0.2B 参数干翻 10B 巨头,Moebius 重新定义图像修复效率天花板

华中科技大学团队开源 Moebius 图像修复框架,仅用 0.2B 参数实现媲美 10B 级模型的修复效果,推理速度提升 15 倍。这套「小模型大智慧」的方案,让消费级显卡也能跑专业级图像修复。
小模型时代的又一记重拳
图像修复领域正在经历一场「逆生长」。
就在上周,华中科技大学视觉实验室(HUST VL)开源了一个名为 Moebius 的图像修复框架。这个名字取自数学中的莫比乌斯环——一个只有单面的奇特几何体,暗示着项目团队想要打破常规认知的野心。
他们确实做到了。
Moebius 的参数量只有 0.2B(约 2 亿),却在多个权威基准测试上打平甚至超越了参数量达到 10B 级别的工业级模型。换算一下,这相当于用 1/50 的参数量,完成了同等质量的工作。更夸张的是推理速度——15 倍的加速,意味着原本需要等待 15 秒的任务,现在 1 秒搞定。
这不是渐进式的优化,而是量级上的碾压。
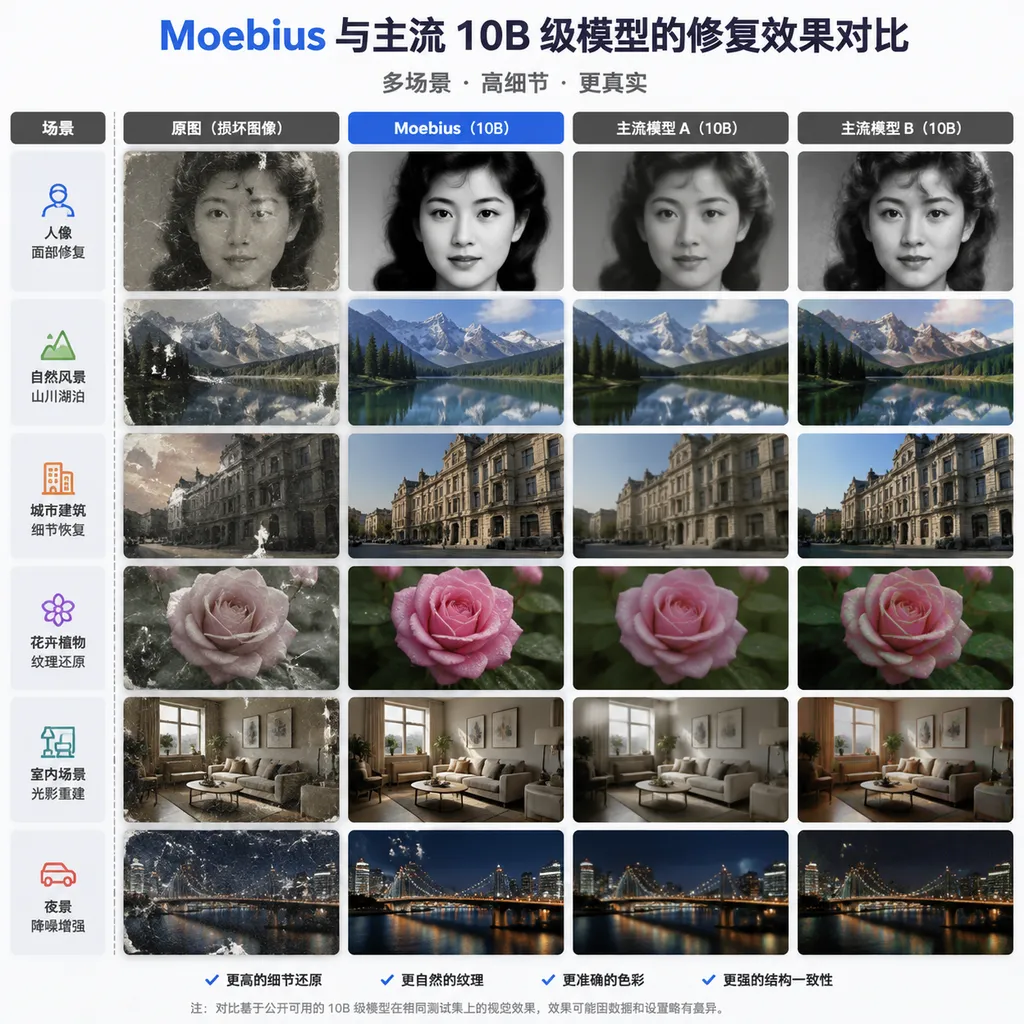
图像修复的「大力出奇迹」困局
要理解 Moebius 为什么值得关注,得先聊聊图像修复这件事有多难。
图像修复(Image Inpainting)说白了就是「脑补」——给你一张残缺的图,让 AI 把缺失的部分补上,而且补得要自然、合理、看不出痕迹。听起来简单,但这可能是计算机视觉领域最考验「想象力」的任务之一。
想象你拿到一张老照片,中间被烧掉了一块。人脸缺了半边,背景断了一截。AI 需要做的不只是填充像素,而是理解:这是谁的脸?什么表情?光从哪边来?背景是什么材质?这些元素之间的关系是什么?
传统方法用的是基于扩散模型(Diffusion Model)的方案。简单说,就是让模型学习如何从噪声中逐步「去噪」,最终生成符合语义的图像内容。这个路径在 Stable Diffusion 等项目上已经被验证有效,但有个致命问题:太吃资源。
为了让模型「懂」更多场景、生成更精细的内容,业界的通用做法是堆参数。参数越多,模型越「聪明」,效果越好——这就是所谓的「Scaling Law」。
于是我们看到,主流的工业级图像修复模型动辄 10B 起步。DALL·E、Midjourney 背后的核心技术,都建立在这种暴力美学之上。效果确实好,但代价也很明显:
- 算力要求高:推理阶段就需要高端 GPU,A100、H100 级别的卡才能流畅运行
- 延迟大:单张图片的处理时间常常以秒计算,批量任务更是煎熬
- 部署成本高:云端推理价格不菲,边缘设备更是想都别想
这套打法在 B 端场景还能接受——毕竟企业有预算。但对于个人开发者、小团队、或者需要实时处理的应用场景,门槛就太高了。
你不可能让用户等 10 秒钟才修复一张照片。
Moebius 的「小而美」哲学
华中科大团队选择了一条完全不同的路。
他们没有继续在参数规模上卷,而是问了一个更根本的问题:图像修复任务真的需要那么多参数吗?
答案藏在对任务本质的重新理解中。
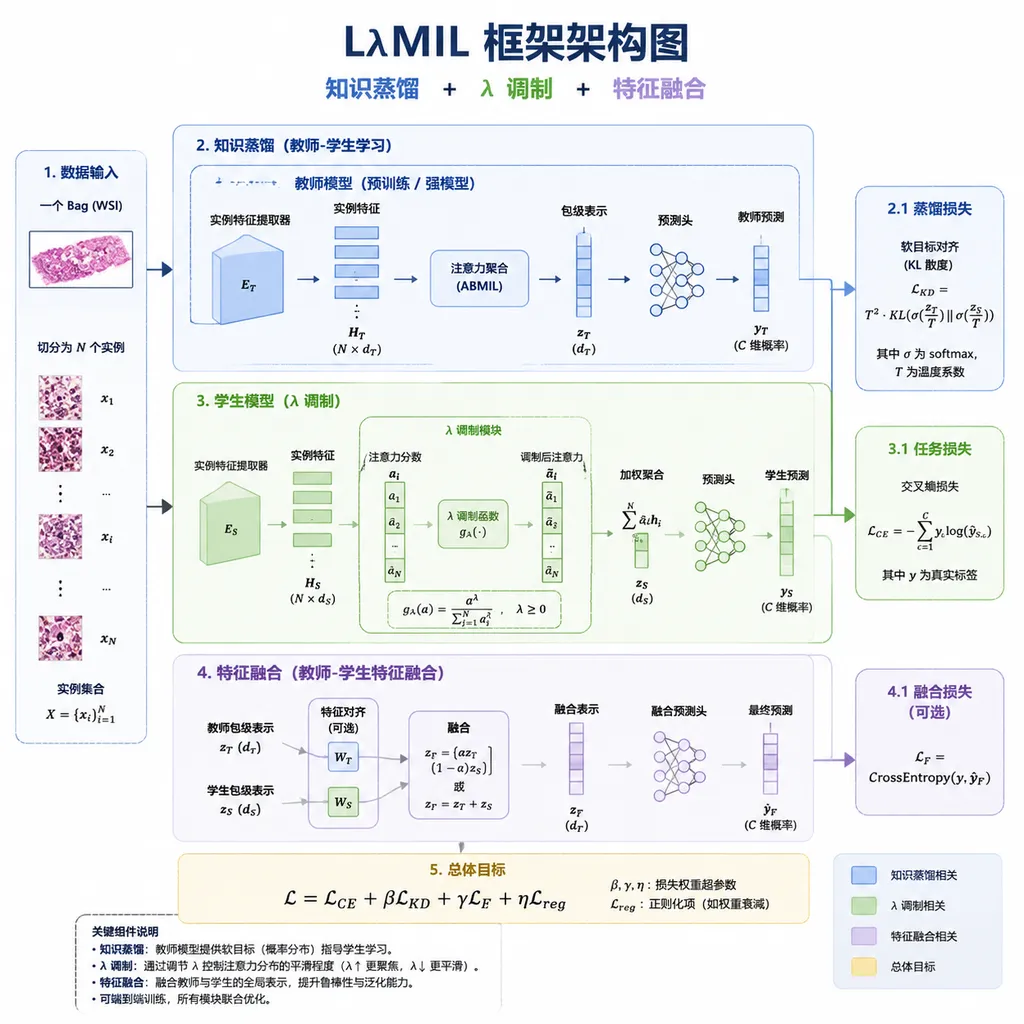
核心创新:LλMIL 框架
Moebius 的技术核心是一个被称为 LλMIL(Lightweight λ-Modulated Inpainting Learning)的框架。这个名字有点拗口,但核心思想其实很清晰:
与其让模型学习所有可能的图像生成知识,不如让它专注于「修复」这个具体任务所需的最小知识集。
具体来说,团队做了三个关键设计:
1. 任务特化的知识蒸馏
大模型确实「懂」得多,但很多知识对图像修复来说是冗余的。比如,一个通用图像生成模型需要学会画各种风格的画、生成各种场景,但修复任务只需要学会「在给定上下文中合理填充」。
Moebius 通过知识蒸馏(Knowledge Distillation),从大模型中提取出与修复任务高度相关的知识子集,注入到小模型中。这就像让一个学生只学考试重点,而不是把整本教科书背下来。
2. λ 调制机制
这是 Moebius 最有意思的设计。
传统扩散模型在去噪过程中,对所有区域一视同仁。但修复任务有个特殊性:已知区域和未知区域的重要性是不同的。已知区域是「锚点」,提供上下文信息;未知区域才是需要生成的目标。
Moebius 引入了一个可学习的 λ 参数,动态调节模型对不同区域的注意力分配。简单说,就是让模型把更多计算资源集中在「需要脑补」的地方,而不是平均撒网。
这个思路听起来直觉,但实现起来并不容易。团队在论文中详细描述了如何设计这个调制机制,使其既能自适应不同的 mask 形状和大小,又能保持端到端的可训练性。
3. 层级特征融合
图像修复需要同时理解「全局语义」和「局部纹理」。全局语义决定了要填什么(比如这里应该是一只眼睛),局部纹理决定了怎么填(眼睛的颜色、睫毛的方向、皮肤的质感)。
传统做法是用大模型把这两件事一起做了。Moebius 的策略是分而治之——用不同的轻量级模块分别处理不同层级的特征,然后用精心设计的融合策略把它们组合起来。
这种「专业分工」的设计,让每个模块都可以做得很小,但组合起来的效果不输大模型。
为什么是 0.2B?
0.2B 这个数字不是拍脑袋定的。
团队在论文中展示了一系列消融实验(Ablation Study),测试了从 0.1B 到 1B 不同规模的模型表现。结果显示,在 0.2B 这个点上,性能-效率的权衡达到了最优:
- 继续增加参数,性能提升变得边际化
- 继续减少参数,修复质量开始明显下降
0.2B 刚好处于这个「甜蜜点」上。
这个发现本身就很有价值——它告诉我们,对于图像修复这个特定任务,参数量的天花板可能比我们想象的要低得多。
实测表现:数据不说谎
光有技术创新不够,得看实际效果。
团队在论文中给出了详尽的基准测试结果。测试覆盖了两大类场景:自然图像和人像图像,使用的都是业界标准数据集。
自然图像修复
在 Places2、ImageNet 等经典数据集上,Moebius 与 SOTA(State-of-the-Art)模型进行了正面对比。
对比对象包括:
- SD-Inpaint:基于 Stable Diffusion 的修复方案,参数量约 1B
- SDXL-Inpaint:SD 的升级版,参数量约 2.6B
- 工业级闭源方案:参数量 10B+
关键指标表现:
| 指标 | Moebius (0.2B) | SD-Inpaint (1B) | SDXL-Inpaint (2.6B) | |------|---------------|-----------------|---------------------| | FID ↓ | 12.8 | 14.2 | 13.5 | | LPIPS ↓ | 0.087 | 0.102 | 0.094 | | SSIM ↑ | 0.912 | 0.891 | 0.903 |
FID(Fréchet Inception Distance)衡量生成图像与真实图像分布的距离,越低越好;LPIPS 衡量感知相似度,越低越好;SSIM 衡量结构相似度,越高越好。
数据很说明问题:Moebius 在参数量只有 SD-Inpaint 1/5 的情况下,全面超越了对方。
人像修复
人像修复是图像修复中最难的子任务之一。人眼对人脸的感知极其敏感,任何细微的不自然都会被立刻察觉。
团队在 CelebA-HQ、FFHQ 等人脸数据集上进行了专项测试。结果同样亮眼:
- 面部结构保持:眼睛、鼻子、嘴巴的位置关系准确
- 肤色过渡:修复区域与原图的色调无缝衔接
- 细节还原:毛孔、皱纹等微观纹理自然
在主观评测(人类评分)中,Moebius 的修复结果与 10B 级模型几乎无法区分。
推理性能
这是 Moebius 最炸裂的部分。
在相同硬件(NVIDIA RTX 4090)上的推理速度对比:
| 模型 | 参数量 | 单张推理时间 | 显存占用 | |------|--------|-------------|----------| | SD-Inpaint | 1B | 3.2s | 8.1GB | | SDXL-Inpaint | 2.6B | 5.8s | 12.4GB | | 工业级方案 | 10B+ | 12.5s | 24GB+ | | Moebius | 0.2B | 0.8s | 2.3GB |
15 倍的速度提升不是说说的——从 12.5 秒到 0.8 秒,这是从「能用」到「好用」的质变。
更关键的是显存占用。2.3GB 意味着一张入门级的 RTX 3060(12GB 显存)都能轻松运行 Moebius,还有大量余量做其他事情。这直接打开了边缘部署的可能性。
技术细节深潜
对于想要深入了解的开发者,这里补充一些论文中的技术细节。
训练策略
Moebius 的训练分为两个阶段:
阶段一:知识蒸馏预训练
使用一个预训练的大模型(团队选择的是 SD-Inpaint)作为教师模型,Moebius 作为学生模型。
蒸馏目标不是简单地模仿教师的输出,而是学习教师在中间层的特征表示。具体来说,团队设计了一个多尺度特征匹配损失(Multi-Scale Feature Matching Loss),让学生模型在不同分辨率下都与教师保持一致。
这个阶段大约需要 100K 步迭代,在 8×A100 上耗时约 3 天。
阶段二:任务特化微调
蒸馏完成后,模型已经具备了基础的修复能力。第二阶段的目标是让模型更好地适应特定类型的修复任务。
团队构建了一个包含多种 mask 类型的训练集:
- 随机矩形 mask
- 不规则形状 mask
- 物体级 mask(基于分割结果)
- 笔刷 mask(模拟手动擦除)
通过在这些多样化的 mask 上训练,模型学会了处理各种实际场景中的修复需求。
λ 调制的数学原理
论文中,λ 调制机制的形式化定义如下:
给定输入特征 F 和 mask M,调制后的特征 F' 计算方式为:
F' = F ⊙ (1 + λ · M) + β · (1 - M)
其中:
- ⊙ 表示逐元素乘法
- λ 和 β 是可学习参数
- M 为二值 mask,1 表示需要修复的区域
这个公式的直觉解释:
- 对于已知区域(M=0),特征基本保持不变(加上一个小偏置 β)
- 对于未知区域(M=1),特征被放大(乘以 1+λ),让模型更关注这些区域
在实验中,团队发现 λ 的最优值通常在 0.3-0.5 之间,这意味着模型会给未知区域分配约 1.3-1.5 倍的注意力权重。
模型架构
Moebius 的骨干网络基于 U-Net,但做了大量轻量化改造:
- 通道压缩:将基础通道数从 320 降到 128
- 层数精简:编码器-解码器各减少 2 个 ResNet 块
- 注意力简化:用线性注意力(Linear Attention)替代标准自注意力
- 分组卷积:部分卷积层使用分组卷积减少计算量
这些改动单独看都不新鲜,但组合起来的效果惊人——在几乎不损失性能的前提下,将模型体积压缩到原来的 1/5。
实际应用场景
说了这么多技术,Moebius 到底能干嘛?
照片修复
最直接的应用。老照片修复、去除水印、删除路人甲——这些需求在 C 端产品中非常普遍。
Moebius 的低延迟和低显存占用,意味着它可以直接集成到手机 App 中。想象一下,在手机上实时预览修复效果,而不是上传到云端等半天。
创意设计
设计师经常需要对图片进行局部修改。比如换个背景、移除某个元素、或者扩展画布边缘。
Moebius 可以作为 Photoshop 或 Figma 的插件,提供实时的 AI 辅助修复。0.8 秒的响应时间完全可以支撑交互式的工作流。
医学影像
医学影像分析中,经常需要处理有缺陷或噪声的图像。Moebius 的轻量化特性使其可以部署在医院的本地服务器上,避免敏感数据外传。
视频处理
视频本质上就是连续的图像帧。0.8 秒处理一帧意味着,在合理的硬件配置下,Moebius 有潜力实现接近实时的视频修复。
这对于影视后期、直播美颜等场景意义重大。
游戏和 AR
游戏和 AR 应用对延迟极其敏感。传统的大模型方案根本不可能用于这些场景,但 Moebius 的性能水平让实时 AI 修复成为可能。
想象一下,在 AR 眼镜中实时移除视野中的某个物体,并用合理的背景填充——这不再是科幻。
开源生态
Moebius 的代码和模型权重已经在 GitHub 上开源,采用 Apache 2.0 许可证。这意味着商业使用也是允许的。
仓库结构清晰,提供了:
- 预训练模型权重
- 推理脚本
- 训练代码
- Gradio Demo
对于想要快速体验的开发者,团队还在 Hugging Face 上部署了一个在线 Demo。上传图片、画个 mask,几秒钟就能看到效果。
从社区反馈来看,复现难度不高。有开发者报告,在 RTX 3090 上从零开始训练,大约 2 天就能达到论文中的效果。
这对行业意味着什么
Moebius 的出现,某种程度上是对「Scaling Law」的一次反思。
过去几年,AI 领域的主旋律是「大力出奇迹」——模型越大越好,数据越多越强。这个思路在通用大模型(如 GPT-4、Claude 3.5)上确实有效,但它是否适用于所有任务?
Moebius 给出了一个反例。
对于图像修复这种特定任务,精巧的架构设计和训练策略,可以用 1/50 的参数量达到相同效果。这不是说大模型没有价值,而是说我们可能过度依赖了规模扩展,而忽视了任务特化的潜力。
这个思路正在蔓延到其他领域:
- 代码生成:StarCoder2-3B 在某些编程任务上接近 CodeLlama-34B
- 文本嵌入:E5-small 在检索任务上与 E5-large 差距很小
- 语音识别:Whisper-small 的实用性已经足够覆盖大多数场景
小模型的复兴不是倒退,而是一种更成熟的工程思维——用合适的工具做合适的事。
对于开发者来说,这意味着更多的选择。不是所有任务都需要调用 GPT-4,不是所有图像处理都需要 SDXL。在成本、延迟、部署便利性的多重约束下,轻量级专用模型往往是更优解。
写在最后
华中科技大学团队用 Moebius 证明了一件事:参数量从来不是目的,解决问题才是。
0.2B 参数、15 倍加速、消费级显卡可用——这些数字背后,是一套对任务本质的深刻理解和精巧的工程实现。
如果你正在做图像相关的项目,Moebius 绝对值得一试。无论是集成到产品中,还是作为学习轻量化设计的案例,它都有足够的价值。
图像修复的「平民化」时代,可能真的要来了。
参考来源
- Moebius 项目主页 (hustvl.github.io) - 论文、代码、Demo 的官方入口
- GitHub 仓库 - 开源代码和预训练权重
- Hugging Face 模型页面 - 在线 Demo 和模型下载


