7B小模型当包工头,Sakana Fugu凭什么叫板Fable 5?

日本AI初创Sakana AI发布多智能体编排系统Fugu,用一个7B参数的"调度员"模型动态调用GPT、Claude、Gemini等全球顶尖大模型。在SWE-Bench Pro等工程基准上超越GPT-5.5和Claude Opus 4.8,官方宣称性能比肩受出口管制的Fable 5。
不是更大的模型,而是更聪明的调度
日本AI初创公司Sakana AI昨天(6月22日)放出了一个让业界侧目的东西:多智能体编排系统Fugu。
这不是又一个千亿参数的巨兽。恰恰相反,Fugu的核心是一个只有7B参数的小模型。它自己不干活,专门指挥别人干活——动态调度GPT-5、Claude Opus 4.8、Gemini 3.1 Pro这些全球顶尖大模型,根据任务类型把子任务分配给最合适的"专家"。
结果呢?在SWE-Bench Pro软件工程基准上,Fugu Ultra拿下73.7分,超过Claude Opus 4.8的69.2分和GPT-5.5的58.6分。在TerminalBench 2.1系统操作测试上,82.1分,同样领先。
更有意思的是Sakana AI的营销姿态:官方声明里直接把"无需承担出口管制风险的前沿能力"当卖点,明摆着在嘲讽Anthropic的Fable 5因为管制问题无法在部分地区使用。
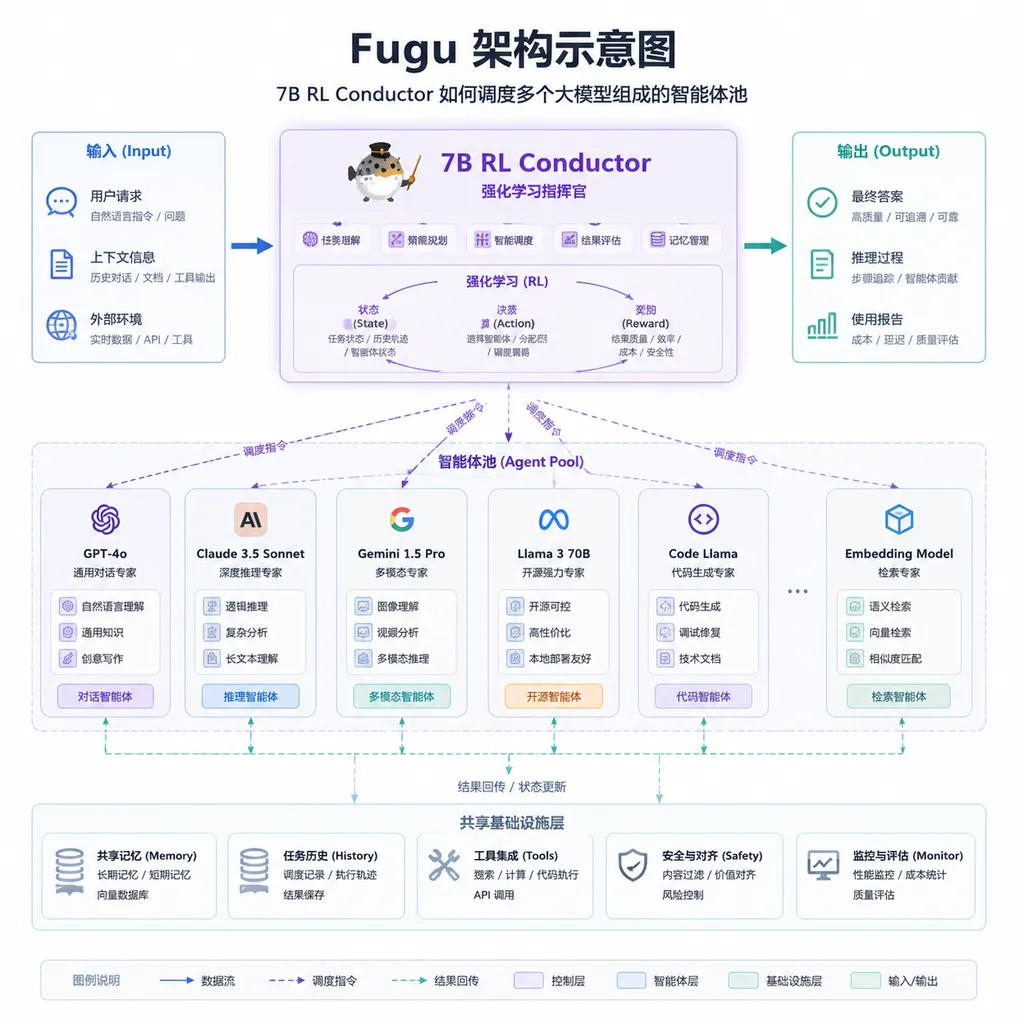
7B参数能做什么?当一个称职的包工头
要理解Fugu的设计逻辑,得先看Sakana AI的处境。
这家公司2023年在东京成立,创始人包括Transformer论文合著者Llion Jones和前Google研究员David Ha。2025年拿到NVIDIA、Google等巨头投资,估值超过25亿美元。但日本本土缺乏中美那样的算力基础设施和数据规模,硬刚千亿参数大模型不现实。
Sakana AI选择了另一条路:不做最强的单体模型,做最聪明的调度系统。
Fugu的架构可以这样理解:
- RL Conductor:一个7B参数的模型,经过强化学习训练,负责分析任务、拆解子任务、选择执行模型、验证结果
- 智能体池:GPT-5、Claude Opus 4.8、Gemini 3.1 Pro等顶尖模型,作为"专家团队"待命
- 单一API:对外封装为兼容OpenAI格式的接口,用户感知不到背后的调度过程
传统大模型是"全能型单体",一个提示词进去,从第一层神经网络算到最后一层,输出结果。这种模式处理简单问题效率极高,但面对复杂的多步骤工程任务,容易出现幻觉或逻辑断裂。
Fugu的思路不同:让专业的人做专业的事。代码审查任务来了,可能同时调用擅长静态分析的模型、擅长逻辑推理的模型、擅长安全审查的模型,多角度交叉验证。这种"专家会诊"模式,自然比单打独斗能发现更多问题。
这背后有学术支撑。ICLR 2026的两篇论文《TRINITY: An Evolved LLM Coordinator》和《Learning to Orchestrate Agents in Natural Language with the Conductor》详细阐述了如何用小参数模型通过强化学习来"指挥"大模型。核心洞察是:Test-time Scaling的算力不一定要花在模型内部的深度推理上,也可以花在外部的调度、验证和合成上。
跑分:超越GPT-5.5和Opus 4.8,宣称比肩Fable 5
Fugu目前提供两个版本:
- Fugu(平衡型):适合日常开发任务
- Fugu Ultra:面向复杂问题,调用更深入的专家智能体池
官方公布的基准测试成绩:
| 基准测试 | Fugu Ultra | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro | |---------|-----------|-----------------|---------|----------------| | SWE-Bench Pro | 73.7 | 69.2 | 58.6 | 54.2 | | TerminalBench 2.1 | 82.1 | 74.6 | 78.2 | - |
SWE-Bench Pro测的是软件工程能力,要求在真实代码库中定位并修复Bug。TerminalBench 2.1测的是系统操作能力。这两项都是偏向真实工程环境的"硬骨头",不是那种容易刷分的选择题基准。
Fugu Ultra在这两项上的领先,说明它在处理复杂工程问题时,比单体模型更少出现中途崩溃或偏离目标的情况。
但争议也在这里:Sakana AI宣称Fugu Ultra在工程与科学基准上与Anthropic的Fable 5和Mythos Preview"比肩"。问题是,Fable 5和Mythos Preview因为出口管制或未完全公开,并没有进入Fugu的智能体池。这个对比是基于各厂商公开的报告分数,而不是同池实测。
开发者社区对此有质疑:不同系统在不同环境下的测试条件难以完全对齐,直接比分数是否公允?但也有人指出,在缺乏统一实测环境的情况下,参考厂商报告数据是行业惯例。
抛开与Fable/Mythos的争议不谈,Fugu对GPT-5.5和Opus 4.8的超越是实打实的同条件对比。而且这种超越不是因为Fugu的底层模型比它们更聪明——Fugu根本不自己生成答案——而是因为RL Conductor在任务分解和专家调度上做得更精准。
实际体验:代码审查、长会话稳定性、渗透测试
Fugu在发布前做了近500名早期用户的Beta测试,反馈揭示了一些有意思的特点。
代码审查的深度
传统单体模型审查代码,往往只能发现表面的语法错误或常见的逻辑漏洞。测试者反馈,Fugu能找出深层次的架构Bug,而其他工具只能发现少数几个表层问题。
原因不难理解:RL Conductor可以同时调用多个专长不同的模型,对同一段代码进行多角度交叉验证。静态分析、逻辑推理、安全审查各司其职。
长会话的稳定性
构建AI Agent产品时,最头疼的问题之一是模型在长会话中的"人设漂移"——随着对话轮数增加,模型会忘记最初的设定,或者在指令遵循上出现偏差。
有企业高管测试后反馈,Fugu在长会话中的Persona异常稳定,几乎不发生漂移。
这得益于架构设计:RL Conductor本身不负责维持长文本的记忆,它只负责在每一轮对话中,根据当前上下文,精准地选择最合适的底层模型来生成回复。"控制与生成分离"避免了单体模型在长上下文中的典型退化。
网络安全的端到端能力
在安全领域的测试中,Fugu能独立完成从侦察、XSS/SQLi漏洞检测到认证审查的全流程,生成完整的渗透测试报告,且严格遵守不越界破坏系统的指令。
这类复杂任务的完成度,依赖于RL Conductor对安全工具链和不同大模型能力的精准编排。单体模型很难在一次推理中覆盖这么多专业领域。
Token效率
传统大模型处理复杂问题时,往往生成冗长的思维链,消耗大量Token。Fugu的RL Conductor通过精准路由,避免了无意义的长CoT消耗。
对于按Token计费的开发者,这意味着成本降低和响应速度提升。
风险:寄居在别人的基础设施之上
说了这么多优点,该泼冷水了。
底层依赖的脆弱性
Fugu的智能体池高度依赖GPT、Claude、Gemini等美国大厂的API。虽然RL Conductor能在某个模型故障或限流时切换到其他模型,但这只是规避了单一供应商风险,并没有脱离整个美国AI基础设施生态。
如果这些底层模型集体涨价、大规模限流或更改API条款,Fugu的成本结构和稳定性将受到直接冲击。这种"寄居"模式在商业化和长期稳定性上存在天然脆弱性。
讽刺的是,Sakana AI把"无需承担出口管制风险"当卖点,但如果美国对底层模型API实施更广泛的管制,Fugu的核心能力来源就会被掐断。
延迟与成本的权衡
多智能体编排必然涉及多次API调用和模型间的通信。对于需要极低延迟的实时交互场景——比如实时语音对话或高频交易辅助——Fugu Ultra的"深度思考与调度"时间可能长于直接调用单体模型。
在对响应速度要求极高的场景中,Fugu的架构优势反而可能成为体验的拖累。
能力上限受底层模型限制
7B的RL Conductor证明了小模型可以成为优秀的指挥官,但它无法凭空创造出底层模型不具备的能力。
如果GPT-5、Claude Opus 4.8都解决不了某个问题,Fugu换着花样调度它们也解决不了。编排系统的能力天花板,终究被底层模型决定。
日本AI的非对称突围
跳出产品本身,Fugu的出现对日本大模型生态有更深层的意味。
日本在全球AI竞赛中处境尴尬:没有美国那样的顶尖算力和前沿算法积累,没有中国那样的庞大数据池和激烈市场竞争,还面临美国前沿模型的出口管制风险。
日本本土不是没有大模型厂商。NTT推出了tsuzumi,ELYZA、Rinna、LLM-jp也在努力训练本土模型。但这些走的是"从头训练"的传统路线,在参数规模和通用能力上很难与中美顶尖模型抗衡。
Sakana AI是其中唯一主打"非对称架构"的实验室。
Fugu的动态路由能力,本质上是在帮日本企业建立一种"AI使用主权"——在算力受限的情况下,与其耗费巨资训练一个各方面都不如GPT-5.5的千亿参数模型,不如训练一个聪明的7B包工头。这个包工头可以根据任务需求灵活接入全球最好的模型。如果某天某个美国模型断供,RL Conductor可以迅速将任务路由到其他可用模型,甚至接入日本本土的专用模型。
这种架构使得日本在AI能力使用上获得了一定程度的自主权和抗风险能力。
但这条路也有天花板。只要底层模型的核心技术仍掌握在少数巨头手中,编排系统的能力上限就会被限制。日本大模型要真正突围,除了在编排架构上创新,仍需在底层算力、核心算法和高质量数据上持续投入。
Fugu是一个精巧的系统级创新,但它不是万能药。
对开发者意味着什么
如果你是开发者,Fugu提供了一个有意思的新选项:
- 复杂工程任务:需要多步骤推理、长链条执行的场景,Fugu的多智能体编排可能比单体模型更稳定
- 供应商风险对冲:不想被某一家模型厂商绑死,Fugu的动态路由提供了一层缓冲
- Token成本优化:精准路由避免无效Token消耗,对高频调用场景有成本优势
但也要清醒认识:
- 底层依赖美国大厂API,这层风险并未消除
- 实时交互场景可能有延迟问题
- 与Fable 5的对比缺乏同池实测,选型时需谨慎
大模型的能力正在逐渐拉平,竞争主战场正在从单纯的参数堆砌转向工具链与落地场景。Fugu代表了一种可能的方向:未来不是比谁的模型更大,而是看谁能把模型"编排"得更好。
这个7B的小包工头,或许正在改变游戏规则。
参考来源
- IT之家:日本 Sakana AI 推出 Fugu - 官方发布消息及基本功能介绍
- 知乎专栏:超越Claude Mythos的AI模型,诞生了? - 技术架构和基准测试详细分析


