MRU更新:一个独立开发者的Attention替代方案,能跑通了

一年前在Reddit上发过的Matrix Recurrent Units(MRU)线性时间序列架构刚刚迎来更新,作者解决了此前训练不稳定的核心问题。在Kimi Linear、Qwen3-Next集体押注线性注意力的当下,这种来自社区的独立探索值得关注。
一个被翻新出来的Attention替代品
6月20日,Reddit的r/MachineLearning板块出现了一则不太显眼但挺有意思的更新:一位独立开发者重新拾起了自己一年前发布的 Matrix Recurrent Units(MRU) 项目,宣布解决了此前训练不稳定的问题,并放出了改进版的实现细节。
这事儿放在一年前可能没人在意——又一个挑战Transformer的民间方案而已。但放在2026年中这个节点上,背景就完全不一样了:从去年下半年Kimi Linear开源、到Qwen3-Next走混合线性路线、再到Minimax M2在M1的线性方案上又回退到Full Attention,整个行业对"如何摆脱O(N²)"已经从"要不要做"进入到"具体怎么做"的精细化阶段。这种时候,一个独立开发者公开自己踩坑一年的复盘,反而比大厂论文更有参考价值——因为它讲了那些不会写进paper的失败细节。
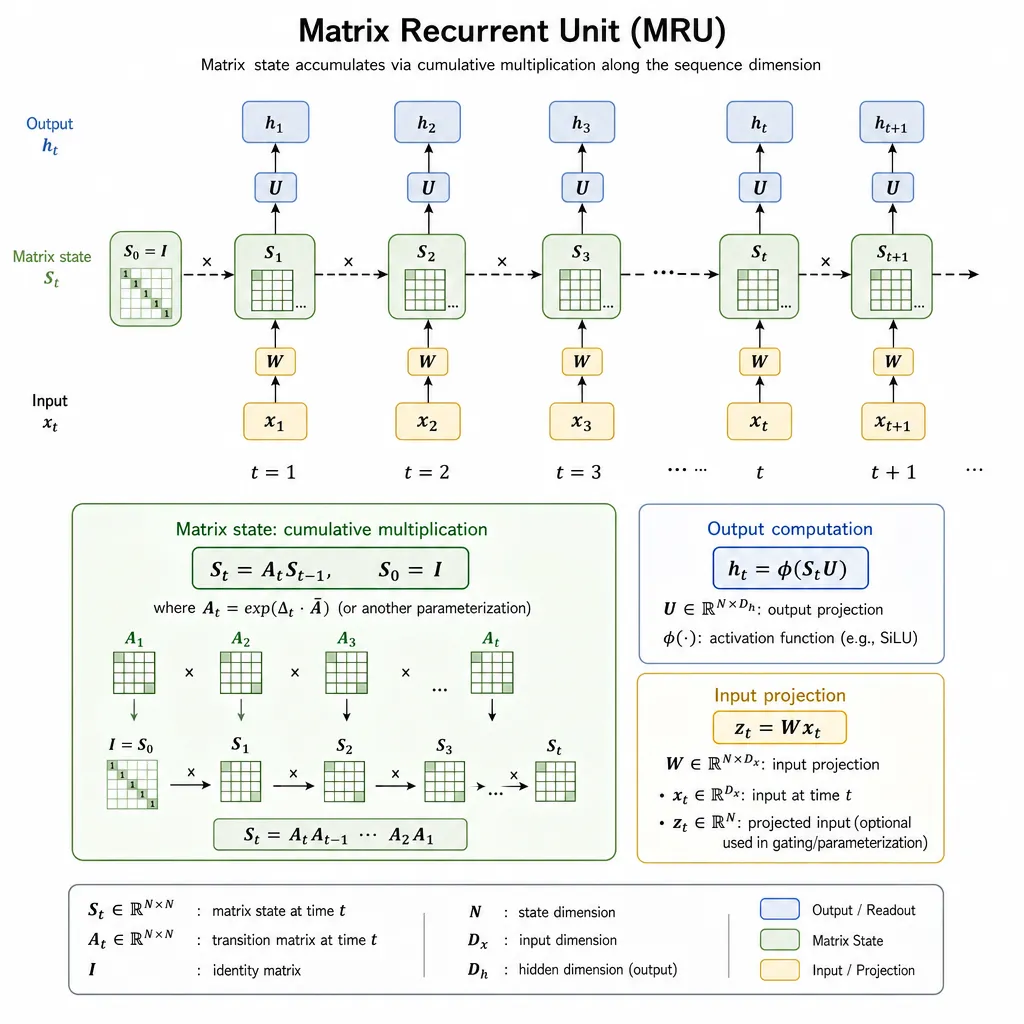
MRU到底在做什么
先把话说清楚,MRU不是什么颠覆性的全新范式。从机制上看,它其实可以归到广义的Linear RNN / Linear Attention这一脉。
核心做法只有三步:
- 升维:把每个token的embedding向量reshape或者通过某种变换,转成一个 输入状态矩阵(input state matrix)
- 累积乘:在序列维度上,把这些矩阵一个一个乘起来,得到输出状态矩阵
- 降维:再把输出状态矩阵变换回向量,作为这一步的输出
听起来挺朴素的,但有两个关键点决定了它能不能算"可用":
第一,矩阵乘法是有结合律的。也就是说 (A·B)·C == A·(B·C)。作者正是利用这一点写了一个并行扫描(parallel scan)的实现,使得MRU在GPU上不会退化成串行RNN那种灾难性的训练速度。这一点和Mamba的selective scan、以及Linear Attention系列的chunk-wise并行思路是一致的——没有parallel scan,所有RNN-like架构在现代GPU上都是死的。
第二,累积矩阵乘本质上是一个状态转移。每一步把当前的"状态矩阵"和新输入的矩阵相乘,等价于RNN里的hidden state update,只不过状态是矩阵而不是向量,转移操作是矩阵乘法而不是非线性激活。这意味着MRU的表达能力理论上比标量门控的线性注意力要强,但稳定性也更难控制——这正是作者一年前栽跟头的地方。
一年前的两个致命问题
2025年那次发布,MRU在 shakespeare-char 这种toy数据集上跑出了不错的结果,但评论区两个问题直接把它打回原形:
- 矩阵状态没有bound。累乘矩阵的特征值如果大于1,状态会指数爆炸;小于1则指数衰减到零。这是所有"矩阵累乘"架构的原罪,RWKV、Mamba、DeltaNet、Kimi的KDA都在用不同的方式解决这件事。
- 训练不稳定。当数据集换成更复杂的文本,模型就训不动了。
这两个问题其实是一回事的两面——状态不bound,梯度自然就炸。
这位作者这次更新里说,他主要的实验方向放在了 "如何构造input state matrix" 这一步。原始方案是简单reshape向量得到矩阵,这种做法没有任何对矩阵谱(spectrum)的约束。改进版尝试了不同的参数化方式,目标是让构造出来的矩阵在乘积层面天然具备某种稳定性,比如限制在某个特定的矩阵群里、或者通过结构化分解(类似DPLR这种)让累乘可控。
这种思路并不孤单
讲到这里就必须提一下最近半年学术界和工业界在做的事,因为MRU这种独立项目的价值,恰恰是因为它和主流方向"撞车"了。
Kimi Linear(月之暗面去年10月底开源)走的路子,本质上就是给Linear Attention的状态转移矩阵加细粒度结构约束。它的 Kimi Delta Attention(KDA) 引入了通道级的遗忘门控,状态更新基于改进的Delta Rule,关键的工程trick叫 Diagonal-Plus-Low-Rank(DPLR)——把状态转移矩阵拆成"对角块+低秩补丁",这样既保留了表达能力,又能在GPU上高效并行。Kimi Linear最终采用 3:1的混合层设计:每3层KDA后插1层全注意力。
根据Kimi Linear论文作者之一杨松琳在播客里的说法,3:1这个比例正在变成业内共识。Qwen3-Next也是类似的结构。原因很简单:纯线性注意力在多跳推理(multi-hop reasoning)上有天然缺陷,必须靠少量的全注意力层来兜底语义聚合。
反例是Minimax。M1版本用了Lightning Attention这种线性方案,但到了M2又退回Full Attention。为什么?播客里的解读是,线性注意力的真正竞争对手其实不是Sparse Attention(比如DeepSeek那条线),而是 Sliding-Window Attention。在公平比较的条件下,线性注意力相对滑窗的优势并不是想象中那么大,而工程复杂度却高了一截。
回过头看MRU这种"纯线性、纯矩阵累乘"的方案,它其实就处在Kimi Linear所代表的"加约束的线性注意力"和"纯Mamba式SSM"之间——而能不能活下来,关键就看作者能不能把input state matrix这一步设计好。
独立开发者做这件事的意义
这里值得多说一句。
现在这个时间点,做线性注意力研究的门槛已经被Kimi、阿里、Minimax这些团队抬得很高了。一个独立开发者拿着toy dataset去和这些工业级方案比绝对指标,没意义也不公平。但MRU这个项目的价值不在于"能不能打过Kimi Linear",而在于:
- 它把一个简单到极致的baseline完整暴露出来了。代码、踩坑过程、改进方案全在GitHub上,这种透明度是工业界论文给不了的
- 它在尝试不同的input state matrix构造方式——这一点其实和Kimi DPLR、Qwen3-Next的结构化探索是同一个问题的不同切片
- 作者用了associativity做parallel scan的实现细节,对于想理解FLA(flash-linear-attention)这类库底层逻辑的开发者来说,是个不错的入门样本
给开发者的几个观察
如果你在跟这条线的进展,下面几点可能有用:
- Linear Attention的故事已经从"能不能work"进入"怎么调得更好"。Kimi Linear是当前公平比较下首次全面超越Full Attention的方案,但前提是混合架构
- 状态转移矩阵的结构化是核心战场。无论是DPLR、Delta Rule、还是MRU这种独立项目的尝试,本质上都在回答"如何在保留表达力的同时让累乘稳定"这一个问题
- 3:1的混合比例正在成为默认配方,至少在中型规模上
- NoPE(无显式位置编码)+ 数据相关的状态转移正在替代RoPE,因为门控本身就承担了位置信息编码的功能
- 多跳推理是线性注意力当下最大的软肋,全靠混合层里的全注意力兜底
最后
说回MRU本身——它现在还远不是一个可以拿到生产环境用的方案,作者自己也承认这只是个"业余项目的更新"。但在大厂们已经把线性注意力推到一个相当成熟的工程节点之后,看到还有独立开发者在用最朴素的方式重新走一遍这条路、并且诚实地公开自己的失败和改进,反而是一件让人觉得社区还很健康的事。
顺便一提,目前主流的线性注意力相关开源模型——Kimi Linear、Qwen3-Next 系列——OpenAI Hub 都已经接入,一个 Key 直接调,兼容 OpenAI 格式,省去了自己部署 vLLM 的折腾,想对比测试不同架构在长上下文下的实际表现可以直接用。
参考来源
- An Update on Matrix Recurrent Units, an Attention Alternative - Reddit — MRU作者本次更新的原始帖子,包含改进细节和讨论
- Kimi Linear学习笔记:让Attention又快又好 - 知乎 — 对Kimi Linear论文的中文深度解读,对照理解MRU所在的技术脉络
- Kimi-Linear-48B-A3B-Instruct - Hugging Face — Kimi Linear的官方模型与技术报告


