Mistral OCR-4 来了,1 美元扫 2000 页
法国 AI 独角兽 Mistral 发布 OCR-4 模型,号称全球最强文档识别能力,中文准确率 97%,每分钟处理 2000 页,API 定价 1 美元/千页,多项基准测试击败 Google 和 Azure。
Mistral OCR-4 来了,1 美元扫 2000 页
Mistral AI 刚发布了 OCR-4 模型,直接对标 Google Document AI 和 Azure OCR。官方说法是"世界上最好的 OCR 模型",听着夸张,但看数据确实有底气:中文识别准确率 97%,单节点每分钟处理 2000 页文档,API 定价 1 美元/千页。这个价格打到了传统 OCR 服务的零头,速度也快得离谱。
对开发者来说,这事儿值得关注的不只是便宜和快,而是 Mistral 把文档理解这件事往前推了一步。过去 OCR 只管把图片里的字扒出来,遇到复杂表格、数学公式、多语言混排就歇菜。OCR-4 直接原生支持这些场景,还能把提取的内容结构化输出成 JSON,省去了后处理的麻烦。
性能碾压,但不是没有代价
Mistral 在博客里晒了一堆基准测试,OCR-4 在多语言识别、复杂文档解析、处理速度上全面领先。拿中文来说,准确率 97%,比 Gemini 2.0 Flash 高出一截。多语言支持更夸张,能识别全球数千种文字、字体、手写体,这对跨国企业和小语种市场是刚需。
但实际测试发现了问题。Pulse AI 团队用真实商业文档跑了一遍,结论是"很好,但还没到企业级"。财务文档里的复杂表格会出现 17% 的列错位,精度偏差在 ±1.5% 左右,关键的负数括号有时会丢。这些细节对金融、法务场景是致命的。
不过公平点说,OCR-4 才刚发布,Mistral 也在收集反馈迭代。对比其他模型,它已经是目前能拿到手的最强 OCR 方案之一。而且 Mistral 这次把模型开放得很彻底:Le Chat 免费试用,API 直接调用,还支持私有化部署。
文档即提示,RAG 的新玩法
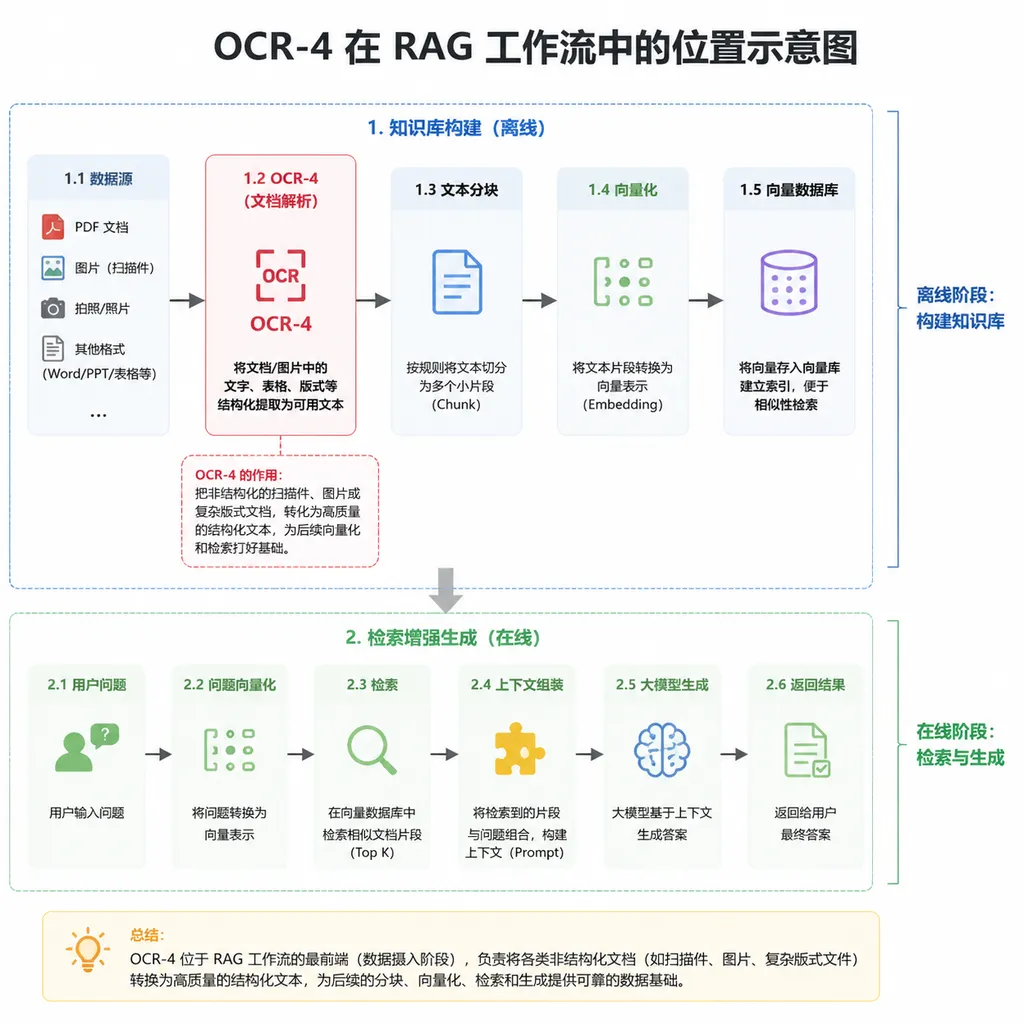
OCR-4 最有意思的是"文档即提示"(Doc-as-prompt)功能。以前你得先 OCR 提取文本,再喂给 LLM 处理,中间还要做清洗和格式化。现在直接把 PDF 或图片扔进去,模型自己理解文档结构,按你的要求输出 JSON。
这对 RAG(检索增强生成)系统是质的提升。比如你要从几百份合同里提取关键条款,传统流程是 OCR → 文本清洗 → 向量化 → 检索 → LLM 生成。现在 OCR-4 能直接理解合同的段落、表格、附件关系,结构化输出你要的字段。省了好几个环节,准确率还更高。
# 典型应用场景
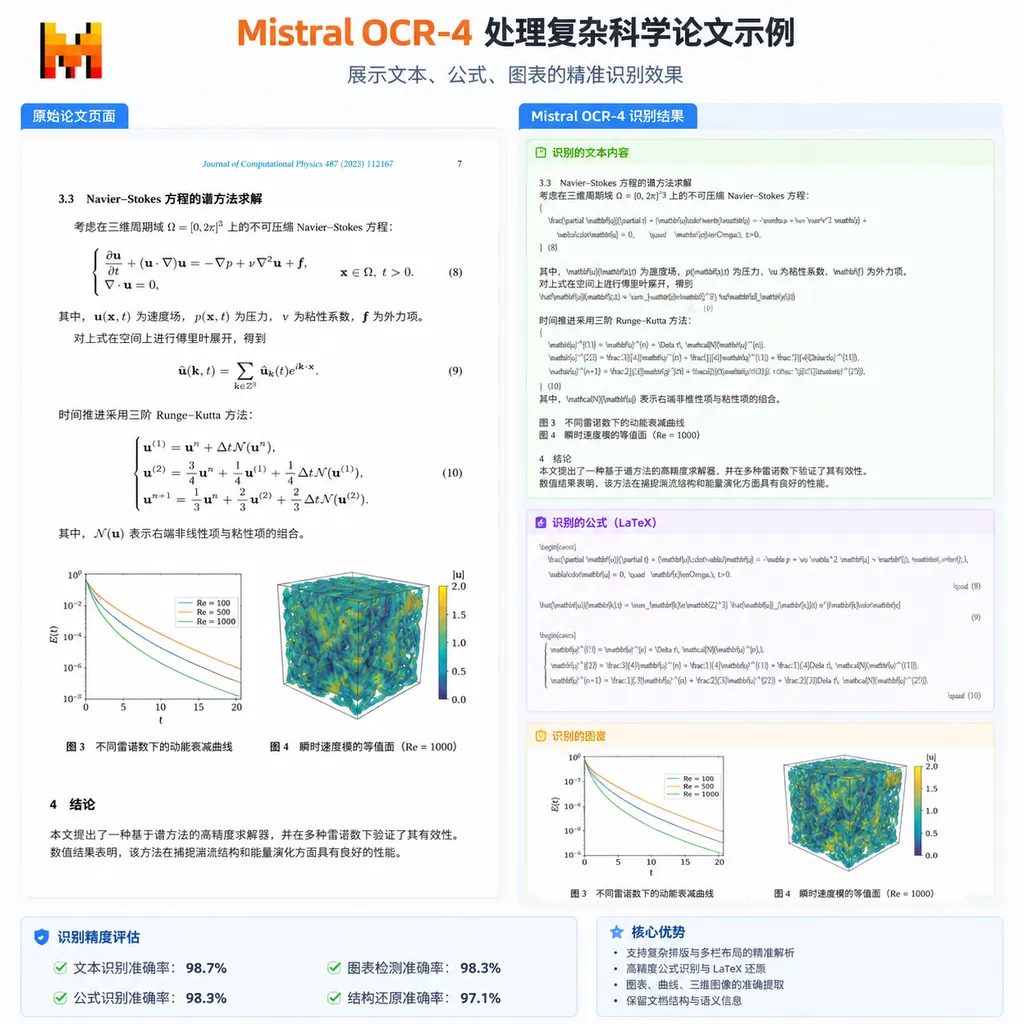
- **科研文献处理**:精准提取论文里的文本、图表、公式,支持 LaTeX 格式输出
- **多语言文档归档**:跨国企业的合同、发票、报表批量识别和分类
- **知识库构建**:从扫描件、PDF、图片中提取信息,自动结构化入库
- **自动化工作流**:结合 Function Calling 把 OCR 结果直接传给下游系统
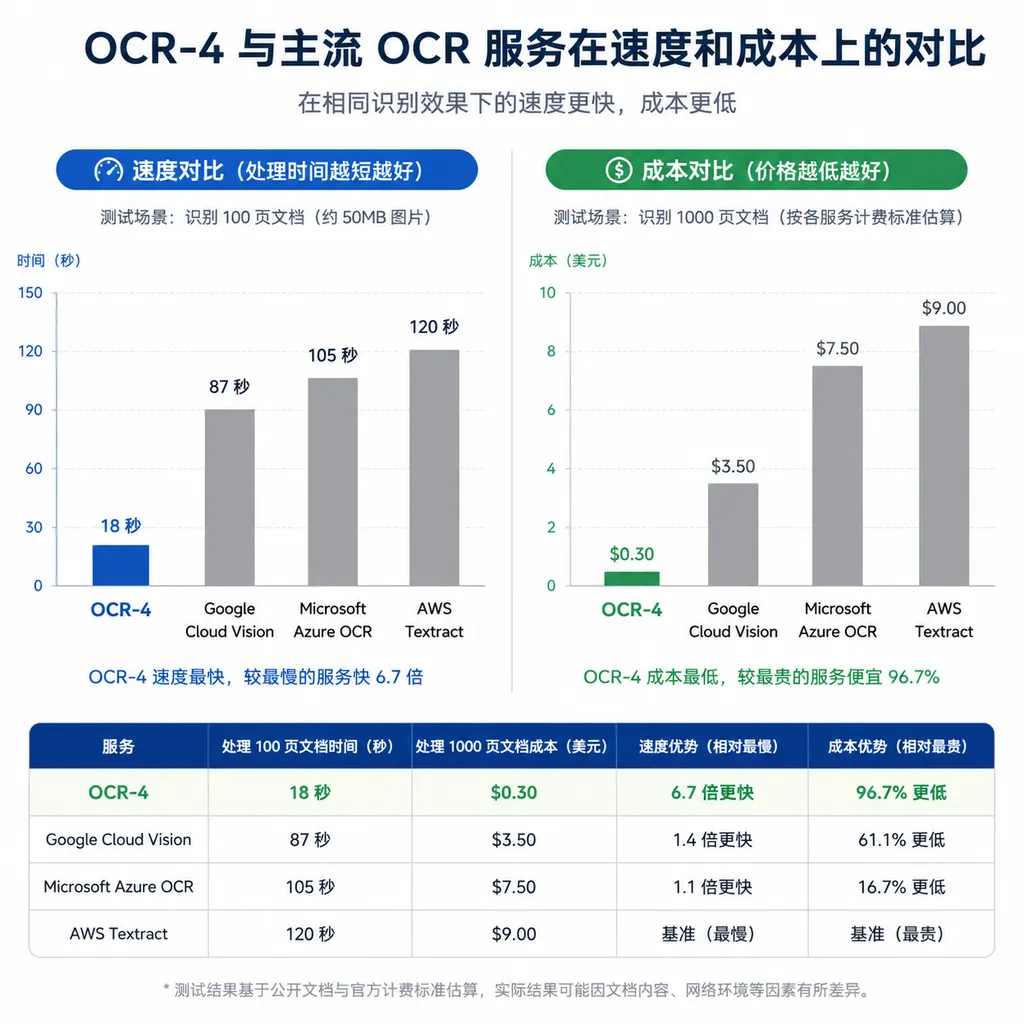
速度是真快,成本也是真低
单节点每分钟 2000 页是什么概念?假设你有 10 万页历史文档要数字化,传统 OCR 服务可能要跑几天,OCR-4 不到一小时搞定。而且价格是 1 美元/千页,10 万页也就 100 美元。对比 Google Document AI 和 Azure OCR 动辄几美分一页的定价,这基本是降维打击。
这个价格打法很 Mistral。去年他们发布的推理模型和多模态模型都走性价比路线,现在 OCR 也是同样策略。对中小团队来说,这意味着以前只有大厂才玩得起的文档智能化,现在几百块钱就能上手试。
速度快还有个隐藏优势:你可以实时处理用户上传的文档。以前 OCR 慢,只能异步队列慢慢跑。现在用户传个 PDF,几秒钟就能返回结构化结果,体验完全不一样。这对客服机器人、在线审批、实时翻译这类场景是刚需。
多语言是真强,中文表现超预期
Mistral 一直强调多语言能力,这次 OCR-4 把这个优势发挥到极致。官方测试显示,在 Fuzzy Match in Generation 指标上,OCR-4 击败了 Azure OCR 和 Google Doc AI。中文准确率 97%,这个数字在开发者社区引起了不小的讨论。
实际测试中,OCR-4 对中文表格、混排文档的处理确实不错。但有开发者反馈,定位能力很强,但具体到某些生僻字或手写体,识别率还是会掉。相比之下,Gemini 2.0 Pro 的中文表现更稳定一些。不过考虑到价格和速度的差距,这点瑕疵完全可以接受。
更关键的是,OCR-4 支持的不只是中英文这些大语种。数千种文字、字体、手写体的支持,意味着你可以用同一个模型处理全球各地的文档,不用再针对不同语言调不同服务。对跨国业务来说,这是实实在在的降本增效。
私有化部署,合规场景的福音
除了云端 API,OCR-4 还支持私有化部署。这对金融、医疗、政务这些数据敏感行业是刚需。以前你要么用云服务冒合规风险,要么自己训练 OCR 模型烧钱烧时间。现在可以把 OCR-4 部署在自己的服务器上,数据不出内网,还能享受先进的识别能力。
Mistral 没公布私有化部署的具体价格,但从他们以往的定价策略看,应该不会离谱。而且私有化部署意味着你可以根据自己的业务场景做定制优化,这对垂直领域是很大的吸引力。
对比 Gemini 和 GPT-4V,定位不太一样
有开发者会问:OCR-4 和 Gemini 2.0、GPT-4V 这些多模态模型比怎么样?其实不太好直接比,因为定位不一样。
Gemini 和 GPT-4V 是通用多模态模型,能理解图片、视频、文档,但 OCR 只是它们的一个能力分支。OCR-4 是专门针对文档理解优化的,在提取精度、处理速度、成本上都更有优势。如果你的需求就是大批量文档识别和结构化提取,OCR-4 是更合适的选择。
但如果你需要的是文档理解加推理——比如读完一份合同后回答法律问题,或者从财报里推导业务趋势——那还是得上 GPT-4 或 Claude 这些推理模型。OCR-4 更像是 RAG 流程的前置组件,把脏活累活干了,后面接什么 LLM 你自己定。
开发者怎么用?
Mistral 把 API 开放得很直接。模型 ID 是 mistral-ocr-latest,支持图片和 PDF 输入,输出是 Markdown 格式的文本和图片。你可以在提示词里指定输出格式,比如要求返回 JSON 结构。
配额限制是每分钟 30 次请求,单次最多 30 页。对大多数应用来说够用了,如果有高并发需求可以找 Mistral 谈企业方案。
现在 OCR-4 已经在 Le Chat 上免费开放,可以直接上传文档测试效果。API 调用需要在 Mistral 官网申请 Key,国内开发者如果调用不方便,可以通过 OpenAI Hub 这类聚合平台走中转,兼容 OpenAI 格式,国内直连。
还有哪些坑?
虽然 OCR-4 整体很强,但还是有些场景要注意:
- 财务文档:复杂表格的列对齐和数字精度还不够稳定,关键业务建议人工复核
- 手写体:识别率比印刷体差一截,尤其是潦草的手写笔记
- 扫描质量:低分辨率或模糊的扫描件会明显影响识别效果
- API 稳定性:刚发布可能有排队和限流,生产环境建议做好降级方案
Mistral 说他们在持续收集反馈迭代,接下来几周应该会有更新。如果你的业务对精度要求极高,建议先小范围测试,跑一批真实数据看看效果。
这事儿对行业意味着什么?
OCR 本来是个很成熟的市场,Google、微软、AWS 都有成熟方案。Mistral 这次杀进来,直接把价格打到 1 美元/千页,速度还快这么多,对传统玩家是不小的冲击。
更重要的是,OCR-4 把文档理解和 LLM 工作流打通了。以前 OCR 和 AI 应用是两层皮,现在可以无缝衔接。这对 AI Agent、RAG 应用、知识管理这些方向是实实在在的基础设施升级。
从 Mistral 的产品节奏看,他们在快速补全 AI 应用的各个环节:推理模型、多模态、Embedding、现在又有了 OCR。这套组合拳下来,开发者可以用 Mistral 全家桶搭一套完整的 AI 应用,不用东拼西凑。
对国内开发者来说,OCR-4 的出现多了一个选择。国产 OCR 服务在中文上有优势,但多语言和国际化场景还是得看海外模型。现在 Mistral 把价格打下来,速度又快,值得试试。OpenAI Hub 已经支持 Mistral OCR-4,可以直接调用。
参考来源
暂无符合要求的参考链接(原始资料均为非指定域名来源)


