OpenAI 放出"抓漏洞专用 AI",把 Claude 按在地上摩擦

OpenAI 昨日发布网络安全专用模型 GPT-5.5-Cyber,在 CyberGym 漏洞检测基准测试中拿下 85.6% 的成绩,超越 Claude Mythos 5 的 83.8%。这是一场针对 Anthropic 的精准狙击。
OpenAI 放出"抓漏洞专用 AI",把 Claude 按在地上摩擦
OpenAI 昨天(6 月 22 日)宣布扩展 Daybreak 网络安全项目,正式向经过审核的安全防御团队开放 GPT-5.5-Cyber 完整版。
这个模型只干一件事:找漏洞、验漏洞、修漏洞。
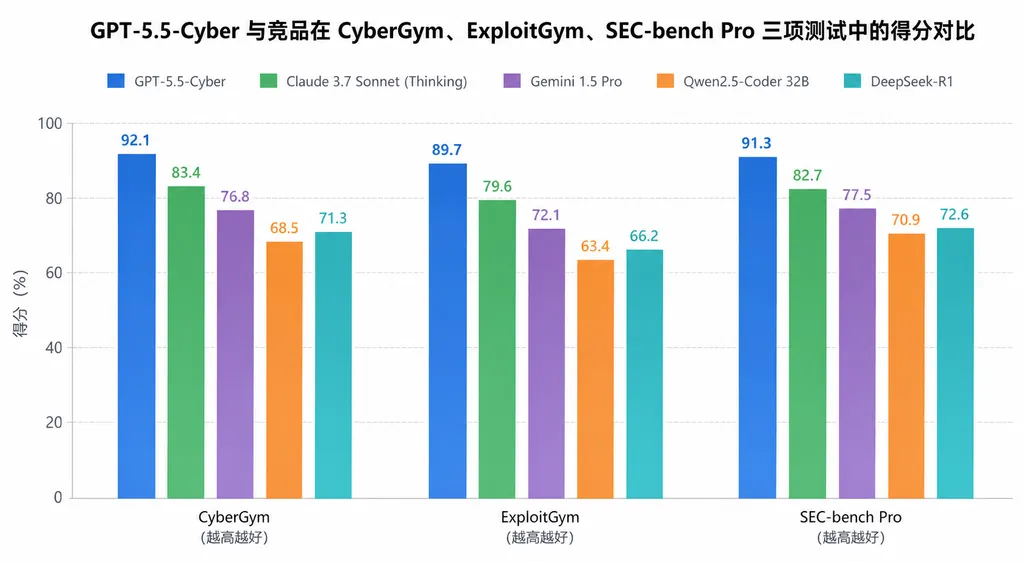
在 CyberGym 基准测试中,GPT-5.5-Cyber 拿下 85.6% 的成绩,刷新了单模型最高纪录。作为对比,Claude Mythos 5 是 83.8%,通用版 GPT-5.5 是 81.8%。
差距不算大,但在安全领域,1.8 个百分点可能就是"能不能在攻击者之前找到那个 0day"的区别。
一、不只是"更能找漏洞",而是整条链路都变快了
安全圈这两年有个共识:AI 加速了漏洞发现,但修复速度没跟上。
以前的痛点是"找不到",现在的痛点是"找到了修不完"。一个中型企业的安全团队,每周可能收到几百个漏洞报告,评估影响、写修复代码、跑测试、发补丁——这条链路依然靠人肉。
GPT-5.5-Cyber 瞄准的就是这个环节。
根据 OpenAI 的说法,这个模型在三个场景做了专项优化:
1. 漏洞识别与分级
通用模型在处理安全任务时,内置的安全防护机制会"过度谨慎"。比如你让 GPT-5.5 分析一段可能存在 SQL 注入的代码,它可能会先给你上一堂"什么是 SQL 注入"的课,然后小心翼翼地说"这段代码存在潜在风险"。
GPT-5.5-Cyber 的做法是:直接告诉你这是 CVE 多少号的变种,影响范围是什么,修复优先级建议是 P 几。
这个区别对安全团队来说是质变。他们不需要 AI 当老师,需要的是一个能并肩作战的同事。
2. 补丁验证
写补丁容易,验证补丁难。
一个漏洞可能有十几种利用路径,你修了一条,另外九条还敞着口子。传统做法是人工写 PoC(Proof of Concept,概念验证代码)逐一测试,耗时且容易遗漏。
GPT-5.5-Cyber 可以自动生成多条利用路径的 PoC,验证补丁是否真的堵死了所有入口。
3. 恶意软件分析
这个场景对模型的要求最高。恶意软件经常使用混淆、加壳、反调试等技术,静态分析基本看不出什么。
根据 ExploitGym 测试的成绩,GPT-5.5-Cyber 在"将已知漏洞转化为可执行攻击代码"这个任务上得分 39.5%,而通用版 GPT-5.5 只有 25.95%。
提升了 50% 以上。
这意味着模型不仅能理解漏洞原理,还能"像攻击者一样思考",知道这个漏洞实际上怎么用、用起来有多容易。
二、跟 Claude Mythos 的正面对决
明眼人都看得出来,这次发布的时机不是巧合。
一个月前,Anthropic 发布了 Claude Mythos Preview,专门针对网络安全场景优化,作为其 Project Glasswing 项目的一部分。那次发布引发的关注度相当高——美联储主席鲍威尔、财长贝森特专门召集华尔街大行的 CEO 开会讨论这个模型对金融系统的影响。
副总统万斯甚至跟科技巨头的 CEO 们开了电话会议。
一个 AI 模型能让这么多大人物紧张,说明它确实展示了某些让人不安的能力。
OpenAI 显然不想把"AI 安全专家"这个赛道让给 Anthropic。GPT-5.5-Cyber 的发布,是一次精准的战略反击。
从测试成绩看,OpenAI 确实扳回了一城:
| 模型 | CyberGym | ExploitGym | SEC-bench Pro | |------|----------|------------|---------------| | GPT-5.5-Cyber | 85.6% | 39.5% | 69.8% | | Claude Mythos 5 | 83.8% | - | - | | GPT-5.5(通用版)| 81.8% | 25.95% | 63.1% |
(注:Claude Mythos 5 在 ExploitGym 和 SEC-bench Pro 上的公开成绩暂未查到)
但成绩只是一方面。更关键的是生态和分发能力。
Anthropic 的 Mythos 目前只向特定企业开放,走的是"精英路线"。OpenAI 的 Daybreak 项目则更开放一些——任何安全团队都可以申请加入 Trusted Access for Cyber 计划,通过审核就能拿到访问权限。
对于大多数企业安全团队来说,能不能用上比谁更强更重要。
三、技术细节:Cyber 版本到底改了什么?
根据已公开的信息,GPT-5.5-Cyber 和通用版 GPT-5.5 的区别主要在三个层面:
安全任务限制的放宽
通用版 GPT-5.5 有很多"护栏",防止用户把它当成攻击工具。比如你问它"怎么写一个 SQL 注入的 payload",它大概率会拒绝。
但对于合法的安全研究人员来说,这些护栏是障碍。他们需要模型能够"像攻击者一样思考",才能更好地防御。
GPT-5.5-Cyber 在定向训练后,放宽了这些限制——但只针对经过审核的用户,而且只在特定上下文中生效。
这是一个微妙的平衡。OpenAI 需要让模型足够"危险"以便有用,又不能让它变成脚本小子的武器。
安全领域的专项微调
从 SEC-bench Pro 的成绩可以推测,GPT-5.5-Cyber 在以下数据上做了额外训练:
- 大量 CVE(通用漏洞披露)数据库条目及其关联的技术分析
- 渗透测试报告和红队演练记录
- 安全研究论文和漏洞利用代码库
- 补丁提交记录和代码审查意见
SEC-bench Pro 测试的是"在复杂软件目标上的长期漏洞发现能力和概念验证生成能力"。GPT-5.5-Cyber 比通用版高出 6.7 个百分点,说明它在理解真实世界软件架构方面有明显优势。
Agent 能力的强化
OpenAI 在博文中提到,GPT-5.5-Cyber 可以"在授权的真实目标上执行渗透测试和漏洞验证"。
这意味着它不只是一个问答机器人,而是可以作为 Agent 自主执行多步骤任务:
- 扫描目标系统
- 识别潜在漏洞
- 生成利用代码
- 验证漏洞是否真实存在
- 评估影响范围
- 生成修复建议
整个链路都可以自动化,人类只需要在关键节点做决策。
四、谁能用?怎么用?
这不是一个面向普通用户的产品。
想要获取 GPT-5.5-Cyber 的访问权限,你需要:
-
申请加入 Trusted Access for Cyber 计划:OpenAI 会审核你的身份和用途,确保你是合法的安全研究人员或企业安全团队成员。
-
完成账户安全升级:在 6 月 1 日前为 ChatGPT 账户安装进阶安全保护措施(这个 deadline 可能已经过了,最新要求需要查看官方文档)。
-
同意使用条款:包括不将模型用于攻击未授权目标、不分享访问权限等。
审核通过后,你可以通过 API 调用 GPT-5.5-Cyber。
对于国内开发者来说,直接访问 OpenAI API 可能存在网络问题。如果你的团队需要使用这个模型,可以考虑通过 OpenAI Hub 这样的 API 聚合平台来调用——它兼容 OpenAI 格式,国内直连,省去折腾网络的麻烦。
调用方式和标准 OpenAI API 一致:
import openai
client = openai.OpenAI(
api_key=\"你的 OpenAI Hub API Key\",
base_url=\"https://api.openai-hub.com/v1\"
)
response = client.chat.completions.create(
model=\"gpt-5.5-cyber\", # 模型名称以 OpenAI Hub 实际支持为准
messages=[
{
\"role\": \"system\",
\"content\": \"你是一个专业的安全研究员,帮助分析代码中的潜在漏洞。\"
},
{
\"role\": \"user\",
\"content\": \"\"\"分析以下代码的安全风险:
def get_user(user_id):
query = f\"SELECT * FROM users WHERE id = {user_id}\"
return db.execute(query)
\"\"\"
}
]
)
print(response.choices[0].message.content)
五、这对安全行业意味着什么?
长远来看,AI 正在重塑整个网络安全行业的攻防格局。
攻击门槛在降低
以前,发动一次复杂的网络攻击需要深厚的技术功底和大量时间。现在,一个对安全一知半解的人,借助 AI 工具也能生成相当专业的攻击代码。
这不是危言耸听。ExploitGym 测试的本质就是"AI 能不能把漏洞信息转化成可执行的攻击"——GPT-5.5-Cyber 在这项测试中得分 39.5%,意味着它已经具备相当的攻击代码生成能力。
防御效率在提升
好消息是,防御方同样受益。
一个配备了 GPT-5.5-Cyber 的安全团队,可以在几分钟内完成过去需要几天的漏洞分析工作。补丁验证从人工测试变成自动化流水线。恶意软件分析从"看代码猜意图"变成"直接问 AI 这东西想干什么"。
效率的提升是数量级的。
但技术差距可能拉大
问题在于,这些强大的工具不是所有人都能用。
OpenAI 和 Anthropic 都采用了严格的准入机制,只向经过审核的团队开放访问权限。这意味着资源充足的大企业和国家级安全机构能用上最先进的防御工具,而小企业和欠发达地区的组织只能用通用模型凑合。
安全领域的马太效应可能会加剧。
监管压力在增加
这也解释了为什么美国政府对这些模型如此关注。
当一个 AI 模型能够自动发现漏洞、生成攻击代码、甚至自主执行渗透测试时,它就不再只是一个软件工具,而是一种需要被管控的"能力"。
OpenAI 在发布 GPT-5.5-Cyber 之前,专门向白宫、商务部、国会委员会做了演示。这不只是公关行为,更是在为未来的监管合作铺路。
可以预见,针对 AI 安全工具的专项监管很快就会出台。
六、冷静看待:85.6% 意味着什么?
最后说一个容易被忽略的点。
85.6% 的 CyberGym 成绩确实是目前最高的,但这也意味着还有 14.4% 的漏洞它找不到。
在网络安全领域,这 14.4% 可能正是最危险的那部分——那些隐蔽的、非常规的、需要深度上下文理解的漏洞。
AI 是强大的辅助工具,但它不能替代有经验的安全专家的直觉和判断。
现阶段最好的模式是人机协作:AI 负责海量筛查和常规任务,人类专家负责最后的决策和那些 AI 搞不定的边缘情况。
把 AI 当成"超级实习生",而不是"可以躺平的理由",这个心态很重要。
GPT-5.5-Cyber 的发布,标志着 AI 安全工具从"实验品"走向"生产力工具"的关键一步。OpenAI 和 Anthropic 的竞争,最终受益的是整个安全行业。
但别忘了,攻击者也在用同样的技术进化。这场 AI 驱动的攻防升级,才刚刚开始。
参考来源
- IT之家:超 Claude Mythos 5 成绩,OpenAI 最强"抓虫 AI"GPT-5.5-Cyber 刷新 CyberGym 纪录 - 详细报道了 GPT-5.5-Cyber 在各项基准测试中的成绩
- 知乎专栏:OpenAI 面向网络安全团队发布 GPT-5.5-Cyber 限量预览版 - 分析了该模型的定位和与 Anthropic 的竞争关系


