The Atlantic 把 AI 音乐训练集翻出来了:2100 万首歌可搜索

The Atlantic 记者 Alex Reisner 公开了四个用于训练 AI 音乐模型的数据集,最大的一个来自 LAION,包含 1232 万首 YouTube 曲目,Google 和 Stability AI 已确认在论文中使用过其中部分数据。
2100 万首歌,被翻了个底朝天
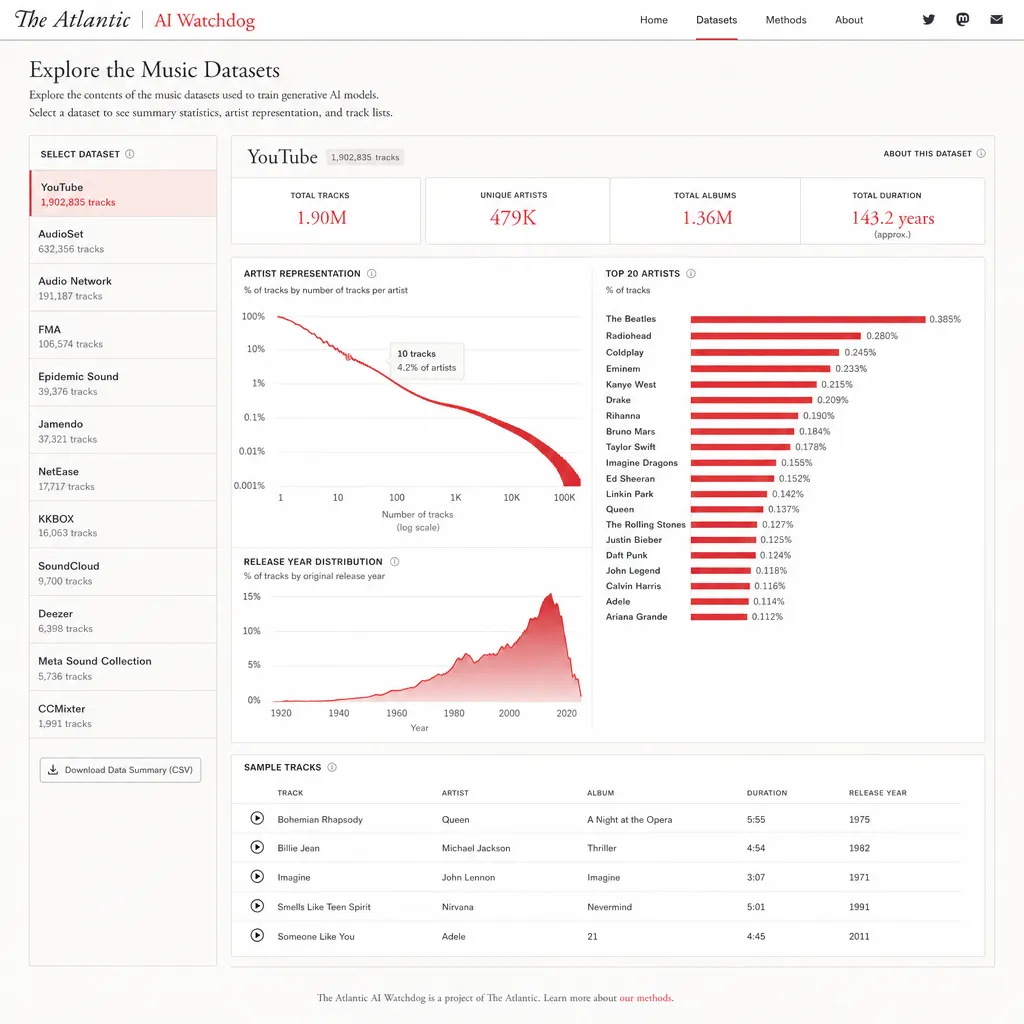
The Atlantic 上周扔出了一个 AI 音乐圈不太想看到的东西:一个可搜索的数据库,把目前在 AI 开发圈子里流传的四个音乐训练集全部摊到了公众面前。任何人都能进去查——你的某首歌在不在里面。
这件事是记者 Alex Reisner 干的。他不是第一次干这种事,之前 The Atlantic 的 AI Watchdog 系列已经把 LibGen 那批被用来训练大模型的盗版书库给挖出来过一次,搞得 Meta 那边一度很难看。这次轮到了音乐。
四个数据集加起来,规模相当夸张:
- LAION-DISCO-12M:1232 万首 YouTube 抓取的曲目,总时长 91 年
- 一个未公开命名的大型集合:约 900 万首
- Spotify Tracks Dataset:11.4 万首从 Spotify 扒下来的曲目,Hugging Face 上传者匿名,截至 2026 年 5 月被下载超过 7 万次
- Free Music Archive Dataset (FMA):10.6574 万首,由洛桑联邦理工 EPFL 在 2016 年整理
听起来 FMA 那种规模没什么——但别忘了 Stability AI 用了它的 1.3874 万首子集训过模型,Google 也在论文里承认用过。这不是"灰色地带",是已经公开承认的事实。
这些数据是怎么来的?合规吗?
四个集合的合规性参差不齐,但没一个干净。
LAION-DISCO-12M 来自德国非营利组织 LAION——这名字你应该不陌生,Stable Diffusion 训练用的 LAION-5B 图文对就是他们搞的。LAION 拿过 Hugging Face 的钱,也拿过 Stability AI 前 CEO Emad Mostaque 的钱。1232 万首歌怎么来的?YouTube 抓的。YouTube 服务条款明确禁止未授权下载,但学术数据集这套打法在 AI 圈子里已经是默认操作了。
FMA 数据集比较"体面"一点,里面大部分是 Creative Commons 协议授权的曲目——但 CC 协议里有个细节很多人故意忽略:大多数 CC 授权要求署名,并禁止商业用途。AI 模型训练算不算"商业用途"?训练出来的模型卖钱算不算?这个问题至今没有判例。但 Google 和 Stability 这种公司用,怎么看都难说不是商业用途。
Spotify Tracks Dataset 是最离谱的。Spotify 自己跟这个数据集毫无关系,是一个匿名开发者把 11.4 万首歌从 Spotify 平台"扒"下来扔到 Hugging Face 上的。下载量 7 万次。Hugging Face 的内容审核机制在这种问题上基本是后置的——只有被点名才会下架。
剩下那个 900 万首的集合,The Atlantic 没披露更多细节,估计是怕侵权诉讼。但能想到,来路大概率也不光彩。
为什么是现在曝出来?
时间点很关键。
Suno、Udio 这两家 AI 音乐生成公司已经被 RIAA(美国唱片业协会)告了一年多了。诉讼的核心争议就是:训练数据从哪来的?Suno 之前的回应是"训练数据是商业秘密",Udio 直接承认用了"开放网络上的公开音乐"——但拒绝具体说哪些。
Reisner 这次做的事,本质上是把这些公司不愿意承认的事实做了一次"佐证"。哪怕 Suno 和 Udio 没有直接用这四个数据集,业界对训练数据来源的态度也已经路人皆知了。
更微妙的是,The Atlantic 的报道里点了几个具体例子:Suno 生成的曲子和 Michael Jackson 的《Thriller》、Ed Sheeran 的《Shape of You》、Chuck Berry 的《Johnny B. Goode》高度相似——这不是"风格借鉴",是模型记忆(memorization)问题。AI 系统在训练数据里见过的东西,会以片段形式吐出来。这是技术问题,也是法律问题。
Spotify 自己今年早些时候清掉了 7500 万首"垃圾" AI 生成歌曲,Sony 发现旗下艺人名下挂了 13.5 万首他们没做过的 AI 曲子。整个音乐行业现在面对的是双重困境:自己被拿去训练,训练出的模型又来污染自己的渠道。
一个可搜索数据库意味着什么
技术上看,The Atlantic 做的这个工具不复杂——元数据索引 + 搜索接口,本质上就是把 Hugging Face 上散落的 dataset card 整合后做了个前端。但它的杀伤力在于降低了维权门槛。
以前一个独立音乐人想知道自己的歌有没有被拿去训练,得自己去翻 Hugging Face 的 dataset README,下载几十 GB 的元数据文件,写脚本去 grep。现在直接在网页里输入歌名就行。
这意味着接下来几个月:
- 集体诉讼的素材库被打包好了。律师事务所只需要做的就是组织音乐人去查询、截图、形成证据链
- 数据集分发会转入地下。Hugging Face 这种公开平台上的音乐数据集八成会被批量下架,但 BT、IPFS 上的分发不会停
- "数据来源透明度"会变成 AI 音乐产品的强制标签。Suno、Udio 不交代清楚训练数据,进不了主流分销渠道
对开发者来说,这件事的另一个层面是数据集治理。LAION 是一个非营利组织,但它做的事情实质上是给商业公司提供"白手套"——把法律风险高的数据收集环节外包给非营利组织,公司只需要"使用公开数据集",看起来一切合规。这套打法在文生图领域已经被打穿了一次(Getty Images 诉 Stability AI),现在轮到音乐了。
给 AI 工程师的启示
如果你现在正在做或者打算做生成式音频的模型,这件事至少提醒你三点:
第一,数据合规要前置。靠 LAION 这种第三方数据集训练的时代结束了,至少在音频和视觉领域。Adobe Firefly 那种"全部来自授权素材"的路线虽然慢、虽然贵,但是法律风险最低。Sony Music 已经和几家 AI 公司在谈授权合作,价格会很贵,但是合规。
第二,模型记忆问题要在评估阶段就处理。Suno 现在最大的麻烦不是"用了哪些数据",而是"输出的内容能被反向匹配到训练样本"。这是技术问题,不是法律问题——通过更好的去重、数据增强、训练目标设计,可以显著降低记忆程度。这一关迟早每家音频生成公司都得过。
第三,元数据和归属系统要从一开始就考虑进去。C2PA 那套内容溯源标准在图像领域开始普及,音频领域类似的方案也在推进。早做兼容,比后面被强制要求改要划算得多。
平台和工具的反应
Hugging Face 截至发稿没有公开回应是否会下架这几个数据集。从过去的处理惯例看,Spotify Tracks Dataset 这种明显侵权的会先下,LAION-DISCO-12M 这种由"研究机构"上传的可能会保留但加警告标签。
Google 在它的研究论文里承认用过 FMA 数据集训练生成模型,但 Google 一直走"研究用途" + "模型不直接商业化"的口径。Stability AI 那边比较尴尬,公司本身已经经历了一轮重组,前 CEO Emad Mostaque 离职后的法律遗产怎么处理,新管理层还没明确表态。
国内的 AI 音乐产品,比如做歌词生成、伴奏生成的几家,目前还在政策灰色地带。但参考国内对生成式 AI 训练数据的监管思路(《生成式人工智能服务管理暂行办法》明确要求训练数据合法来源),国内监管收紧的时间窗口可能比海外更紧。
写在最后
这件事不是孤立事件。从 LibGen 书库被曝出来,到 Common Crawl 里的版权内容争议,到现在的音乐数据集,AI 训练数据这条产业链的每一个环节都在被掀开来看。
开发者社区里有种声音:"如果训练数据全部要授权,AI 就发展不起来了"。这话半对半错。文本和图像领域已经证明了,授权数据 + 合成数据的组合可以训出有竞争力的模型,只是更贵、更慢。音乐领域大概率也会走类似的路。
顺带一提,OpenAI Hub(openai-hub.com)这边主流的多模态和音频生成模型都有接入,国内开发者可以直接用 OpenAI 兼容格式去调,省去合规自建的麻烦——但训练数据这件事还得各家自己面对。
短期内,AI 音乐生成的格局可能会重新洗牌。Suno、Udio 这种激进派要么搞定授权,要么准备好赔大钱。稳妥派比如 Adobe、Stability(如果还能撑住)则有机会借合规化拿回市场。对整个行业来说,这次曝光与其说是危机,不如说是迟早要出的清算。
参考来源
- Hugging Face Datasets 平台 — 涉事数据集 Spotify Tracks Dataset、LAION-DISCO-12M 的托管平台,本次事件的核心分发渠道
- LAION 在 Hugging Face 的组织主页 — LAION 团队公开的音视频数据集集中地,可查看 DISCO 系列数据集元数据


