扩散模型杀入文本生成:谷歌开源DiffusionGemma

谷歌DeepMind开源DiffusionGemma,将图像生成的扩散技术搬到文本领域,单卡H100跑出1000+ tokens/s,比传统自回归模型快4倍。代价是质量下降,但开源、可本地部署、消费级显卡能跑,这是扩散文本生成首次以这种完成度走向开发者社区。
扩散模型杀入文本生成:谷歌开源DiffusionGemma,速度提升4倍
谷歌DeepMind上周在Hugging Face上线了DiffusionGemma,Apache 2.0许可,权重完全开放。这不是又一个「更强更大」的模型发布——谷歌在官方文档里直接写明:它的输出质量不如自家的Gemma 4。
但它快。快到在单张H100上跑出1000+ tokens/s,消费级的RTX 5090上也有700+ tokens/s。这个速度是同级别自回归模型的4倍左右。
CEO皮查伊亲自发推介绍,把它比作「一匹赛马」——靠同时生成整段文本块、而不是逐字预测来抢速度。
这是扩散模型在文本生成领域的一次正式亮相,而且是以开源、消费级硬件可用的形态。
不是打字机,是冲洗照片
要理解DiffusionGemma为什么快,得先看清楚现在主流大模型是怎么生成文本的。
GPT、Claude、Gemini、Llama,这些模型都是自回归架构(Autoregressive)。生成文本时,它们像打字机一样从左到右逐个吐出token。生成第100个字之前,必须先生成前99个。每生成一个token,GPU都要把整个模型权重从显存里搬一遍。
这导致一个问题:GPU大部分时间在等数据搬运,真正做计算的算力反倒闲着。
在云端批量处理时,这个问题可以通过同时处理多个请求来缓解。但在本地部署、单用户场景下,GPU的利用率极低,延迟高、能耗大。
DiffusionGemma换了一种玩法。它借用了Stable Diffusion、Midjourney那套图像生成的思路:先铺一张噪声画布,然后逐步去噪,让内容「显影」出来。
具体来说:
- 模型先在「画布」上放置256个随机占位token
- 通过多轮迭代去噪,整块文字区域同时被处理
- 每个位置的token都能看到画布上所有其他位置的信息
- 直到可读内容浮现
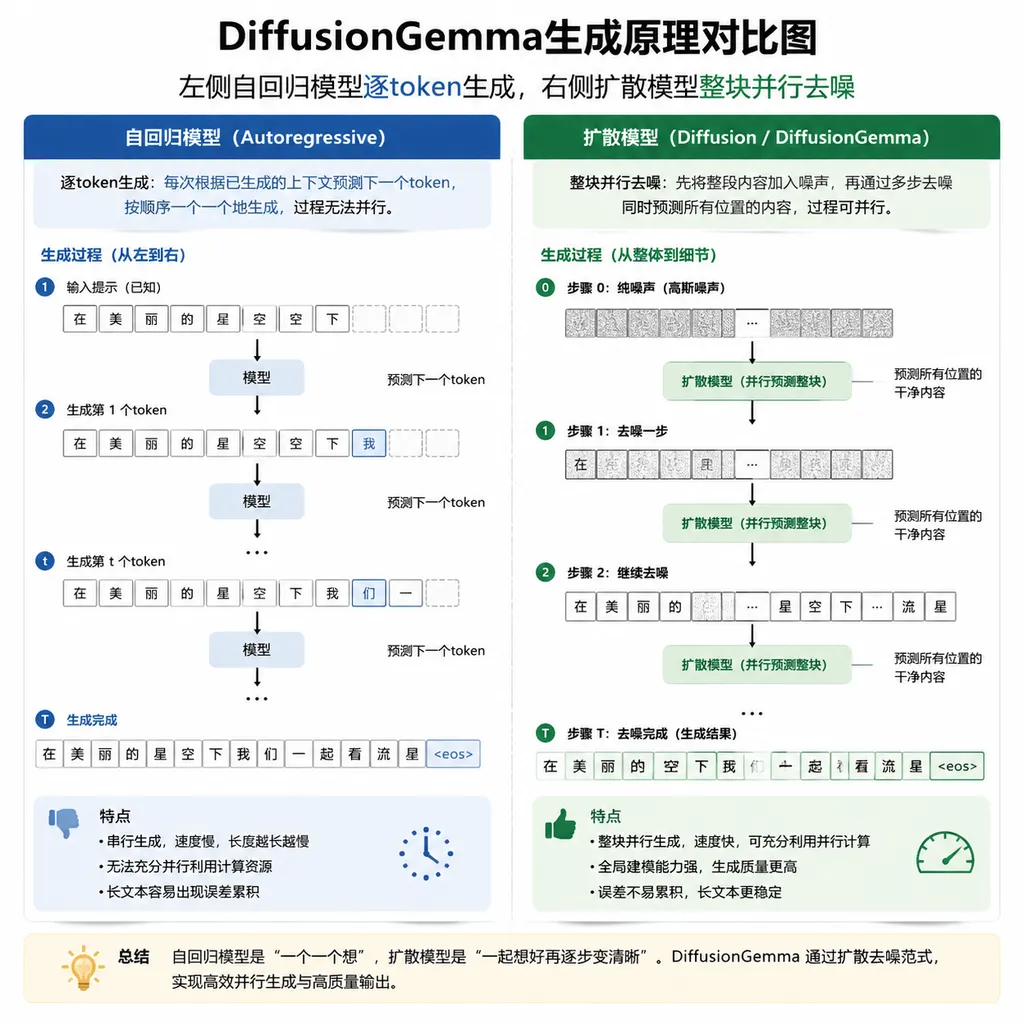
一次处理256个token,而不是一次处理1个。 这把推理瓶颈从内存带宽转移到了计算能力上——而计算能力恰恰是GPU最擅长的事。
实测数据:快是真的快
谷歌和英伟达都给出了实测数据:
| 硬件 | 吞吐量 | |------|--------| | NVIDIA H100 (FP8) | 1000-1100+ tokens/s | | NVIDIA DGX Station | 最高2000 tokens/s | | NVIDIA DGX Spark | 约150 tokens/s | | GeForce RTX 5090 | 700+ tokens/s |
作为对比,同架构的Gemma 4在相同条件下大约是303 tokens/s。DiffusionGemma快了接近4倍。
更关键的是硬件门槛。DiffusionGemma总参数约260亿,但采用MoE(混合专家)架构,推理时只激活38亿参数。经过量化处理后,模型只占约18GB显存,RTX 4090、5090这种消费级显卡本地就能跑。
这个速度优势有明确的适用范围。谷歌在文档里写得很清楚:
- ✅ 本地部署、单用户、低并发场景
- ✅ 对延迟敏感的交互式应用
- ❌ 高QPS的云端大规模服务(并行解码的边际效益递减)
- ❌ 共享内存架构(如Apple Silicon Mac,自回归模型本来就不太受内存带宽限制)
换句话说,这是一个为本地推理场景专门优化的模型。
质量换速度:谷歌自己打的差评
速度快4倍,代价是什么?
谷歌没藏着掖着。官方文档里直接放了对比图:
| 基准测试 | DiffusionGemma | Gemma 4 | |----------|----------------|---------| | AIME 2026 (数学) | 69.1% | 88.3% | | MMMU Pro (多模态) | 54.3% | 73.8% | | 多语言问答 | 略低 | 更高 | | 代码生成 | 略低 | 更高 | | 科学知识 | 略低 | 更高 |
数学能力差了近20个百分点,多模态差了近20个百分点。 这不是微调能补回来的差距。
谷歌对此的态度很务实:
这是一款为了「把速度推到极限而刻意妥协品质」的实验性模型。高质量的生产级输出,请继续用Gemma 4。
但质量下降不意味着这个模型没用。扩散架构有一些自回归模型天生做不好的事情。
双向注意力:扩散模型的独特优势
自回归模型生成文本时,每个token只能「往左看」——它能看到之前生成的所有内容,但看不到后面会写什么。这在大多数场景下没问题,但有些任务天生需要「前后兼顾」。
数独就是典型例子。 每个格子同时受行、列、九宫格三重约束。自回归模型从左到右一格格填,填到后面发现前面错了,但已经改不了了。
DiffusionGemma的扩散架构支持双向注意力——去噪时,画布上每个位置都能看到所有其他位置的信息。哪个token置信度下降了,采样器可以把它打回噪声状态重新生成。
谷歌展示了一个微调后的DiffusionGemma解数独的演示:整盘并行去噪,几步之内同时收敛,而不是从左到右一格格填。
类似的还有:
- 代码填充(infilling):在已有代码的中间插入内容,需要同时考虑前文和后文
- 行内编辑:修改段落中间的一句话,保持前后连贯
- Markdown格式闭合:扩散模型能一次性把括号、标签配对写好,而不是写到一半才发现没闭合
- 氨基酸序列生成:蛋白质结构的约束是全局的
- 数学图形构建:几何关系需要整体协调
谷歌把这类任务统称为「非线性文本生成」。 这是扩散架构真正有优势的地方,而不仅仅是「快但糙」。
技术细节:块自回归与MoE
DiffusionGemma不是纯粹的扩散模型,它采用块自回归(block-autoregressive) 策略:
- 生成一个256-token的画布
- 多轮去噪直到内容成形
- 把这256个token写入KV缓存
- 开下一张新画布,接着上文继续生成
这样既保留了扩散模型的并行优势,又能生成任意长度的文本。
架构上,DiffusionGemma基于Gemma 4的26B参数MoE架构。MoE的核心思想是:模型里有多个「专家子网络」,每次推理只激活最相关的那几个,而不是整个模型一起运转。
260亿总参数,推理时只激活38亿。 这是它能塞进消费级显卡的关键。
英伟达这次也下了功夫做适配:
- 原生支持NVFP4(4-bit浮点)格式,接近无损精度的同时进一步提升吞吐
- CUDA栈发布当天就能跑,不需要专门调优
- 在Hugging Face上同时放了BF16精度版和NVFP4轻量版
生态支持:开箱即用
这次发布的完成度很高。谷歌直接给出了全家桶支持:
- Hugging Face Transformers:标准集成
- vLLM:给了OpenAI兼容的本地部署命令,下完权重就能起服务
- Unsloth:支持高效微调
英伟达在发布当天就在build.nvidia.com挂了免费在线入口,可以直接试用。
模型地址:google/diffusiongemma-26B-A4B-it
对于想在本地跑的开发者,vLLM的部署命令大概是这个流程:
- 下载模型权重(约18GB量化版)
- 启动vLLM服务,指定模型路径
- 通过OpenAI兼容的API调用
具体命令和参数建议直接看Hugging Face模型卡的说明,会随版本更新。
扩散文本生成的竞争格局
扩散模型做文本生成不是新概念,但之前一直停留在论文和闭源产品阶段。
Inception Labs的Mercury系列是商用化走得最快的。2026年2月发布的Mercury 2主打「相对速度优化模型最高5倍加速」,早期材料里甚至出现过「最高10倍吞吐」的说法。但Mercury真正开源的只有1.3B一档,参数量太小,实用性有限。
谷歌自己的Gemini Diffusion在2025年5月的I/O大会上就展示过,速度做到1479 tokens/s,比DiffusionGemma还快。但权重没有公开,开发者用不了。
DiffusionGemma的独特之处在于三样东西凑齐了:
- 前沿实验室出品(DeepMind)
- 权重完全开源(Apache 2.0)
- 消费级硬件本地可用(18GB显存)
这是扩散文本生成技术第一次以这种完成度走向开发者社区。
适用场景:什么时候该用它
根据谷歌的官方指南和实际特性,DiffusionGemma适合这些场景:
推荐使用
- 本地交互式应用:IDE插件、命令行工具、本地聊天界面
- 快速迭代工作流:需要反复尝试、即时反馈的场景
- 行内编辑和代码填充:需要在已有内容中间插入新内容
- 对延迟敏感的demo和原型:需要给用户「秒回」体验
- 非线性结构生成:数独、填字、约束求解类任务
不推荐使用
- 生产级内容输出:对文本质量要求高的场景,用Gemma 4
- 高并发云端服务:QPS高时扩散的优势会递减
- Apple Silicon Mac:共享内存架构下优势不明显
- 数学推理和复杂逻辑:这是它明确的短板
值得探索
- 结合微调的垂直场景:谷歌展示了数独微调的效果,类似的约束求解任务可能有意外收获
- 与自回归模型的混合流水线:快速生成初稿 + 高质量模型润色
- 边缘设备部署:18GB显存意味着更多硬件选择
对行业的意义
扩散模型在图像生成领域已经是绝对主流。Stable Diffusion、Midjourney、DALL-E 3,全是扩散架构。但在文本生成领域,自回归一直是唯一的选择。
DiffusionGemma代表的是架构多样性的开始。
它不会取代GPT、Claude这些自回归模型——至少在通用质量上差距明显。但它证明了:
- 扩散架构在文本生成上是可行的,而且有独特优势
- 速度和质量的权衡可以是显式的,针对不同场景选择不同架构
- 本地部署场景值得专门优化,不是所有模型都要瞄准云端
对于开发者来说,这意味着工具箱里多了一个选项。当你的应用场景是「本地、低延迟、可以接受质量略降」时,现在有了一个正经的开源方案。
谷歌把这个模型定位为「实验性」,但发布的完成度(开源权重、多框架支持、消费级硬件可用)已经超出了实验的范畴。它更像是在给整个行业打样:扩散文本生成可以这么做。
接下来看其他厂商跟不跟了。
参考来源
- google/diffusiongemma-26B-A4B-it - Hugging Face - 模型权重和官方文档
- 探索文本生成新范式:谷歌开源4倍提速的实验性扩散语言模型 - 知乎 - 技术原理中文解读
- Google Deepmind just dropped DiffusionGemma - Reddit - 社区讨论和反馈


