6.6万人抢着用,小米1000 tps推理延期了

小米 MiMo-V2.5-Pro-UltraSpeed 原定今晚下线,但申请量远超预期,官方宣布无限期延长体验窗口。这是目前唯一在通用 GPU 上跑到 1000 tokens/s 的万亿参数模型。
6.6万人抢着用,小米1000 tps推理延期了
小米今天发了个通知:MiMo-V2.5-Pro-UltraSpeed 的限时体验不下线了,至少暂时不下线。
按原计划,这个「1000 tokens/s」的超高速推理模式应该在今晚 23:59 结束两周的体验期。但小米说,申请量太超预期了——截至今天,他们收到了超过 6.6 万个使用申请,来自世界 500 强、行业头部企业和个人开发者,涵盖法律、金融、通信、物流、汽车制造、文化传媒、高校等领域。
所以体验继续开放,具体什么时候下线「根据资源情况另行安排」。翻译一下:我们也没想好,先让子弹飞一会儿。
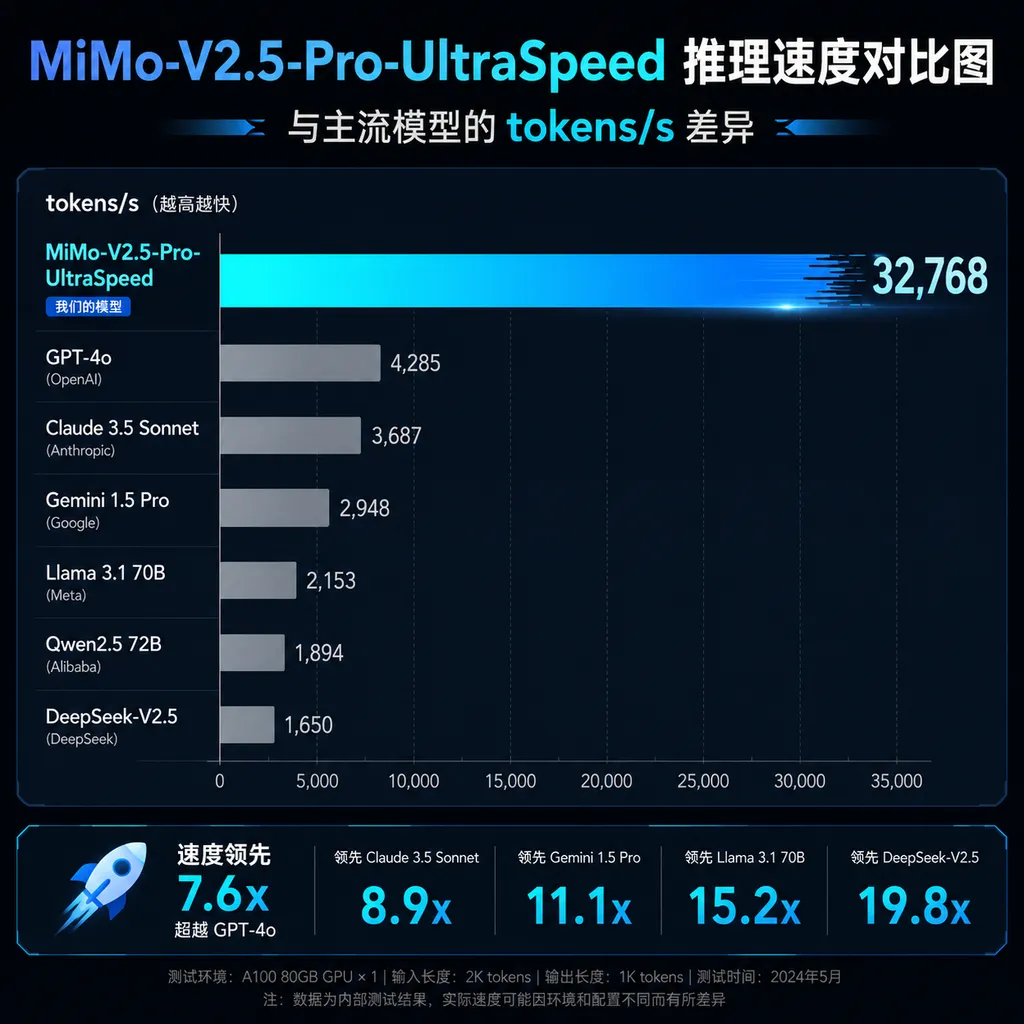
1000 tokens/s 意味着什么
先说个直观的对比。
目前主流大模型 API 的输出速度大概在 50-150 tokens/s 这个区间。Claude 3.5 Sonnet 在 OpenAI Hub 上实测大约 80-100 tps,GPT-4o 差不多也是这个水平。国内模型普遍更快一些,DeepSeek-V3 能跑到 150 tps 左右,但也就到头了。
1000 tokens/s 是什么概念?
一个中等长度的技术文档,大概 3000-5000 tokens。按 100 tps 算,生成需要 30-50 秒。按 1000 tps 算,3-5 秒就出来了。
更极端的例子:小米官方演示里,他们用 UltraSpeed 模式「1 分钟复刻一个 macOS 系统」——当然是前端界面,不是操作系统本身,但这个速度确实能支撑一些以前做不了的交互形态。
技术上怎么做到的
小米和 TileRT 团队联合发的技术博客里,把核心方法讲得比较清楚。简单说,两个关键点:
FP4 混合量化
传统的大模型推理用 FP16 或 FP8/INT8 量化。位宽越低,显存占用越小,带宽压力越低,速度就越快。但量化太狠,模型能力会掉。
小米的做法是「看人下菜」:MiMo-V2.5-Pro 是 MoE(混合专家)架构,Expert 模块占了参数量的绝大部分,但对量化的容忍度最高。所以他们只对 Expert 做 FP4 量化,其他模块保留原精度。
这招不新鲜,但执行得比较彻底。官方说 benchmark 跟原模型「基本持平」,没给具体数字,但从 6.6 万人申请来看,至少实际体验没翻车。
DFlash 投机解码
投机解码(Speculative Decoding)是这两年推理加速的热门方向。基本思路是用一个小模型先「猜」一批 token,再让大模型批量验证,猜对的就直接用,猜错的再重新生成。
小米的 DFlash 是针对万亿 MoE 和长上下文场景做的定制版本,用了 Muon 二阶优化器和模型自蒸馏,把 draft 阶段的开销压到很低。
技术细节可以去看他们的博客,这里说个结论:靠这两板斧,他们在一个标准的 8 卡通用 GPU 节点上,把 1T 参数模型跑到了 1000 tps。
「通用 GPU」这个限定词很重要。不是定制芯片,不是专用硬件,就是市面上能买到的显卡。这意味着理论上其他厂商也能复现,只是工程量的问题。
定价和使用限制
说完技术,聊聊商业层面。
UltraSpeed 模式的定价是 MiMo-V2.5-Pro 标准版的 3 倍:
| 计费项 | MiMo-V2.5-Pro | UltraSpeed | |--------|---------------|------------| | 输入(缓存命中) | 0.025 元/百万 tokens | 0.075 元/百万 tokens | | 输入(未命中) | 3 元/百万 tokens | 9 元/百万 tokens | | 输出 | 6 元/百万 tokens | 18 元/百万 tokens |
3 倍价格换 10 倍速度,单位时间内的性价比其实是提升的。但这个账不能简单这么算——大多数场景下,瓶颈不在推理速度,而在模型能力。你愿意为「快」多付 3 倍钱吗?
目前的体验规则:
- 采用申请制,不是所有人都能过
- 通过审核的用户可以免费用 Chat 体验
- 每个账号每天最多进队列 10 次
- 单次会话上限 30 分钟
- 空闲 5 分钟自动踢出
很明显,小米在控制资源消耗。1000 tps 意味着 GPU 利用率被拉满,服务器成本不低。6.6 万人申请,不可能全放进来。
官方说「优先审核具备真实业务需求的企业与专业开发者场景」。如果你是个人开发者,建议在申请时把使用场景写清楚,别光说「想体验一下」。
6.6 万申请背后的需求
这个数字值得拆解一下。
两周时间,6.6 万个申请,日均近 5000 个。对于一个「限时体验」的新功能来说,热度确实不低。
更有意思的是申请者的构成:世界 500 强、法律、金融、通信、物流、汽车制造、文化传媒、高校……这不是个人开发者在尝鲜,是企业在认真评估。
为什么这些行业对「速度」这么敏感?
几个猜测:
法律和金融:合同审查、尽职调查、研报生成,这些场景的特点是文档量大、时间紧。一份几十页的合同,传统速度可能要等几分钟,UltraSpeed 可以压到几十秒。在计费按时间算的行业里,这直接影响利润率。
通信和物流:客服场景。用户等待时间从 5 秒变成 0.5 秒,体验完全不同。而且这两个行业的并发量大,对吞吐量要求高。
汽车制造:车机交互。你跟车载助手说话,如果要等 3 秒才有回应,体验会很割裂。1000 tps 能让对话接近实时。
文化传媒:内容生成。短视频脚本、新闻稿、营销文案,生成速度直接影响生产效率。
高校:科研场景。大规模实验需要频繁调用模型,推理速度决定实验周期。
这些需求一直存在,但之前没有产品能满足。小米这次算是第一个把「1000 tps」从论文搬到生产环境的。
竞争格局:小米在抢什么
放到更大的视角看,小米这波操作的战略意图很清晰:用推理速度建立差异化。
国内大模型市场已经卷到什么程度了?
能力层面,头部模型差距不大。DeepSeek、通义千问、文心一言、MiMo,在主流 benchmark 上你追我赶,用户很难感知到明显区别。
价格层面,已经卷到地板。百万 tokens 几块钱,甚至几毛钱,利润空间被压得很薄。
这时候,「速度」成了新的竞争维度。
小米的策略是:不在价格上跟你卷到底,而是在速度上拉开代际差距。3 倍价格、10 倍速度,瞄准的是那些「愿意为快付费」的高价值客户。
这个定位有意思。大模型市场正在分化:
- 低端市场:拼价格,拼免费额度,争夺个人开发者和小团队
- 高端市场:拼能力,拼速度,争夺企业级客户
小米两边都想要。标准版 MiMo-V2.5-Pro 价格不贵,走量;UltraSpeed 模式卖溢价,走利润。
能不能成,取决于两件事:
- UltraSpeed 的能力有没有明显下降(官方说「基本持平」,但需要更多实测数据)
- 1000 tps 的刚需场景有多大(目前看,至少 6.6 万人认为自己需要)
对开发者的实际影响
说点实在的建议。
如果你在做对延迟敏感的应用——实时对话、流式生成、交互式 Agent——UltraSpeed 值得认真评估。1000 tps 能让很多之前「能做但体验差」的功能变成「体验好到可以上线」。
如果你的场景是批量处理——文档分析、数据清洗、离线生成——速度提升的价值有限。反正用户不在线等着,快 10 倍和快 2 倍区别不大,但成本差 3 倍。
如果你还在技术选型阶段,建议先申请体验,跑几个真实场景的 benchmark。小米说的「基本持平」和你的实际需求可能有偏差。
申请入口在小米 MiMo 平台:platform.xiaomimimo.com/ultraspeed
Chat 体验入口:ultraspeed.xiaomimimo.com
有大规模商用需求的,可以联系 business-mimo@xiaomi.com。
这件事的更大意义
最后说点宏观的。
「1000 tokens/s」这个数字,放在一年前是不可想象的。当时的讨论是「100 tps 够不够快」。
推理速度的提升,正在改变大模型的应用边界。
以前我们讨论「能不能用大模型做 X」,考虑的是能力够不够、成本划不划算。现在还要加一条:速度够不够快。
很多场景不是「不能做」,而是「做了体验不好」。当推理速度提升一个数量级,这些场景会被重新激活。
小米这次的技术路线——FP4 混合量化 + 投机解码——不是什么秘密。其他厂商如果投入足够的工程资源,理论上也能做到。
问题在于「值不值得投」。小米用 6.6 万个申请证明了市场需求存在。接下来就看其他玩家跟不跟了。
如果跟,推理速度会成为大模型竞争的新战场。如果不跟,小米在高速推理这个细分领域可能会拉开差距。
不管怎样,开发者是受益的一方。更快的模型、更低的延迟、更多的选择。
延期是好事。多给点时间,让更多人试试。
参考来源
- 小米 MiMo-V2.5-Pro-UltraSpeed 限时体验官宣延期,下线时间将根据资源情况另行安排 - IT之家:官方延期通知的首发报道,包含 6.6 万申请量等关键数据

