WeightsLab 大改版:训练跑一半能暂停,专治CV工程师的数据脏病

开源工具 WeightsLab 推出数据中心化调试功能,支持训练中暂停、实时观察 loss 信号、定位错标和离群样本,PyTorch 原生,面向图像、视频、LiDAR 点云场景的 CV 团队。
别再 debug 模型了,问题大概率在数据里
这事发生在本周——GrayboxTech 团队把开源项目 WeightsLab 做了一次大改版,在 Reddit 的 r/MachineLearning 板块挂出来。卖点很直白:训练跑到一半可以暂停,进去看 live loss 信号,把错标、类别不平衡、离群点这些数据问题先揪出来,再决定要不要继续烧 GPU。
对每一个调过 CV 模型的工程师来说,这个场景太熟了:花了三天 debug 模型结构、学习率、优化器,最后发现是标注那边把猫标成了狗,或者某个 batch 里塞进了一堆分辨率诡异的脏数据。WeightsLab 这次革新瞄准的就是这个痛点——把调试的重心从「模型代码」搬到「数据本身」。
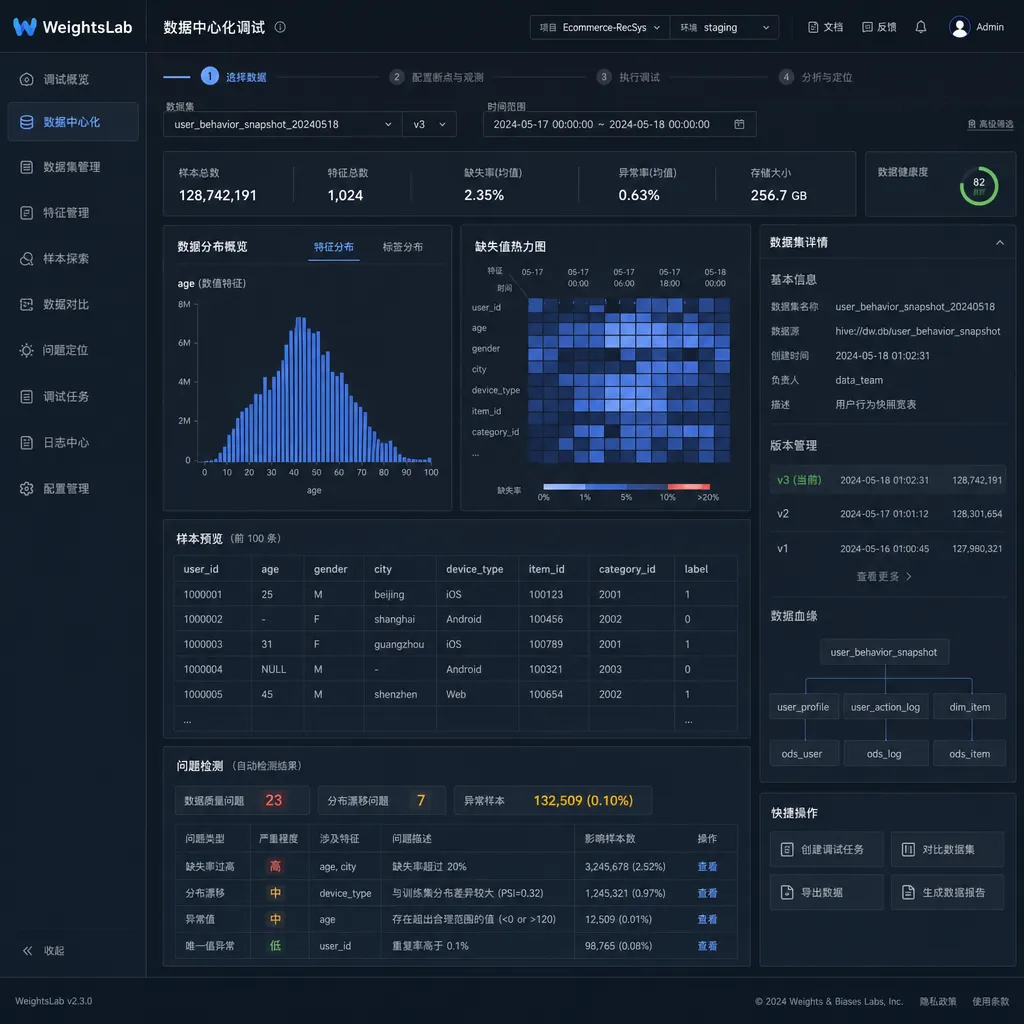
这是个什么东西
先把定位说清楚。WeightsLab 不是又一个 TensorBoard 替代品,也不是 W&B 的国产平替。它把自己定义为「面向团队的数据中心化训练调试器」(data-centric debugging for teams training neural nets),核心思路是把 Andrew Ng 这几年一直在喊的 data-centric AI 落到具体工具上。
几个关键属性:
- 开源,仓库在 GitHub 上公开
- PyTorch 原生,不需要换框架,不需要包一层奇怪的 wrapper
- 面向 CV 工程师,主打图像、视频以及 LiDAR 点云三类数据
- 支持团队协作,不是单机版的本地工具
它干的事情可以拆成三步:训练中暂停 → 实时检视 loss 信号 → 在样本粒度上定位问题。听着简单,但你真把它和现有工具链对比一下,会发现这个组合其实没人做好过。
为什么「暂停训练」是个被低估的能力
现在主流的训练监控方案,本质都是事后看 log。TensorBoard 看曲线,W&B 看指标,MLflow 看实验记录——它们都是「观察者」,不是「介入者」。出了问题,你只能等这轮训练跑完,回头分析 checkpoint,重启实验。一个 8 卡 H100 的训练任务,跑废一轮可能就是几千美金。
WeightsLab 的玩法不一样。它允许你在训练过程中按下暂停,进到当前 step 的状态里,去看哪些样本的 loss 异常高、哪些类别的梯度方向跟其他差得离谱、哪些 batch 里混进了视觉上明显的离群图像。看完之后,你可以选择:
- 把这些样本标记出来,从数据集中剔除
- 修改标签,继续训练
- 调整采样策略,让某些少数类多被看到几次
- 直接终止,回去清洗数据
这套交互逻辑,更像是 Jupyter Notebook 风格的「随时介入」,而不是传统训练脚本的「一跑到底」。对于动辄几天的训练任务,能在第三个 epoch 就发现「哦原来是数据集里 7% 的样本被错标了」,省下的不只是时间,是真金白银。
live loss 信号怎么用
这里面比较有意思的是 live loss signals 这个概念。
传统的 loss 监控,看的是聚合后的标量:每个 batch 的平均 loss,每个 epoch 的训练/验证 loss 曲线。这种粒度只能告诉你「整体训练顺不顺利」,告诉不了你「哪个具体样本在拖后腿」。
WeightsLab 把 loss 信号下沉到了样本级别。你能看到的不再是一条曲线,而是一张样本 × loss 的热力图——哪些图片在训练中始终是 high-loss 区域,基本就锁定了三类问题:
- 标注错误:模型怎么学都学不会,因为标注本身就是错的
- 天然困难样本:边缘案例,比如严重遮挡、极端光照
- 离群样本:根本不该在这个数据集里的图,比如分辨率异常、内容跑题
这三类问题的处理方式完全不同。错标要修,困难样本要保留甚至加权,离群样本要剔除。但在传统监控里它们都长成一根 loss 曲线,分不出来。WeightsLab 把样本身份带回到可视化里,这是个挺务实的设计。
为什么主打 CV,而且把 LiDAR 单拎出来
这次改版明确写了支持 images、videos、LiDAR point cloud。LiDAR 点云这条线是个信号——他们要打的不是泛泛的 ML 工程师,而是自动驾驶、机器人、3D 感知这一拨人。
这群人的数据问题最严重,原因有几个:
- 点云数据的标注成本是图像的 5-10 倍,错标率天然就高
- 多传感器融合的场景下,时间戳对不齐、外参标定漂移都会导致脏数据
- 数据量巨大,单个 scene 可能就是几 GB,靠人眼抽查根本不现实
NLP 那边现在拼的是模型规模和 RLHF,CV 这边其实早就回到了「数据为王」的状态。Tesla 那套数据闭环、Waymo 的 auto-labeling pipeline,本质都是在解决数据质量问题。WeightsLab 选择切 CV 这个口子,市场判断是对的。
跟现有工具链怎么搭
这个问题开发者最关心。现在调一个 CV 模型,标准配置大概是这样:
- 训练框架:PyTorch / PyTorch Lightning
- 监控:TensorBoard 或 Weights & Biases
- 数据管理:DVC 或者自己写的 S3 脚本
- 标注:CVAT、Label Studio、SuperAnnotate
- 数据质量:Cleanlab、FiftyOne
WeightsLab 的位置在哪?我的看法是,它最接近的对手是 FiftyOne + Cleanlab 的组合,但比这俩更进一步——它直接把调试嵌入到了训练循环里,而不是训完之后再回头审查。
# 示意的集成方式(基于公开信息推测)
from weightslab import Trainer
trainer = Trainer(model, dataset, ...)
trainer.enable_live_inspection()
trainer.fit()
# 训练运行时,打开 Web UI 即可暂停、检视、标记样本
注意这是示意,具体 API 要看仓库。但思路就是这么个思路:把检视点埋在训练循环里,而不是事后接管。
几个值得一问的问题
这工具看着挺香,但我不想直接吹。几个真实使用场景下会遇到的问题:
一、暂停训练对分布式训练友好吗? 单卡上暂停很简单,但你在 8 卡 DDP 上暂停一个进程,其他几个等多久?团队场景下多人协作检视,又怎么保证状态一致?这个工程难度不小,仓库里的实现质量要观察。
二、大数据集的可视化怎么做? ImageNet 级别 130 万张图,COCO 级别几十万张,再大点的自动驾驶数据集动辄千万样本。把所有样本的 loss 信号物化到前端,前端不卡死?
三、和 W&B / TensorBoard 共存还是替代? 这关系到工程师愿不愿意迁移。如果只是替代,迁移成本就太高了;如果能共存,作为 W&B 的补充存在,落地概率大得多。
这几个问题,Reddit 评论区目前讨论还不多,得过段时间看真实用户反馈。
数据中心化为什么现在又热起来
往回看,data-centric AI 这个词 Andrew Ng 2021 年就在喊了,当时反响一般。这两年又开始热,背景变了:
大模型时代,预训练阶段「scale is all you need」的红利已经基本吃完,下游 fine-tune 和领域适配阶段,数据质量的边际收益远高于堆参数。一个干净的 1 万样本,比一个脏的 10 万样本好用得多,这是工业界的共识。
CV 领域更明显。基础模型(SAM、DINOv3 这些)已经把通用感知能力做得很强了,工程师的工作重心从「设计更好的 backbone」转向「准备更好的 fine-tune 数据」。这种情况下,WeightsLab 这类工具的价值才真正显出来。
开源这个选择也聪明。CV 这个细分领域,封闭工具很难打——FiftyOne 也是靠开源起家的。GrayboxTech 走开源 + 团队协作付费的路线,预期是合理的。
一些务实的建议
如果你团队里有 CV 训练任务,这工具值得花半天试一下。我的判断:
- 单卡或小规模训练:直接接进来,至少在数据清洗阶段能省不少事
- 多卡 DDP 训练:先观望,等用户反馈分布式支持稳不稳定
- 生产级 pipeline:暂时别替换现有监控栈,作为补充工具评估
- 点云数据团队:优先级最高,目前同类工具里能干 LiDAR 的不多
顺便说一句,OpenAI Hub 这边主要服务的是 LLM API 调用场景,一个 Key 调通 GPT、Claude、Gemini、DeepSeek 这些主流模型,国内直连兼容 OpenAI 格式。和 WeightsLab 这种本地训练调试工具是两个层面的事——一个解决「训练模型」的痛点,一个解决「用模型」的痛点。但如果你在做 CV 训练 + LLM 后处理的混合 pipeline,这俩可以一起用。
写在最后
WeightsLab 这次改版不算革命,但是个挺好的产品判断。在所有人都在卷模型、卷参数、卷算力的时候,回头把数据这一层的工具做扎实,是个反共识但务实的选择。
开源工具能不能跑出来,最后看的还是社区。Reddit 这个帖子目前热度一般,希望更多 CV 工程师能去 issue 区提反馈,把这种数据中心化的调试工具真正打磨成行业标配。毕竟,少烧一轮训练,省下的 GPU 时间够团队加好几顿饭。
参考来源
- Data-centric debugging for teams training neural nets - Reddit - WeightsLab 改版发布原帖,附作者说明和社区讨论
- GrayboxTech/weightslab - GitHub - WeightsLab 开源仓库,PyTorch 原生数据中心化训练调试工具
- 万字长文带你读懂强化学习,去中心化强化学习又能否实现? - 知乎 - 强化学习与去中心化训练的背景阅读


