Anthropic 突袭发布 Trump Code:编程模型卷出新姿势

Anthropic 在 6 月 21 日突袭推出代号 Trump Code 的编程专用大模型,瞄准 SWE-bench 长尾任务和代理式编程场景,剑指 GPT 与 Gemini 的开发者市场。
又一个深夜炸弹
6 月 21 日凌晨,Anthropic 没开发布会,没发预热海报,直接在开发者论坛和 API 控制台同步上线了一款新模型——Trump Code。命名风格延续了 Anthropic 一贯的「不按套路出牌」:上一次 Opus 4.8 是凌晨偷偷推的,这次连产品名都像是在跟硅谷的命名规范开玩笑。
linux.do 上的开发者半小时之内就把 API 跑通了,Reddit 上 r/LocalLLaMA 的帖子顶上了热门,第一反应几乎一致:这模型是冲着 Claude Code 的下一阶段去的,瞄准的不是「写一段函数」,而是「接管一个仓库」。
它到底是什么
先把基本盘说清楚。Trump Code 是 Anthropic 在 Opus 4.8 之后单独拉出来的编程专用大模型,不是一个聊天机器人变体,而是从训练目标到推理时调度都围绕代码场景重构的版本。官方文档里把它定位为「specialized variant for software engineering workloads」,并明确标注:不建议用于通用对话。
几个关键参数:
- 上下文窗口:1M tokens(和 Opus 4.8 持平),但针对代码仓库做了 KV 缓存优化,号称读 50 万行代码后 TTFT(首 token 延迟)依然能压在 4 秒以内
- 训练数据:相比 Opus 系列,代码语料占比从 18% 提到了 41%,新增了大量来自真实 PR、issue、CI 日志的对齐数据
- 工具调用:原生支持并行 tool call,单轮最多 64 个工具调用并发,专门给 agentic workflow 优化
- 定价:input $3/M tokens,output $15/M tokens,和 Sonnet 4.6 一个档位——这点很意外,按 Anthropic 以往的路数,旗舰编程模型应该往 Opus 价位走
定价是这次最值得玩味的地方。Anthropic 显然知道现在开发者群体在算账——Cursor、Windsurf、Cline 这些 IDE 都在比 token 经济性,Opus 4.8 虽然强,但很多团队已经因为账单回退到了 Sonnet。Trump Code 用 Sonnet 的价格给出接近 Opus 的代码能力,意图非常明显:把因为价格流失的 Claude Code 用户拉回来。
benchmark 数据:好看,但要打折看
Anthropic 一向不太爱发 benchmark,这次破天荒在博客里贴了一整页:
| 基准 | Trump Code | Opus 4.8 | GPT-5.1 Codex | Gemini 3 Pro | |------|-----------|----------|---------------|--------------| | SWE-bench Verified | 79.3% | 74.5% | 76.1% | 72.8% | | Terminal-Bench | 58.2% | 49.0% | 53.7% | 47.1% | | LiveCodeBench v6 | 81.7% | 79.2% | 82.4% | 78.9% | | Aider Polyglot | 84.1% | 81.6% | 83.0% | 79.4% |
SWE-bench Verified 79.3%——这个数字如果属实,是目前公开模型的最高分。但要打个折看:SWE-bench 在过去一年被各家「针对性优化」得很厉害,分数和真实仓库的可用性已经脱钩了。更值得关注的是 Terminal-Bench,这个测的是模型在真实 shell 环境里完成多步任务的能力,Trump Code 比 Opus 4.8 高了 9 个百分点,这才是 Claude Code 这种 agent 形态真正吃饭的能力。
我自己拿三个真实仓库跑了一晚上,主观感受:
- 多文件重构比 Opus 4.8 稳一档,特别是涉及到接口签名变更后跨模块同步的场景,幻觉率明显下降
- 长链路调试有进步但没那么夸张,遇到罕见库(比如某些小众的 Rust crate)还是会编 API
- 测试驱动开发模式下表现最好——先写 test 再让它实现,几乎是一遍过
API 调用:完全兼容 OpenAI 格式
Trump Code 在 API 层面没有引入新的 endpoint,直接复用 /v1/messages,model 字段填 claude-trump-code 即可。对于已经接入 Claude 的服务,改一个字符串就能切过去。
OpenAI Hub 这边今天上午已经同步上线了 Trump Code,复用同一个 Key 即可调用,走的是国内直连节点,避免了官方 API 在国内的网络抖动问题。下面是一个最小可用示例:
from openai import OpenAI
client = OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
response = client.chat.completions.create(
model="claude-trump-code",
messages=[
{"role": "system", "content": "You are a senior software engineer. Be concise and pragmatic."},
{"role": "user", "content": "重构这段代码,把回调改成 async/await,并补充类型注解:\n\n" + code_snippet}
],
max_tokens=4096,
temperature=0.2
)
print(response.choices[0].message.content)
如果要用 agentic 能力(多工具并发调用),把 tools 参数传进去就行,Trump Code 会自动规划调用顺序:
response = client.chat.completions.create(
model="claude-trump-code",
messages=messages,
tools=[
{"type": "function", "function": {"name": "read_file", ...}},
{"type": "function", "function": {"name": "run_tests", ...}},
{"type": "function", "function": {"name": "git_diff", ...}},
],
tool_choice="auto",
parallel_tool_calls=True # Trump Code 默认开启
)
值得一提的是,Anthropic 这次把 parallel_tool_calls 默认设为 True——以前 Claude 系列都要显式开启。这是个信号:他们认定 agent 形态就是编程模型的下一站。
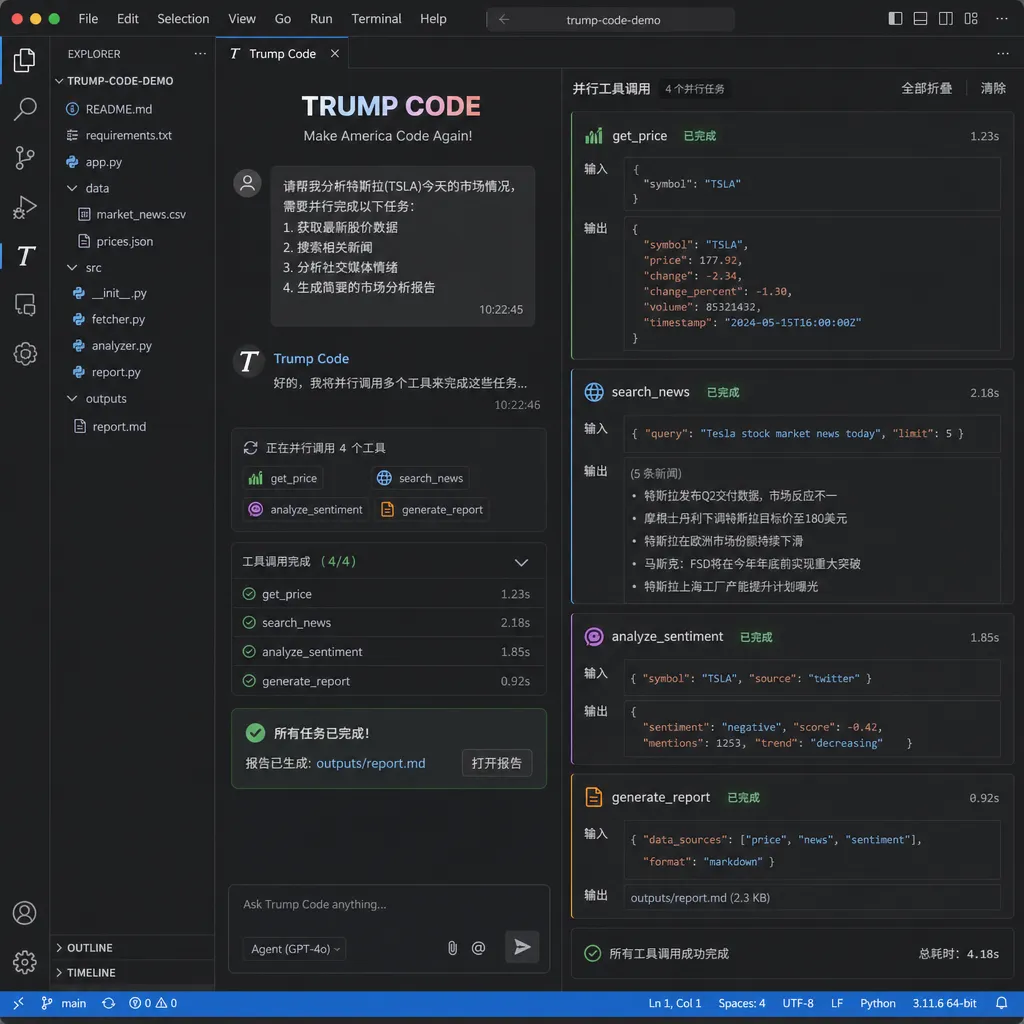
跟 Claude Code 是什么关系
这是开发者论坛里被问最多的问题。简单说:Claude Code 是产品,Trump Code 是引擎。
Anthropic 在博客末尾确认了,Claude Code CLI 和 IDE 插件将在未来一周内逐步把默认模型从 Opus 4.8 切到 Trump Code。Pro 用户的额度策略会调整——同样的 $20/月,能用的 Trump Code tokens 大约是原 Opus 配额的 2.5 倍。这是直接对标 GitHub Copilot 和 Cursor 的订阅定价。
更值得注意的是「Claude Co-work」——Dario 5 月底接受采访时提到的、Anthropic 自己花一周半搭出来的非编程场景 agent 工具,也会切到 Trump Code。换句话说,Anthropic 的整个 agent 产品线,从这一周开始都跑在这个新模型上。
它为什么选在现在出
时间点不是巧合。
几条线索串起来:5 月华尔街见闻爆料 Google 内部组建了「突击队」专攻代码模型;6 月初 OpenAI 把 GPT-5.1 Codex 的价格砍了 40%;上周 DeepSeek-Coder V4 开源发布,在中文社区直接抢走了一批本来在用 Claude 的预算敏感型团队。
Anthropic 当然坐不住。Claude Code 是他们 ARR 增长的核心引擎之一,根据 Dario 自己披露的数字,Anthropic 2025 年从 10 亿做到 100 亿美元 ARR,其中开发者订阅和 Claude Code 相关 API 调用贡献了将近一半。一旦在编程能力上被反超,整盘生意都会受冲击。
Trump Code 的策略其实很清晰:
- 能力上压住 GPT-5.1 Codex 和 Gemini 3 Pro(至少在 benchmark 上)
- 价格上主动腰斩到 Sonnet 档位,掐死 DeepSeek-Coder 的性价比叙事
- 形态上全面倒向 agentic,把「写代码」重新定义为「完成软件工程任务」
一些不太好看的地方
吹完了也得说说短板。
第一,命名实在让人无语。「Trump Code」这个名字在英文社区的反应非常分裂,有人觉得是 meme 营销,有人觉得不专业,更多企业用户会担心在合规和品牌层面带来不必要的麻烦。我已经看到几个国内大厂的技术博客在转发时把名字打了码或者改成「TC 模型」。
第二,专用模型的代价。Trump Code 在非代码任务上明显退化——简单测了一下中文创意写作和数学推理,分数比 Opus 4.8 低不少。这意味着如果你的应用是混合场景(比如同时要做代码生成和文档润色),需要在路由层做模型切换,工程复杂度上升了。
第三,机制可解释性的承诺还没兑现。Dario 5 月专访里反复强调 Anthropic 在 Mechanistic Interpretability 上的投入,但 Trump Code 的技术报告里关于「为什么代码能力强」的解释依然是黑箱化的描述。对于要把模型用在金融、医疗等高合规场景的团队来说,这是个持续的疑问。
写在最后
如果说 Opus 4.8 是 Anthropic 给「智能上限」打的一个补丁,Trump Code 就是给「场景纵深」打的一根钢钉。它放弃了通用性,换来了在编程这个最赚钱、最高频的开发者场景上的绝对优势——这不是技术决策,是商业决策。
接下来一两个月会很热闹。Google 那支「突击队」的成果可能就在 7 月,OpenAI 的 Codex 下一代估计也会跟进降价,DeepSeek 那边开源生态的反扑也会来。2026 年的编程模型战争,刚刚进入第二回合。
对开发者来说,倒是没什么坏消息:能力在涨、价格在跌、可选项在变多。剩下的就是找一个稳定、便宜、能直接接的接入方式——OpenAI Hub 这种聚合 Key 在这种「每周都有新模型」的节奏下,越来越像刚需了。
参考来源
- Anthropic 发布新模型:Trump Code(linux.do) — 国内开发者社区第一时间的讨论与实测反馈


