字节神秘代号「groudon」现身Arena,编程模型暗战升级

LMSys Arena 悄然上线字节跳动神秘模型「groudon」,定位编程场景,但官方渠道查无此名。结合字节近期密集的模型发布节奏,这可能是豆包 Code 系列的内测版本,也可能是全新架构的探索。
字节神秘代号「groudon」现身Arena,编程模型暗战升级
没有预告,没有发布会,字节跳动又在搞事情了。
昨天,有开发者在 LMSys Chatbot Arena 上发现了一个从未见过的模型名字:groudon。提交方显示为字节跳动,定位标签写的是「code」——也就是编程场景。但诡异的是,翻遍字节官方文档、火山引擎控制台、豆包 API 列表,都找不到这个名字。
一个大厂的模型,悄悄上了最权威的盲测平台,却没有任何官方背书。这种操作,要么是内测版本提前「试水温」,要么是字节在憋一个大招。
「groudon」是什么来头?
先说这个名字本身。groudon(固拉多)是《宝可梦》系列里的传说级神兽,掌控大地与陆地。字节之前的模型代号走的是「seed」(种子)路线,比如 Doubao-Seed 系列,这次突然换成宝可梦命名,风格转变相当明显。
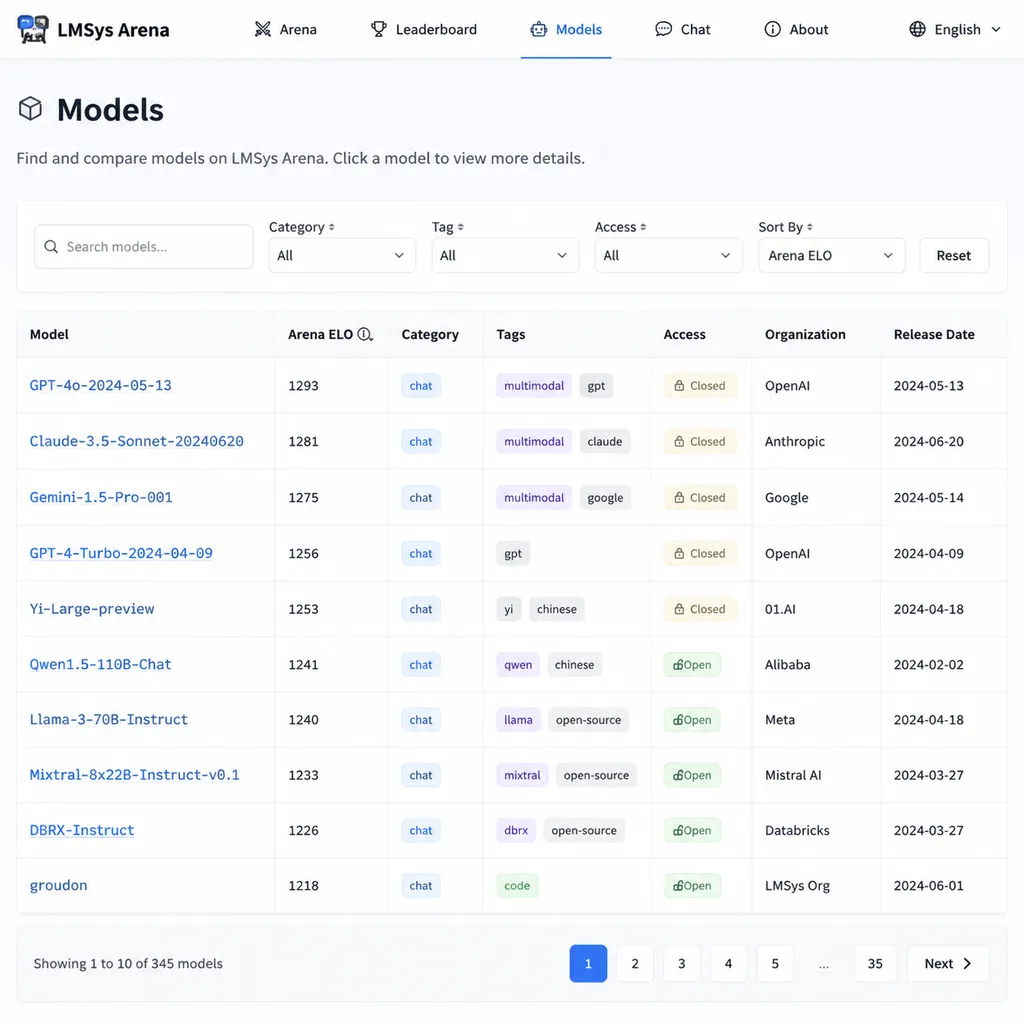
社区里最早发现这个模型的开发者提到,他们一直用「seed」和「dola」作为关键词监控字节的新模型动态,结果这次完全扑空——字节选择了一个毫无关联的代号。这种「隐身」策略,在 Arena 的历史上并不罕见。很多厂商会在正式发布前,把模型匿名或用代号丢进 Arena 跑分,收集真实用户的偏好数据,再决定后续的产品策略。
但问题是:groudon 到底是什么?
可能性一:豆包 2.0 Code 的迭代版本
今年春节期间,字节发布了豆包大模型 2.0,其中包含一个专门针对编程场景优化的版本——Doubao-Seed-2.0-Code。官方当时的说法是,这个模型强化了代码库解读能力,提升了应用生成和 Agent 工作流中的纠错能力,并且已经接入了 TRAE(字节的 AI 编程产品)。
从定位上看,groudon 标注的「code」标签与豆包 2.0 Code 高度吻合。如果是这个方向,groudon 可能是 2.0 Code 的进一步调优版本,或者是针对 Arena 评测特别准备的「竞赛版」。
毕竟,Arena 的 Elo 排名直接影响开发者的模型选择决策,厂商们对这个榜单的重视程度,比很多人想象的要高得多。
可能性二:全新架构的编程模型
另一种可能是,groudon 根本不是现有产品线的延伸,而是字节在探索一条新的技术路径。
过去一年,编程模型的竞争已经从「谁能写出正确代码」升级到「谁能完成复杂的多步骤开发任务」。Claude 靠着出色的长上下文理解和指令遵循能力,在开发者群体中口碑极佳;OpenAI 的 Codex 迭代到 GPT-4 之后,也在 Agent 化编程方向上持续发力。
字节如果想在这个赛道上卡位,光靠豆包 2.0 Code 的增量改进可能不够。一个从头设计、专门针对编程场景的模型,反而更有想象空间。
字节的「模型内卷」有多猛?
理解 groudon 的意义,需要先看看字节这半年在模型层面的动作密度。
春节期间的「轰炸式发布」
2026 年春节前后,字节跳动几乎是一天一个大新闻:
- Seedance 2.0:视频生成模型,支持文本和图像输入,能生成长达 60 秒的多镜头视频,直接用在了央视春晚的《贺花神》节目里
- 豆包大模型 2.0:包含 Pro、Lite、Mini 三个通用版本,加上 Code 编程专用版本
- Seedream 4.5 / 5.0:图像生成模型的连续更新
- Seed3D 2.0:3D 生成模型
这种发布节奏,在国内厂商里几乎没有对手。智谱的 GLM-5、MiniMAX 的 2.5、DeepSeek 的 V4,虽然也在同期更新,但字节的产品线覆盖面明显更广——从文本到图像到视频到 3D,几乎所有模态都在同步推进。
编程赛道的「隐性战争」
在这一堆发布里,编程模型其实是最低调的一个。豆包 2.0 Code 的官宣只有寥寥几段话,主要卖点是「与 TRAE 结合使用效果更佳」,并没有像 Pro 版本那样大张旗鼓地公布 benchmark 成绩。
但低调不代表不重要。
编程模型是目前 AI 应用落地最成熟的场景之一。GitHub Copilot 证明了开发者愿意为提效付费,Cursor 证明了 AI IDE 可以重塑整个开发流程。对于字节来说,TRAE 是他们在这个赛道的核心产品,而 TRAE 的竞争力,归根结底取决于底层模型的能力。
groudon 的出现,可能意味着字节在编程模型上的投入,比外界看到的要大得多。
Arena 评测的「潜规则」
为什么厂商喜欢在 Arena 上搞「神秘模型」?
LMSys Chatbot Arena 是目前业界公认最公正的模型评测平台之一。它的核心机制是「盲测」——用户不知道自己在和哪个模型对话,只能根据回答质量选出更好的那个。最终的 Elo 排名,反映的是真实用户在真实场景下的偏好,而不是厂商自己挑选的 benchmark 成绩。
这种机制对厂商来说,既是机会,也是风险。
机会在于:如果一个模型能在 Arena 上拿到好成绩,这个成绩的说服力远超任何自研 benchmark。开发者会相信,「这个模型在真实场景下确实好用」。
风险在于:Arena 的评测是公开的,所有人都能看到结果。如果一个正式发布的产品在 Arena 上表现不佳,对品牌的伤害是实打实的。
所以很多厂商会用「代号」或「匿名」的方式,先把模型丢进 Arena 跑一段时间,看看真实表现如何。如果成绩好,就可以大张旗鼓地宣传;如果成绩一般,悄悄撤掉也不会有人注意。
groudon 大概率就是这种策略的产物。
编程模型的下一个战场在哪?
抛开 groudon 本身不谈,字节选择在编程场景上加注,方向是对的。
当前编程模型的竞争,主要集中在几个维度:
1. 代码生成的「准确率」与「完整性」
最基础的能力,就是给一个需求描述,能不能写出正确的代码。这一点大多数主流模型已经做得不错了,差距在缩小。
但更难的是「完整性」——能不能一次性把整个功能写完,包括边界条件处理、错误处理、测试用例?还是需要用户不断追问、补充、修正?
豆包 2.0 Code 在发布时强调的「应用生成能力」,就是在解决这个问题。官方举的例子是用 TRAE + 豆包 2.0 Code 开发一个「春节小镇」互动项目,只用 5 轮提示词就完成了。这种端到端的生成能力,是编程模型的核心竞争力之一。
2. 代码库理解与「上下文长度」
真实的开发场景,不是从零写代码,而是在一个已有的项目里做修改、加功能、修 bug。这要求模型能「读懂」现有的代码库,理解项目的架构、依赖关系、编码风格。
这对模型的上下文长度和长文本理解能力提出了很高的要求。豆包 2.0 系列支持的上下文窗口官方没有公布具体数字,但从定价策略(按输入长度分段计费,32k 以内是一档)可以推测,至少在 32k 以上。
相比之下,Claude 3 支持 200k 上下文,GPT-4 Turbo 支持 128k。如果 groudon 在这个指标上有突破,会是一个重要的卖点。
3. Agent 工作流与「多步骤任务」
编程模型的终极形态,不是一个「代码补全工具」,而是一个能独立完成开发任务的「AI 程序员」。这意味着模型要能:
- 理解高层需求
- 拆解成具体的开发步骤
- 自己写代码、跑测试、修 bug
- 必要时调用外部工具(查文档、搜 StackOverflow、跑 shell 命令)
这就是所谓的「Agent 化」。豆包 2.0 Code 提到的「增强模型在 Agent 工作流中的纠错能力」,说的就是这个方向。
目前在这个领域走得最远的是 Anthropic 的 Claude,以及 Cognition 的 Devin(虽然后者争议很大)。字节如果想在 Agent 化编程上卡位,需要的不只是模型能力的提升,还有整个工具链的配合——TRAE 作为 IDE 层的产品,承担的就是这个角色。
开发者应该关注什么?
对于普通开发者来说,groudon 目前还只是一个「传闻」级别的存在。没有官方文档,没有 API,没有定价,甚至不确定它到底是不是一个独立的产品。
但有几个信号值得关注:
1. Arena 上的后续表现
如果 groudon 在 Arena 的 code 类任务上持续刷分,说明字节在编程模型上确实有料。可以持续关注 lmsys.org 的排行榜更新。
2. TRAE 的功能迭代
字节的编程模型主要通过 TRAE 对外输出能力。如果 TRAE 近期有大的功能更新,或者接入了新的「专家模式」「高级推理」之类的选项,可能就是 groudon 或其衍生版本上线的信号。
3. 火山引擎的 API 更新
面向企业和开发者的 API 服务,是字节模型商业化的主要渠道。如果 groudon 最终作为正式产品发布,大概率会在火山引擎上线 API。可以关注火山引擎的模型列表更新。
国产编程模型的「集体冲锋」
把视野拉远一点,groudon 的出现,其实是国产编程模型集体发力的一个缩影。
过去一年,这个赛道的玩家越来越多:
- 智谱 GLM-5:7450 亿参数,强化了多 Token 预测与智能体工作流,定位「顶级的对话与编程智能体模型」
- DeepSeek V4:支持百万级 Token 上下文,在超长代码库理解上有独特优势
- MiniMAX 2.5:重点提升编程能力与智能体交互,已进入海外内测
- 阿里通义灵码:基于通义千问,主打 VS Code 和 JetBrains 插件生态
- 百度文心快码:依托文心大模型,与百度云开发者生态深度绑定
这些模型各有侧重,但共同指向一个方向:编程是 AI 落地最快、付费意愿最强的场景之一,谁能在这个赛道上建立优势,谁就能在 AI 商业化的竞争中占据有利位置。
字节在 Arena 上「偷偷」放出 groudon,某种程度上说明他们也在加速追赶。毕竟,编程模型的评测相对客观——代码要么能跑,要么不能跑;能解决的问题,比聊天类任务更容易量化比较。
在这个赛道上,没有「品牌光环」可以依赖,只有实打实的能力说话。
写在最后
groudon 这个名字,可能很快就会有官方解释,也可能永远停留在社区的猜测里。
但它的出现,揭示了一个有趣的现实:大模型的竞争,已经从「谁先发布」变成了「谁能在真实评测中胜出」。Arena 这样的第三方平台,正在成为模型能力的「裁判席」——而厂商们,也开始学会用匿名、代号、灰度测试这些手段,在正式发布前先「试水温」。
对于开发者来说,这其实是好事。你不用再只看厂商自己发的 benchmark,而是可以参考 Arena 的盲测结果,用更客观的数据做选型决策。
至于 groudon 到底是什么——让我们等字节自己揭晓答案吧。
参考来源
- arena 突然上线神秘字节模型「groudon」 定位 code - Linux.do 社区讨论帖,最早发现该模型的信息源


