SILX AI 甩出 Quasar-Preview:18B MoE 死磕 500 万上下文

SILX AI 开源了 Quasar 基础模型系列首个公开检查点 Quasar-Preview,18B 稀疏 MoE 架构、2B 激活参数,实验性支持 500 万 token 上下文,混合循环/注意力层设计直指未来长记忆系统。
SILX AI 把 5M 上下文这件事,放到了 18B MoE 上
6 月初,一家叫 SILX AI 的团队悄悄在 Hugging Face 上挂出了 Quasar-Preview——Quasar 基础模型系列的首个公开检查点。参数规模 18B,MoE 架构,单 token 推理激活路径只有约 2B,听上去是个标准的小型 MoE。但真正让这次发布出圈的,是模型卡上那个数字:5,000,000 tokens 的上下文窗口。
是的,500 万 token。不是 200K、不是 1M,是 5M。
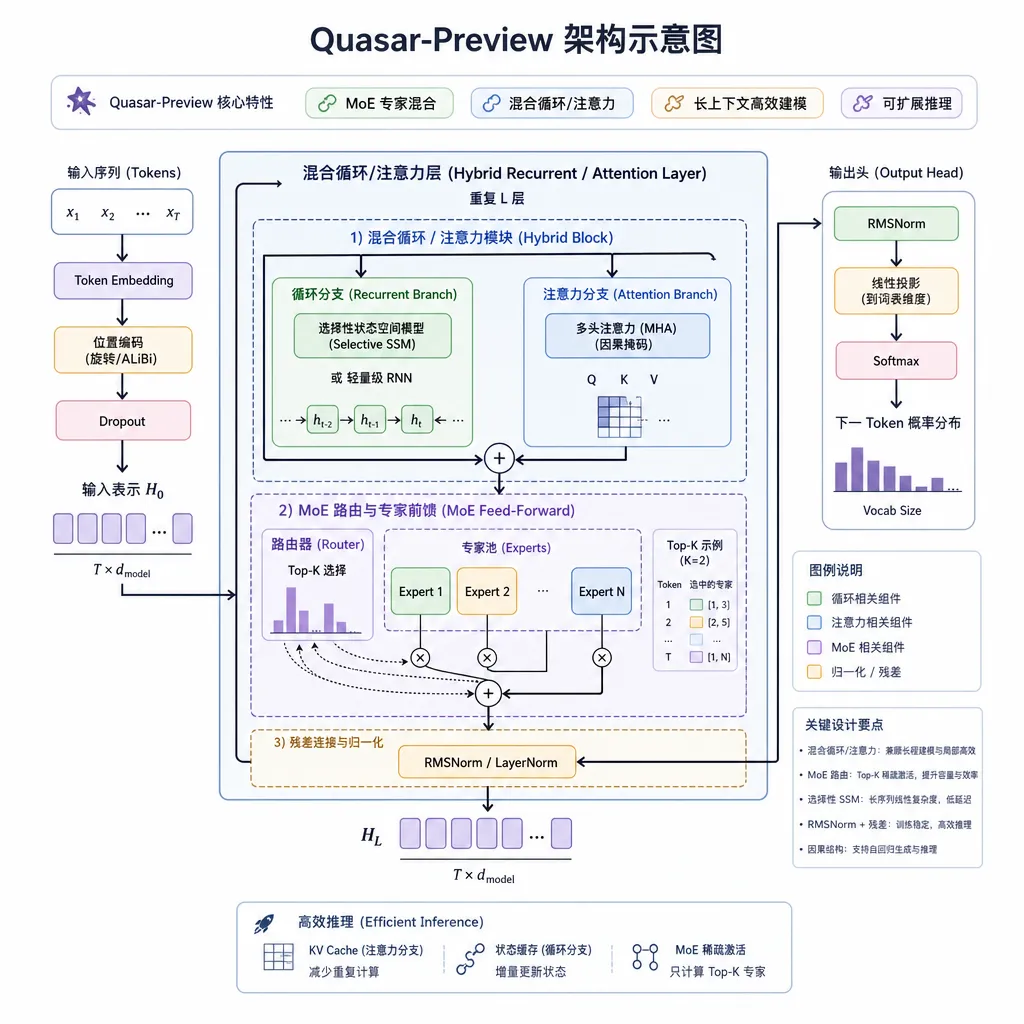
按照模型卡的说法,Quasar-Preview 并不是最终成品,而是「架构预览 + 基础检查点」。SILX AI 把这次发布定义成 Quasar 路线图的第一步——证明这套 sparse MoE + 混合循环/注意力层 + 实验性长上下文的组合,在真实规模下能跑起来、能训得动,后续会在 Bittensor SN24 上通过去中心化训练、蒸馏、架构改进继续推进。
这种「我先把架构端出来给社区看,能用但别指望它打榜」的发布姿态,其实挺少见的。在 GPT-5、Claude 4.5、Gemini 3 全都卷向多模态推理的当下,有人愿意回头死磕长上下文的底层架构,本身就值得说几句。
18B 里只激活 2B:MoE 的算账逻辑
先聊参数。Quasar-Preview 的设定是 ~18B 总参数,~2B 激活参数,激活比大约 1:9。和 Mixtral 8×7B(47B 总 / 13B 激活)、DeepSeek-V3(671B 总 / 37B 激活)这些已经被市场反复验证的 MoE 比起来,Quasar-Preview 的稀疏度更高,单次推理的算力占用更接近一个 2B 的稠密模型。
这个配比有它的现实考量:
- 激活路径小 = 推理便宜。2B 激活参数意味着单 token 的 FLOPs 接近 Qwen2.5-1.5B 量级,单卡 24GB 显存(启用量化后)就能跑起来。
- 总参数 18B = 知识容量够用。这个尺寸足够装下基础语言能力和通用知识,不至于像 1-3B 稠密模型那样在常识题上翻车。
- MoE 路由本身就是长上下文的天然搭档。专家分工可以让模型在处理超长序列时只激活相关专家,避免全参数参与的算力爆炸。
换句话说,这是一个为长上下文优化的 MoE 形态,而不是为了刷榜单堆参数的 MoE。
混合循环/注意力层:Transformer 不再独大
真正有意思的是架构层面。Quasar-Preview 用的是 hybrid recurrent/attention layers——把循环结构(类似 RWKV、Mamba 那一脉的状态空间/线性注意力)和传统注意力层交替堆叠。模型卡里提到这是基于 Loop 架构构建的。
这件事的背景是,纯 Transformer 在长上下文上有个绕不开的硬伤:KV cache 随序列长度线性膨胀,注意力计算随平方膨胀。当你想把窗口从 128K 推到 1M、5M,单纯靠堆显存和 FlashAttention 优化已经救不回来了。
业界这两年的解法分两条路:
- 稀疏注意力 / 分块注意力:Gemini 1.5 那套,本质上还是注意力机制,靠工程优化撑场面。
- 线性注意力 / SSM:Mamba、RWKV、Jamba 这一脉,用 O(n) 复杂度的循环机制替代部分注意力。
Quasar-Preview 走的是第二条路的混合版——既保留注意力层的精确召回能力,又用循环层把长程依赖的算力压下来。这种「Hybrid」思路其实和 AI21 的 Jamba、Nvidia 的 Hymba 是同一个家族,但 Quasar 把规模和上下文长度都推到了一个更激进的位置。
Safe NoPE / DrOPE:长上下文的位置编码新解
模型卡里还提到一个细节:Quasar-Preview 采用 Safe NoPE / DrOPE 风格的阶段性长上下文扩展方法。
位置编码这件事,在长上下文场景里是个老大难。RoPE 在外推时会衰减、ALiBi 在精确召回上会丢分、YaRN/NTK-aware 这些插值方法本质都是事后补救。NoPE(No Positional Encoding)这两年被一些研究证明在足够大规模下反而能学到隐式位置信息,但稳定性是个问题——所以才有「Safe NoPE」的说法。
DrOPE 则更偏向于在训练时通过随机 drop 一部分位置信号,让模型学会在缺失位置编码的情况下也能保持一致性。SILX 把这套组合包装成阶段性扩展:先在短上下文上稳定训练,再分阶段把窗口推到 5M。
说实话,5M 这个数字本身的实用性是要打问号的——目前没有任何下游评测能真正验证 5M token 的有效信息利用率(needle in a haystack 测到 1M 都已经很勉强了)。但 SILX 自己也承认这是「为未来基于内存的系统设计」的实验性配置,更像是给后续的记忆增强、Agent 长程任务铺路。
怎么把它跑起来
Quasar-Preview 已经在 Hugging Face 开源(silx-ai/Quasar-Preview),支持 Transformers、vLLM、SGLang 和 Docker Model Runner 几种部署方式。因为用了自定义架构代码,加载时需要带上 trust_remote_code=True:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "silx-ai/Quasar-Preview"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
prompt = "Explain hybrid recurrent-attention layers in one paragraph."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=256)
print(tokenizer.decode(output[0], skip_special_tokens=True))
硬件方面,官方建议至少 24GB 显存起步(bf16 + 2B 激活路径),如果要跑接近 5M 的窗口,KV cache + 循环层状态会吃掉大量显存,需要 80GB 级别的卡或者多卡切分。实测在 A100 80GB 上跑 256K-512K 上下文是比较舒服的区间,再往上就需要 vLLM + 分页注意力来抗。
生产部署推荐用 vLLM,启动命令大致是:
vllm serve silx-ai/Quasar-Preview \
--trust-remote-code \
--dtype bfloat16 \
--max-model-len 524288 \
--gpu-memory-utilization 0.92
注意 max-model-len 别一上来就拉到 5M,先从 256K-512K 跑通再说,否则 KV cache 预分配会直接 OOM。
Bittensor SN24 与去中心化训练
这次发布另一个不太显眼但值得提的细节是:Quasar 系列后续的训练会继续在 Bittensor SN24 子网上推进。
对不太熟悉 Bittensor 的开发者解释一下——它是一个基于代币激励的去中心化机器学习网络,SN24(Subnet 24)专门跑长上下文与记忆相关的研究任务。SILX AI 把 Quasar 放在 SN24 上继续训练,意味着后续的模型迭代会借助分布式算力贡献者完成,而不是走传统的「自建集群闭门炼丹」路线。
这种模式过去更多见于 Hivemind、Petals 这类研究项目,能跑到 18B MoE 规模并产出可用 checkpoint 的还不多见。如果 Quasar 系列能在 SN24 上跑通完整的训练-蒸馏-评估闭环,对去中心化训练这个领域算是一个不小的样本。
当然,去中心化训练有它自己的代价:通信成本高、节点异质性大、梯度同步策略复杂。SILX 把 MoE + 循环架构作为切入点,应该也是看中了 MoE 在分布式场景下的天然亲和性——专家可以按节点切分,循环层的状态传递比全注意力的 KV 同步开销小得多。
横向看一眼:Quasar 卡在哪个生态位
把 Quasar-Preview 放到 2026 年的开源模型版图里看,它的定位其实挺微妙:
- 比拼通用能力,它打不过 Qwen3、DeepSeek-V4、Llama 4 这些主流稠密/MoE。
- 比拼极致小尺寸,它也不如 Gemma 3、Phi-5 这种 1-4B 的精修模型。
- 比拼长上下文,5M 的窗口是噱头大于实用,但 256K-1M 这个区间确实能用上 hybrid 架构的优势。
- 比拼架构新颖性 + 开放程度,这是 Quasar 的真正卖点——一个真正可下载、可微调、可继续训练的 hybrid MoE 检查点,社区可以拿它当 Mamba+MoE 实验的起点。
所以这个模型对谁有价值?
- 做架构研究的人:你想验证混合循环/注意力 + MoE 在 10B+ 规模下的行为,Quasar-Preview 是目前少数能直接下载的样本。
- 做长上下文应用的团队:哪怕你只用到 256K 窗口,hybrid 架构在推理速度和显存占用上也比纯 Transformer 友好。
- 关注去中心化训练的开发者:Bittensor SN24 上的后续进展值得跟。
至于普通的应用开发者,老老实实用 GPT、Claude、Gemini 或者 DeepSeek 通过 OpenAI Hub 这类聚合平台调用就行了——Quasar-Preview 这种「预览版基础模型」本质是研究素材,不是生产工具。
一些保留意见
最后说点不那么客气的。
5M 上下文窗口这个数字,我个人持谨慎乐观态度。Hybrid 架构在理论上能支撑超长序列,但真实信息利用率才是关键。我们见过太多模型卡上写着「支持 1M 上下文」,实际在 100K 之后召回率就崩了的案例。SILX AI 目前没有公布完整的长上下文 benchmark(RULER、LongBench、NIAH 等),只能等社区第三方测试。
另外,「首个公开检查点」+「架构预览」的定位,也意味着这个模型在指令跟随、对话能力、安全对齐上几乎是零优化状态。直接拿去做 Chat 应用大概率体验拉垮。它更适合作为继续预训练 / SFT 的起点。
Quasar-Preview 的真正价值,要等 Quasar 系列后续模型——尤其是 Instruct 版本——出来后才能盖棺定论。但作为一个明确表态「我们要在 hybrid 架构 + 长上下文这条路上走到底」的信号,它已经够清晰了。
参考来源
- silx-ai/Quasar-Preview · Hugging Face — 模型官方发布页,包含完整的架构说明、使用方法和路线图
- SILX AI 正式发布 Quasar-Preview · linux.do — 中文社区对发布的整理与讨论,包含 Safe NoPE / DrOPE 等技术细节解读


