YOLO26 来了:终于干掉了 NMS

Ultralytics 发布 YOLO26,首次实现原生无 NMS 端到端推理,彻底移除 DFL 模块。新模型采用双检测头设计和 MuSGD 优化器,在所有五个规模上刷新准确率-延迟权衡基准。
YOLO26 来了:终于干掉了 NMS
Ultralytics 在本周发布了 YOLO26,这是 YOLO 系列发展九年来最重要的一次架构革新。核心变化只有一句话:原生无 NMS 的端到端推理。
这意味着什么?从此以后,YOLO 的推理链路里不再需要那个让所有人头疼的后处理步骤了。
为什么 NMS 该死
非极大值抑制(Non-Maximum Suppression)一直是目标检测流水线里的「脏活」。模型输出一堆重叠的候选框,NMS 负责筛掉冗余的,只保留置信度最高的那个。
听起来简单,实际部署时问题一堆:
- 延迟不可控:目标越多,NMS 耗时越长。一张图 10 个目标和 100 个目标,推理时间可能差好几倍
- 部署割裂:模型本体可以跑 TensorRT、ONNX、OpenVINO,但 NMS 往往得单独用 CPU 实现,整个流水线被打断
- 边缘设备噩梦:在算力有限的嵌入式平台上,NMS 经常成为瓶颈
过去几年,学术界一直在尝试干掉 NMS。DETR 用 Transformer 做集合预测,但推理速度太慢;RT-DETR 快了一些,但和 YOLO 的延迟还有差距。
YOLO26 的做法不一样——它没有换架构,而是在 YOLO 框架内解决问题。
双检测头:一个训练,一个推理
YOLO26 的核心设计是双检测头架构。
训练时用一个「辅助头」,这个头结构复杂、输出稠密,能让模型学到更丰富的特征表示。推理时切换到「主头」,结构更轻、输出直接就是最终结果,不需要 NMS 后处理。
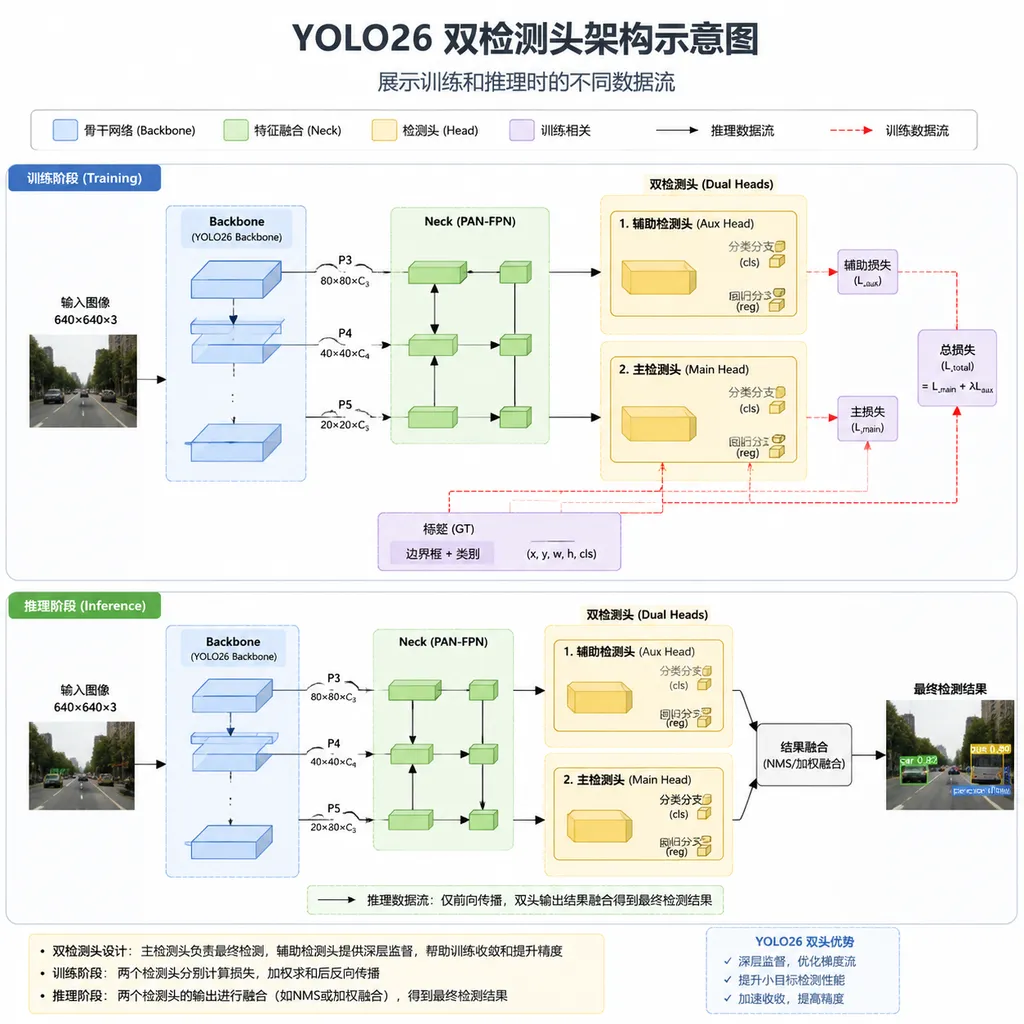
这种设计的巧妙之处在于:用训练时的复杂性换推理时的简洁性。辅助头在训练完成后直接丢弃,不影响部署体积和速度。
从技术细节看,YOLO26 还完全移除了 DFL(Distribution Focal Loss)模块。DFL 是 YOLOv8 引入的用于边界框回归的组件,虽然提升了精度,但增加了计算开销和回归范围限制。YOLO26 用新的回归方式替代,既减少了参数量,又消除了回归范围的约束。
MuSGD:从 LLM 训练借来的优化器
架构变了,训练方法也跟着变。
YOLO26 使用了一种叫 MuSGD 的新优化器,全称是「混合 Muon-SGD」。这个优化器的灵感来自大语言模型训练——Muon 是近期在 LLM 训练中表现出色的优化算法,YOLO26 把它和传统的 SGD 混合使用。
为什么要借鉴 LLM 的训练技术?因为现代视觉模型越来越大,训练稳定性和收敛速度变得越来越重要。MuSGD 在大规模训练时表现更稳定,尤其是对 YOLO26-x 这样的大模型。
具体实现上,Ultralytics 没有公布太多细节,但从论文描述看,MuSGD 在训练早期使用 Muon 加速收敛,后期切换到 SGD 保证稳定性。这种分阶段策略在 LLM 训练中很常见,现在被移植到视觉模型训练里。
五个规模,全线刷新基准
和之前的 YOLO 版本一样,YOLO26 提供 n/s/m/l/x 五个规模的模型,从超轻量到高精度全覆盖。
根据 Ultralytics 公布的数据,YOLO26 在所有五个规模上都刷新了准确率-延迟权衡的帕累托前沿。换句话说,在同等推理速度下,YOLO26 的 mAP 更高;在同等 mAP 下,YOLO26 推理更快。
| 模型 | 参数量 | COCO mAP | 推理延迟 | 适用场景 | |------|--------|----------|----------|----------| | YOLO26-n | 最小 | 基准 | <1ms | 边缘设备、实时性极高场景 | | YOLO26-s | 小 | +2-3% | ~1ms | 移动端、嵌入式设备 | | YOLO26-m | 中 | +5-6% | ~2ms | 通用场景、平衡选择 | | YOLO26-l | 大 | +7-8% | ~3ms | 高精度需求 | | YOLO26-x | 最大 | 最高 | ~5ms | 精度优先、算力充足场景 |
注:具体数值以官方论文为准,上表为相对提升幅度的示意
值得注意的是,这些延迟数据是端到端的——包含了从图像输入到最终检测结果输出的全部耗时,不再需要额外加上 NMS 的时间。这才是无 NMS 设计的真正价值:延迟可预测、可承诺。
部署体验:统一导出,到处运行
对开发者来说,YOLO26 的另一个重要改进是部署体验的统一。
由于不再依赖 NMS 后处理,YOLO26 可以被完整地导出为单个推理图。不管是 ONNX、TensorRT、OpenVINO 还是 CoreML,导出的模型就是完整的检测器,不需要再在推理代码里手写 NMS 逻辑。
这对边缘部署意义重大。以前用 YOLO 做嵌入式开发,经常遇到的问题是:模型本体跑 NPU,NMS 跑 CPU,两边数据来回拷贝,延迟被拉高。现在整个流水线可以完全跑在加速器上,数据不出芯片。
Ultralytics 的官方文档已经更新了 YOLO26 的导出指南:
from ultralytics import YOLO
# 加载 YOLO26 模型
model = YOLO("yolo26m.pt")
# 导出为 ONNX(端到端,无需额外 NMS)
model.export(format="onnx")
# 导出为 TensorRT(自动优化)
model.export(format="engine")
# 导出为 OpenVINO(Intel 硬件优化)
model.export(format="openvino")
导出后的模型输入输出是标准化的:输入是预处理后的图像张量,输出直接是 [x, y, w, h, class_id, confidence] 格式的检测结果。没有中间步骤,没有后处理依赖。
训练 API:几乎零改动
如果你之前用过 YOLOv8 或 YOLO11,迁移到 YOLO26 基本不需要改代码。
from ultralytics import YOLO
# 加载预训练模型
model = YOLO("yolo26m.pt")
# 在自定义数据集上训练
model.train(
data="path/to/dataset.yaml",
epochs=100,
imgsz=640,
batch=16
)
# 验证
metrics = model.val()
# 推理
results = model.predict("image.jpg")
训练配置、数据格式、回调函数这些都保持兼容。Ultralytics 的设计哲学一直是「API 稳定,实现迭代」,YOLO26 延续了这个传统。
新增的配置项主要和双检测头相关。如果你想调整辅助头的权重或者蒸馏参数,可以通过新的配置字段控制。但对大多数用户来说,默认配置就够用了。
内置蒸馏:大模型压缩小模型
除了主模型,Ultralytics 还为 YOLO26 引入了内置蒸馏功能。
知识蒸馏的概念很简单:用大模型(教师)指导小模型(学生)训练,让小模型在保持速度的同时获得更高的精度。以前做蒸馏需要自己写训练脚本,现在 YOLO26 把它集成进了标准训练流程。
from ultralytics import YOLO
# 加载教师模型(大)
teacher = YOLO("yolo26x.pt")
# 加载学生模型(小)
student = YOLO("yolo26n.pt")
# 蒸馏训练
student.train(
data="dataset.yaml",
epochs=100,
teacher=teacher, # 指定教师模型
distill=True
)
这个功能对边缘部署场景很实用。你可以先用 YOLO26-x 在服务器上获得最高精度,然后通过蒸馏把知识迁移到 YOLO26-n,在边缘设备上部署轻量模型但保持接近大模型的效果。
和 RT-DETR 的对比
说 YOLO26 之前,不得不提 RT-DETR。这是目前另一个主流的端到端实时检测器,也是无 NMS 设计。
RT-DETR 基于 DETR 架构改进,用 Transformer 做检测头。它的优点是检测效果好,尤其是在大目标和遮挡场景下;缺点是对小目标不够友好,而且 Transformer 的计算模式对某些硬件不太友好。
YOLO26 走了不同的路线。它保留了 YOLO 的卷积骨干和 FPN 结构,只在检测头上做端到端改造。这样做的好处是:
- 对小目标友好:FPN 的多尺度特征图天然适合检测小目标
- 硬件兼容性好:纯卷积运算,任何支持 CNN 的加速器都能跑
- 迁移成本低:从 YOLOv8/YOLO11 升级几乎不需要改代码
当然,RT-DETR 在某些场景下仍有优势。如果你的任务以大目标为主、对小目标检测要求不高,RT-DETR 可能更合适。但对大多数通用检测任务,YOLO26 的综合表现应该更好。
路线图:3D 感知和 VLM 集成
Ultralytics 在官网路线图里透露了 YOLO 的下一步计划。
YOLO-3D 是他们正在开发的 3D 感知版本,预计在 YOLO Vision 2026 大会上发布。这个版本会把检测能力扩展到三维空间,对自动驾驶和机器人应用很有价值。
另一个方向是 YOLO-VLM,把 YOLO 作为视觉前端接入大语言模型。思路是用 YOLO 做快速的场景理解和目标定位,然后把结构化信息传给 LLM 做高层推理。这样的组合可以兼顾 YOLO 的速度和 LLM 的理解能力。
还有一个有意思的功能是 LLM 驱动的训练分析。简单说就是让 LLM 自动诊断训练过程中的问题,并给出配置优化建议。比如检测到 loss 震荡,自动建议调低学习率;发现小目标 AP 低,建议增加数据增强强度。这种「AI 调参师」的思路挺新颖的。
该不该升级?
如果你正在用 YOLOv8 或 YOLO11,要不要升级到 YOLO26?
推荐升级的场景:
- 边缘部署,对延迟稳定性要求高
- 需要导出完整的端到端模型,不想在推理代码里维护 NMS 逻辑
- 追求最新的精度-速度权衡
- 计划使用蒸馏功能压缩模型
可以观望的场景:
- 现有方案已经稳定运行,没有明显痛点
- 依赖的第三方工具链还没适配 YOLO26
- 对新版本的稳定性有顾虑(等几个小版本迭代)
Ultralytics 官方的建议是:对于新项目,直接用 YOLO26;对于稳定的生产工作负载,YOLO26 和 YOLO11 都是推荐选择。
安装和快速开始
# 安装最新版 ultralytics
pip install -U ultralytics
# 下载预训练模型并测试
yolo detect predict model=yolo26m.pt source=image.jpg
或者用 Python API:
from ultralytics import YOLO
# 加载模型
model = YOLO("yolo26m.pt")
# 推理
results = model("image.jpg")
# 显示结果
results[0].show()
模型会自动下载。首次运行可能需要几分钟,取决于网络情况。
写在最后
YOLO 系列从 2016 年的 v1 到现在的 26,已经迭代了九年。每一代的核心追求都没变:更快、更准、更好部署。
YOLO26 的无 NMS 设计,解决的是一个困扰社区多年的工程问题。它可能不像架构革新那样让人兴奋,但对于每天要和部署打交道的开发者来说,这才是真正有价值的改进。
论文已经发布在 arXiv,代码集成在 ultralytics 库里,有兴趣的可以去试试。
参考来源
- Ultralytics YOLO26:专为边缘计算设计的下一代实时视觉模型 - 知乎 - 详细的技术解析和边缘部署分析


