 训练循环:VAE encode → flow matching → velocity MSE
- 推理循环:noise → Euler ODE → VAE decode
- 共享工具模块:RoPE 位置编码、timestep embedding 等
注意这里完全没有 LoRA 适配器、没有 ControlNet 接口、没有各种 scheduler 的可插拔切换,连 attention 的 backend 选择都砍掉了。这种做法在生产环境是灾难,但在学习场景就是奢侈品——你不用在脑子里维护一堆 if/else 分支。
flow matching:FLUX 系列的训练范式
minFLUX 里最值得读的部分,其实是训练和推理这一对循环。FLUX 不走 DDPM 那一套噪声预测,而是用 flow matching——直接学习一个从噪声到数据的速度场(velocity field),损失函数就是预测速度和真实速度的 MSE。
用通俗的话讲,传统扩散模型像是教模型"猜这张图被加了多少噪声",flow matching 则是教它"在这一时刻,像素应该朝哪个方向流动"。两者数学上有等价关系,但 flow matching 的训练更稳定,推理时也可以直接用 ODE 求解器(比如 Euler 法)一步步把噪声推回图像,不需要复杂的 DDIM 调度。
在 minFLUX 里,这套流程被压缩成几十行代码就能跑通。对于做生成模型研究的人,这种"看一遍就懂"的实现价值非常高——比啃 paper 里的公式直观得多。
FLUX.2 不是简单的放大版
作者在帖子里特别强调了一个发现:FLUX.2 并不是 FLUX.1 的等比例放大。在动手把两个版本都重写一遍之后,他列出了 FLUX.2 的几处真正改动:
- Transformer block 结构调整
- Modulation 机制重做
- FFN 层改了
- VAE 归一化方式不同
- Position IDs 的处理逻辑也变了
这跟去年 11 月 Black Forest Labs 发布 FLUX.2 时官方那句"全新架构,从零预训练"是对得上的——只是当时大家从外部很难判断"全新"到底新在哪。minFLUX 的并排实现等于做了一次代码级 diff,把营销话术翻译成了具体的工程改动。
如果你之前基于 FLUX.1 做过 fine-tune 或者 LoRA 训练,那些经验在 FLUX.2 上不一定能直接迁移。光是 modulation 和 position IDs 的变化,就足以让一些训练超参需要重新调。这是 minFLUX 这种项目能提供的、HuggingFace 模型卡上不会写的信息。
为什么这类"minXXX"项目总有人做
回头看一下这条线索:minGPT、nanoGPT、minLLaMA、minSDXL、minDiT,再到现在的 minFLUX——每出一个明星模型,就会有人做一个精简版。原因很简单:官方实现是为了用,精简版是为了懂。
这两件事的目标完全不同。官方代码必须考虑分布式训练、混合精度、推理后端兼容、各种社区贡献的功能拼装,最后必然臃肿。而当你想搞清楚"这个模型为什么 work"的时候,所有这些工程细节都是干扰。
对于做 AI 系统研究的人,精简版还有另一个用途:作为修改的起点。你想改 attention?想试新的位置编码?想换个 VAE?在 minFLUX 上做实验的成本,比在完整 diffusers 里小一个数量级。哪怕你最终要把改动 port 回官方库,先在精简版上验证 idea 也省时间。
适合谁、不适合谁
直说吧:
适合的人:
- 想搞懂现代扩散模型架构的研究者和学生
- 正在写自己的 diffusion 训练框架,想抄一个干净参考的工程师
- 想给 FLUX 做架构改动(不是 LoRA 那种轻改)的研究人员
- 教 AI 课程、需要把扩散模型讲透的老师
不适合的人:
- 想直接拿来推理生成图的用户——直接用 diffusers 官方 pipeline 几行就跑通了,没必要绕路
- 要做生产部署的团队——精简版没有 attention 优化、没有量化、没有调度器选择,性能远不如官方
- 想做 LoRA 微调的——生态都在 diffusers 那边,minFLUX 没必要重造
这种定位划清之后,minFLUX 的价值就很清楚了:它不是 diffusers 的替代品,是 diffusers 的注释版。
一点延伸:开源扩散生态的健康度
顺便说一句,FLUX.2 自去年发布以来,Black Forest Labs 的开源策略其实挺克制——开了 dev 版本权重,给社区留了足够大的空间去做生态。从 ComfyUI 节点到各种 LoRA、再到现在这种精简实现,FLUX 系列已经形成了相对完整的开发者社区。这和 Stable Diffusion 3 早期那种半开半闭、社区怨声载道的局面对比鲜明。
开源不只是甩个权重出来,还要让社区能读、能改、能教。minFLUX 这种项目,本质上是在替官方做"可读性补全"。如果你在 OpenAI Hub 上调用 FLUX 系列的 API 做应用,理解一下底层架构没坏处——至少在调采样步数、CFG scale 这些参数时,你会知道自己在干什么,而不是在玄学调参。
怎么上手
项目地址在 GitHub purohit10saurabh/minFLUX。建议的阅读顺序:
- 先看
flow_matching.py(训练目标) - 再看推理循环里的 Euler ODE 求解
- 然后进 transformer block,对照作者标注的 diffusers 行号一起读
- 最后看 FLUX.1 和 FLUX.2 的 diff,理解架构演进
如果你之前看 diffusers 看到一半放弃了,这次不妨再试一次——只不过这回别从 from diffusers import FluxPipeline 开始,从 minFLUX 的 README 开始。
参考来源
- minFLUX 项目主页 - GitHub:作者开源的精简版 FLUX 实现,含 FLUX.1 与 FLUX.2 双版本
- Reddit r/MachineLearning 发布讨论帖:作者首次公开项目并阐述设计动机,评论区有架构细节讨论


