即梦音乐生成1.0上线,6分钟音频一键生成

即梦App悄然上线音乐生成模块,搭载全新1.0音乐生成模型,支持最长6分钟音频输出。这是字节在AI内容生成领域的又一次补全,从视频到音乐,即梦正在构建完整的AI创作闭环。
即梦音乐生成1.0上线,6分钟音频一键生成
字节跳动旗下的即梦App悄然上线了音乐生成模块,搭载全新的1.0音乐生成模型,支持最长6分钟的音频生成。
没有发布会,没有预热海报,这个功能就这样静默地出现在了即梦App的功能列表里。
6分钟,够干什么?
6分钟的音频生成时长,在当前AI音乐赛道里算是第一梯队。作为对比,Suno目前支持最长4分钟,Udio是2分钟。即梦这个1.0版本直接拉到6分钟,足够覆盖一首完整歌曲的长度。
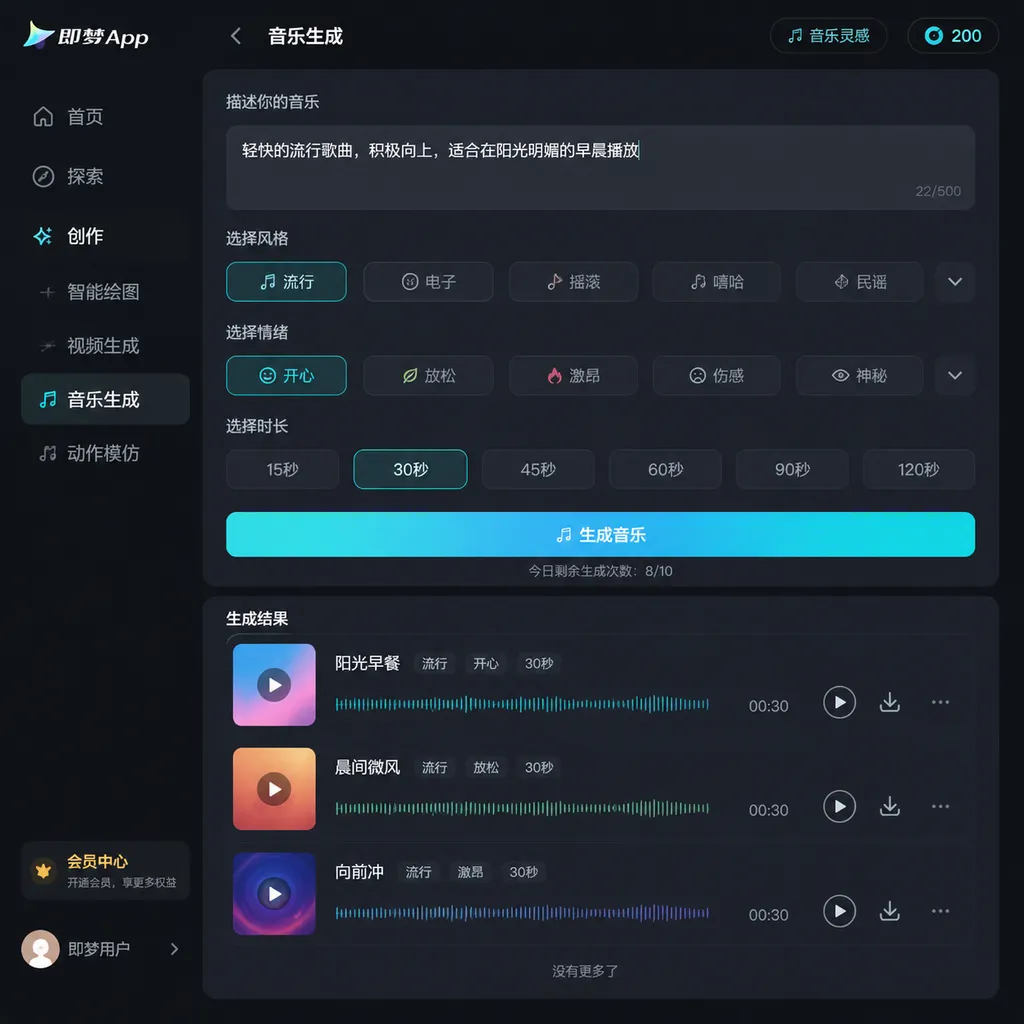
对于短剧、短视频创作者来说,这个时长意味着可以一次性生成完整的背景音乐,而不需要拼接多段。对于想做AI音乐MV的人来说,配合即梦自家的Seedance视频生成能力,理论上可以在一个App内完成从音乐到画面的全流程。
有开发者已经在尝试「DeepSeek写词+即梦生成音乐+即梦生成MV」的工作流,据称10分钟内就能产出一条带原创音乐的MV。当然,质量如何是另一回事。
字节的内容生成拼图
回看字节在AI内容生成领域的布局,这次音乐模块的上线补上了最后一块重要拼图。
文本生成:豆包,已经是国内月活最高的AI对话产品之一
图像生成:即梦的图像模型,从早期的尝试到现在已经相当成熟
视频生成:Seedance系列,特别是今年爆火的Seedance 2.0,在AI视频领域打出了声量
音乐生成:现在有了1.0音乐模型
这意味着什么?一个创作者理论上可以在字节的产品矩阵内完成从创意到成品的全部工作,不需要在多个平台之间跳转。
这和字节一贯的产品策略一脉相承——通过产品矩阵形成闭环,把用户留在自己的生态里。抖音、剪映、即梦、豆包,再加上火山引擎的API服务,从C端到B端,从创作到分发,链条正在逐渐完整。
AI音乐赛道的现状
说实话,AI音乐生成这个赛道在国内一直不温不火。
海外有Suno、Udio两个明星产品,今年都拿到了不小的融资。Suno在3月刚完成新一轮融资,估值据传已经超过10亿美元。用户基数和商业化进展都走在前面。
国内做AI音乐的公司不少,但大多还停留在小众圈子里。网易天音、昆仑万维的天工音乐、还有一些创业公司的产品,都在做,但都没有破圈。
原因不复杂:
-
版权问题悬而未决。AI生成的音乐能不能商用?训练数据的版权归属怎么算?这些问题在全球范围内都没有明确答案。Suno和Udio都在面临版权诉讼。
-
商业场景有限。AI音乐目前最大的用途是短视频BGM,但这个场景对音乐质量的要求不高,付费意愿也不强。
-
技术瓶颈明显。AI生成的音乐在情感表达、结构完整性、风格一致性上都还有明显差距。听个响可以,要当正经作品还差得远。
字节做音乐生成,最大的优势不在技术,而在场景。抖音上每天有海量的短视频需要BGM,剪映的用户需要配乐,即梦生成的视频需要音轨。自己做一个音乐生成模型,可以降低对外部音乐库的依赖,也可以提供差异化的创作体验。
1.0版本,意味着什么
「1.0」这个版本号本身就传递了一个信息:这是正式版,不是实验性功能。
有意思的是,豆包App什么时候会接入这个音乐生成能力?目前还不知道。参考即梦和豆包之前的联动模式,大概率会在模型稳定后逐步打通。豆包作为字节AI产品的主入口,用户基数更大,但对模型稳定性的要求也更高。
从产品迭代的角度看,字节的AI产品一直在「静默升级」。豆包的版本更新很少大张旗鼓地宣传,但功能确实在一点点变强。即梦这次上线音乐生成也是类似的风格——先上线,让用户用起来,根据反馈再迭代。
音视频联合生成:下一个战场
Seedance 2.0之所以能在今年初引爆全网,一个关键能力就是「声画同出」——模型可以一次性生成画面和对应的音效,声音和画面是同步的,不需要后期配音。
这个能力在AI视频领域是个重要突破。传统的AI视频工作流是:先生成画面,再配音效/音乐。两个步骤,两套工具,中间还要人工对齐。Seedance 2.0把这个过程合并了,效率提升明显。
但Seedance 2.0的「声画同出」主要是音效层面,不是音乐层面。你可以生成脚步声、环境音、对话口型,但不能生成一段配合画面情绪的背景音乐。
现在即梦有了独立的音乐生成模型,下一步很可能是把视频生成和音乐生成打通,实现真正意义上的「音视频联合生成」——输入一段文字描述,输出一段带有原创BGM的视频。
这个方向可灵也在做。快手在今年的产品更新中提到了音视频协同生成的能力,但具体效果还没有大规模开放。
谁先把这个能力做到好用,谁就能在AI短剧、AI广告这些场景里占到先机。
对创作者意味着什么
如果你是短视频创作者、短剧制作者,或者做自媒体内容的人,即梦这个音乐生成功能值得关注。
好处是显而易见的:
- 不用再到处找免费BGM,担心版权问题
- 可以生成和视频内容匹配的定制化音乐
- 如果和Seedance联动,工作流会更顺畅
但也有明显的局限:
- 1.0版本,质量上限不会太高
- 风格和可控性目前还是未知数
- 商用授权条款需要仔细看
我的建议是:可以尝试,但不要完全依赖。AI生成的音乐在短视频BGM这个场景已经够用了,但如果你对音乐质量有较高要求,或者要用在正式的商业项目里,最好还是和专业音乐制作结合使用。
AI内容生成的下半场
从更宏观的视角看,AI内容生成正在进入一个新阶段。
上半场的关键词是「单点突破」:文本模型、图像模型、视频模型、音乐模型,各自独立发展,各自证明自己的能力。
下半场的关键词是「多模态融合」:不同模态的生成能力开始整合,用户输入一个需求,AI输出一个完整的内容成品。
字节的布局已经很清楚了:豆包做入口和文本,即梦做视觉和音频,火山引擎做API服务,抖音和剪映做分发和工具。每一块都不是最强的,但组合起来形成闭环。
这种打法对于那些只做单点的公司会形成压力。一个创业公司可能在音乐生成上做得比即梦好,但如果即梦的音乐生成「够用」,而且和视频生成、分发渠道打通了,用户为什么要多开一个App?
写在最后
即梦1.0音乐生成模型的上线,本身不是一个多大的新闻。没有技术上的重大突破,没有惊人的效果展示,只是一个产品功能的补全。
但它的意义在于:字节在AI内容生成领域的拼图又完整了一块。
当一家公司同时拥有文本、图像、视频、音乐的生成能力,并且这些能力可以在一个产品里联动使用,用户体验和工作效率的提升是显著的。
对于开发者来说,如果你在做AI相关的内容创作工具,字节的这套组合拳是需要认真研究的竞争对手。对于创作者来说,多一个选择总是好事,不妨试试看。
至于音乐生成本身能做到什么程度,等更多用户实测之后再下结论不迟。1.0版本嘛,期待可以有,但别太高。
参考来源
- 即梦app上线音乐生成模块 最长6分钟 全新1.0音乐生成模型 - Linux.do社区讨论帖,首发消息来源
- AI音乐杀疯了!DeepSeek+即梦,10分钟生成原创音乐MV - 知乎专栏,即梦AI音乐创作工作流实践分享


