清华开源空间模型干翻Gemini:120分钟长视频边看边学

清华团队中选 ECCV 2026 的空间智能新作把视频流式持续学习塞进了 VLM——120 分钟长视频边看边记,多项空间推理基准超越 Gemini,代码已开源。
把"持续学习"塞回空间智能,清华这次让 Gemini 不太好看
6 月下旬,清华团队公布了一项被 ECCV 2026 录用的工作:一个开源的空间智能模型,主打"在世界变化中持续学习"。最直接的卖点是——丢给它一段 120 分钟的连续视频,它能一边看一边把空间信息编码进自己的状态里,而不是像现在主流的 VLM 那样把整段视频切成几十帧塞进上下文里硬算一遍。
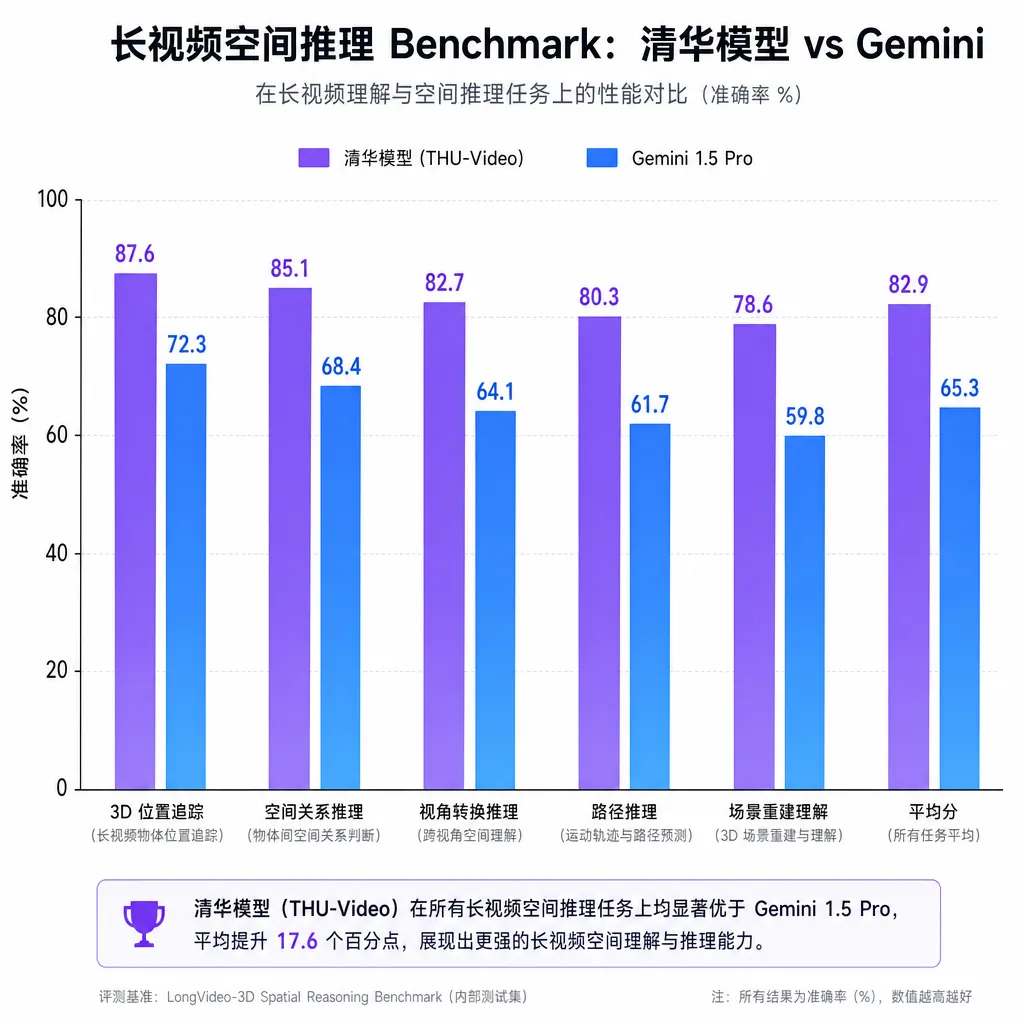
在多项空间推理基准上,这个模型把 Gemini 系列的最新闭源版本压了下去。对一个由学术实验室主导、参数量明显小一档的开源模型来说,这种结果并不是常态。
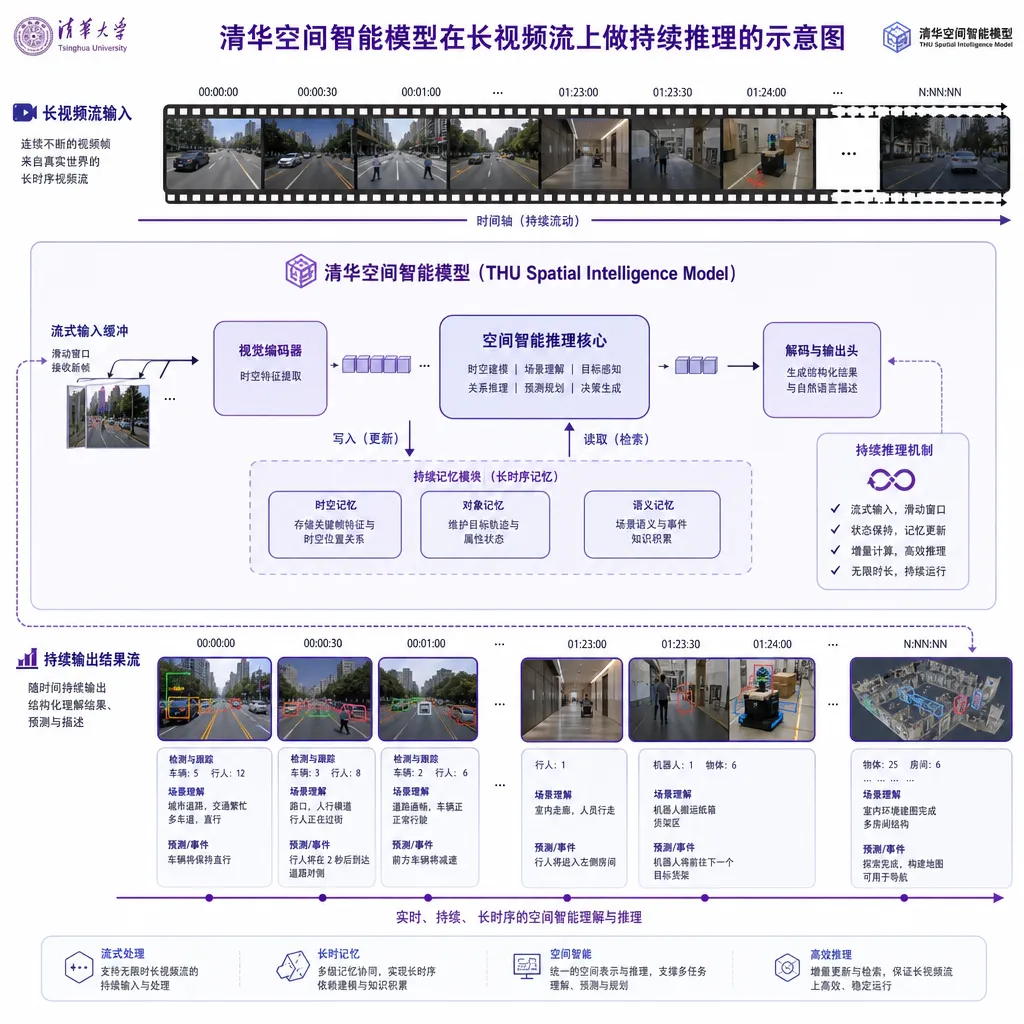
它解决的到底是什么问题
要理解这件事的分量,得先看看现在的空间智能模型是怎么处理视频的。
主流路线大致两种:
- 稀疏采样:从视频里抽 8、16、最多 32 帧,丢进 VLM。Gemini、GPT-4o、Qwen-VL 都是这个路数。问题显而易见——你抽 16 帧去理解一段 2 小时的房间漫游视频,丢掉的信息远多于保留的。
- 3D 先验注入:用点云、深度相机或者 SfM 重建出来的几何信息作为额外模态喂给模型。这条路效果好但贵,依赖额外的传感器和重建流水线,端到端不够干净。
清华这篇 ECCV 工作走的是第三条路:把视频当成时间流,让模型在线地、增量地维护一份关于空间的"记忆"。 这个思路在概念上更接近人脑——你走进一个新房间,不是每秒在脑子里重建一次三维点云,而是逐步形成"客厅在左、厨房在右、餐桌上有杯子"这样的层级化空间表征,并随着观察持续更新。
用论文里的说法,真正的空间智能不是一次性"看完答题",而是在世界变化中持续学习。这句话不算新——LeCun 的 JEPA、世界模型那一派都在反复念这个咒——但在长视频空间推理这个具体场景把它落地到能跑赢 Gemini,目前确实是头一回。
120 分钟视频"边看边记"是怎么做到的
关键在于状态如何维护。注意力机制天然不擅长这件事——上下文一长,KV cache 爆炸,算力消耗平方级上涨。所以这条线上的方案通常会用某种"压缩—保留"机制,让模型有一个固定大小的工作记忆。
根据已经公开的信息,清华团队的做法可以拆成几层:
- 流式编码器:视频帧按时间顺序进入,每一帧都被编码进一个持续演化的空间状态,而不是被独立 tokenize 后等着 attention 处理。
- 持续学习损失:训练阶段就在长视频上做时间维度的自监督——模型要在 t 时刻预测的不只是"现在这帧讲了啥",还要能在 t+k 时刻被问起 t 时刻的空间细节时仍然答得出来。这其实是把传统的"遗忘问题"显式拉进了 loss。
- 空间锚点机制:对显著的几何/语义元素打"锚",让模型在长程上不会因为时间推移而把关键空间结构稀释掉。
这套机制最直接的收益是推理时显存基本不随视频长度增长。这跟把 120 分钟视频强行塞进 1M 上下文窗口完全是两个游戏——Gemini 那种做法每多看一分钟视频,token 数就要往上叠,最终要么截断要么慢得没法用。
跟 Gemini 比,到底好在哪
空间推理这个赛道现在有几个比较硬的 benchmark:VSI-Bench(视频空间智能)、EmbSpatial-Bench(具身空间)、MMSI-Bench(多图空间)以及一些专门的长视频 QA。
清华这个模型在长视频相关的子集上优势最明显。原因不难理解——基准里那些"30 分钟之前你看到的那个红色杯子在哪儿"这类问题,对稀疏采样模型来说约等于送命题。Gemini 哪怕开 1M 上下文,对于一个连续视频流也是要做下采样的,关键帧只要没被采到,答案就是猜。
而清华这套模型由于本身就是流式架构,时间维度上的细节是逐步沉淀进状态里的,不存在"采样到/没采样到"这种 0/1 问题。
几个值得记住的对比维度:
| 维度 | 主流 VLM(Gemini 等) | 清华空间模型 | |------|---------------------|------------| | 视频处理方式 | 稀疏采样 + 长上下文 | 流式 + 持续状态 | | 长度上限 | 受上下文窗口限制 | 理论上无限长 | | 显存增长 | 近似线性/平方 | 近似常数 | | 长程空间一致性 | 依赖采样运气 | 由训练目标保证 | | 是否开源 | ❌ | ✅ |
这种架构差异决定了它不只是"分数更高",而是能干一些 Gemini 干不了的活——比如机器人在房间里跑半小时之后被问"刚才厨房的那个杯子还在桌上吗",对流式模型是自然的查询,对采样型模型基本只能瞎蒙。
为什么这件事比"刷榜"更重要
回到更宏观的视角看,2026 年上半年整个 AI 圈对"世界模型"和"具身智能"这两个词的热度还在持续走高。智源大会刚开完,世界模型论坛排满了从学术到产业的玩家——Skywork、极佳视界、自变量、星源智……所有人都在试图回答同一个问题:模型怎么才能真正理解物理世界。
当前主流路线分两派:
- 生成派:用视频生成模型隐式学物理。Sora、Veo、Hunyuan World 这一路。
- 理解派:让 VLM 在 3D / 时空维度上变得更强。Spatial-MLLM、SenseNova-SI、清华和腾讯混元此前合作的 GEM 都属于这一路。
清华这次的 ECCV 工作可以看作"理解派"里的一个新分支——把"持续学习"作为空间智能的核心定义之一。这个判断其实挺锋利:它隐含的意思是,无论你视频生成做得多漂亮、3D 重建多精细,只要模型不能在时间流上持续维护状态,它就不算真正具有空间智能。
这一点对接下来一年的机器人和具身智能很关键。你想想 UR5、宇树、自变量这些公司在做的事——机器人要在一个家庭里持续工作几小时甚至几天,每一秒都在感知环境变化。用稀疏采样的 VLM 当大脑,根本不够看。流式持续学习这套范式,理论上才是 VLA(视觉-语言-动作)模型的正确底座。
开源带来的连锁反应
模型代码和权重都开源了,这件事的影响会比基准分数大得多。
几个可以预期的方向:
- 被快速集成到具身智能栈里:自变量、银河通用、星源智这些做具身基础模型的公司很可能在几周内就有人把这套流式编码器接到自家的 VLA 里跑实验。
- 倒逼闭源厂商:Gemini 在视频流处理上一直是闭源世界的标杆。被一个开源模型在长视频空间推理上超过,对 Google 的产品定位是个压力。
- 推动新 benchmark:现有 benchmark 对"持续学习"维度的考察其实很弱。这篇工作之后,长程时间一致性、跨场景记忆保持这类新评测大概率会被推上来。
对开发者来说,更现实的问题是怎么用。开源仓库给了完整的训练与推理代码,权重也直接放在 Hugging Face 上。本地跑推理对硬件门槛不算高——流式架构的好处之一就是单卡 24G 显存可以处理任意长度的视频,这跟需要 80G H100 才能把长上下文塞进去的方案完全不是一个量级。
几个还没解决的问题
该泼的冷水也得泼。这套架构有几个明显的悬而未决的点:
- 训练成本:流式持续学习的训练数据要求长视频带细粒度时序标注,这种数据量目前还很有限。论文里用的训练集规模相比闭源大厂依然偏小。
- 错误累积:状态在长时间维护中会不会偏移?目前公开的 demo 跑到 120 分钟看起来稳定,但到 10 小时、100 小时呢?
- 跟生成式世界模型的关系:理解能力上去了,但模型本身不能"想象"未来的场景演化,对规划任务而言还差一层。
这些问题,团队在论文里也算坦诚地点了,留作下一步工作。
一句话总结
清华这次的工作最大的价值不在于刷过了 Gemini,而在于把"持续学习"重新摆回了空间智能讨论的中心。过去两年大家都在比谁的上下文窗口长、谁的 3D 先验强,但一个会忘的模型不可能真的理解世界。从这个意义上说,这篇 ECCV 2026 paper 是个值得记一下的拐点。
开源仓库已经放出,对做具身智能、VLA、长视频理解的团队来说,建议直接 clone 下来跑一跑——它大概率会改变你对"视频该怎么进模型"这件事的默认假设。
参考来源
- 清华Spatial-MLLM:仅用16帧视频碾压GPT-4o/Gemini(知乎专栏) ——清华此前在空间多模态模型上的相关工作背景

