智谱 Max 周限额突然重置,开发者该高兴还是该慌?

智谱 GLM Coding Plan Max 套餐昨晚悄然重置周限额,开发者一觉醒来发现用量从接近爆表变回 1%。但这次「福利」背后,暴露的是智谱限额机制的长期混乱。
智谱 Max 周限额突然重置,开发者该高兴还是该慌?
昨晚(6 月 23 日),智谱 GLM Coding Plan Max 套餐用户收到了一份意外的「礼物」——周限额被重置了。
有开发者早上醒来,发现自己的 Max 套餐周用量从前几天的高位直接掉到 1%,而周限重置的倒计时并没有变化。换句话说,这不是正常的周期轮转,而是智谱后台手动做了一次额度刷新。
消息最早出现在 Linux.do 论坛,发帖者的原话是:「早上睡醒发现 Max 套餐周用量变成 1% 了,看起来好像是给重置了。」
听起来是好事。但如果你关注智谱 Coding Plan 有一段时间,就知道这种「惊喜」背后,往往藏着更深的问题。
一、先说这次重置:发生了什么?
智谱 GLM Coding Plan 分三档:Lite、Pro、Max。Max 是最高档,月费最贵,理论上额度也最充足。
这些套餐都有一个「周限额」机制——你每周能用的 token 或 prompts 数量是有上限的,用完就得等下周重置。这个设计的初衷是防止少数用户短时间内把资源吃光,影响其他人的体验。
但问题来了:正常的周限额重置是有固定时间的,比如每周一凌晨。而这次重置发生在周中,且没有任何官方公告。
从用户反馈来看,这次重置的特征是:
- 影响范围:目前确认的是 Max 套餐用户,Pro 和 Lite 暂无明确报告
- 重置幅度:周用量直接归零(显示为 1%)
- 重置时间:6 月 23 日晚间,非常规周期节点
- 官方态度:截至发稿,智谱官方未发布任何说明
这意味着什么?要么是系统 bug,要么是智谱在做某种补偿性操作,要么是后台在调整限额算法。 无论哪种情况,用户都处于「不知道发生了什么」的状态。
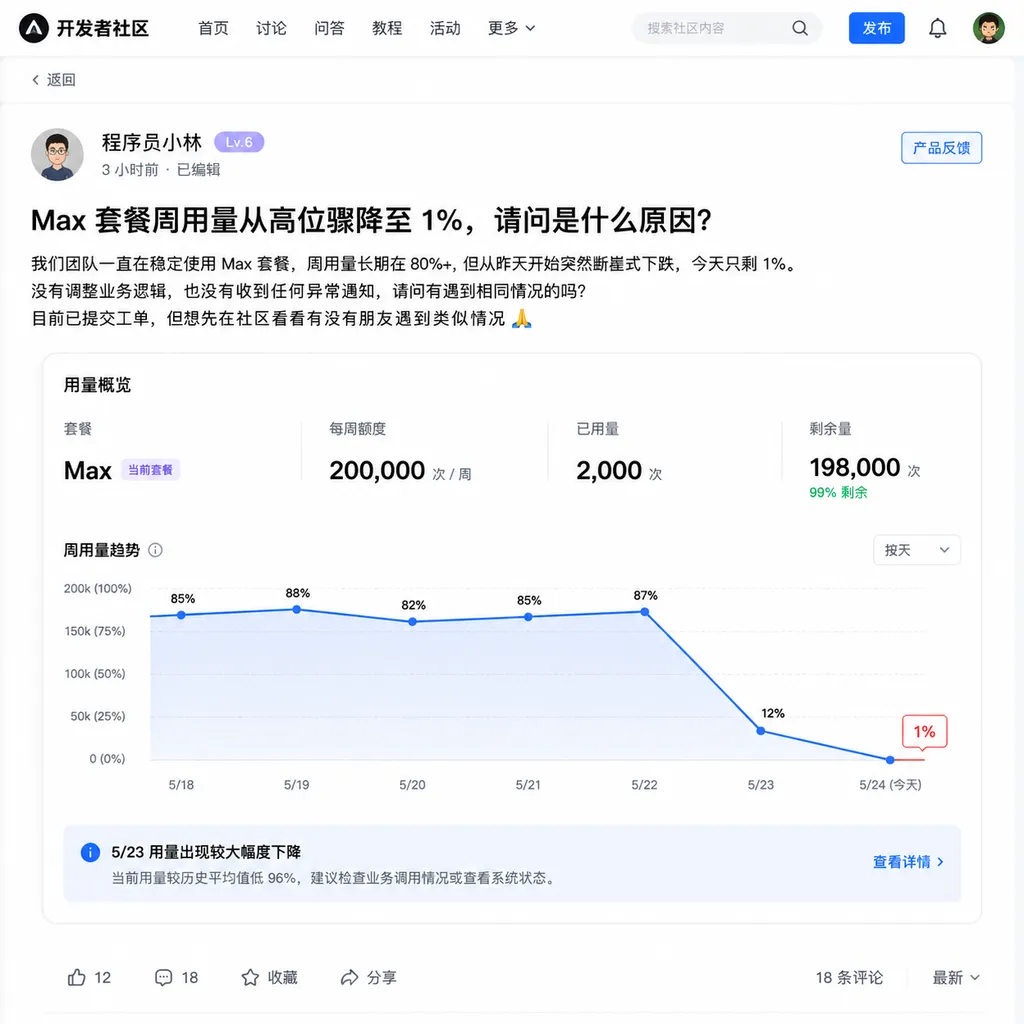
二、智谱限额机制:一笔糊涂账
要理解这次重置为什么让人「又喜又忧」,得先搞清楚智谱 Coding Plan 的限额机制到底是怎么回事。
坦白说,这是一笔糊涂账。
2.1 官方宣传 vs 实际体验:差距有多大?
智谱官方宣传 Pro 套餐的额度大约是 Claude Pro 的 15 倍。这个数字看起来很诱人——Claude Pro 每月 20 美元,用 Opus 模型写代码,很多人撑不过 20 分钟就触发 5 小时冷却;如果智谱能提供 15 倍的量,性价比简直爆表。
但实测数据讲述了另一个故事。
有开发者用 GLM-5.1 模型跑了一个复杂任务,完成后发现周用量直接飙到 8%。半天高强度使用下来,用量就到了 10%。按这个消耗速度,一周根本撑不住。
这位开发者的体感结论是:实际额度大约是 Claude Pro + Opus 的 1.5 到 2 倍,跟官方宣传的 15 倍差了一个数量级。
为什么会有这么大的差距?问题出在「额度」的计量单位上。
2.2 Prompts ≠ 请求次数:藏在细节里的魔鬼
智谱和 MiniMax 的 Coding Plan 都用「Prompts」作为计量单位,但这个词的定义非常模糊。
根据知乎上的分析,1 Prompts ≈ 15 次 prompt 请求。也就是说,你以为买了 2000 次 prompts,实际上可能只够 130 次左右的完整对话轮次。
这还没完。除了总量限制,还有:
- QPS 限制:每秒能发多少请求
- 并发限制:同时能有多少请求在处理
- Token 速率限制:每秒能处理多少 token
- 5 小时滑动窗口:部分限制是按滑动窗口计算的,不是固定时间段
这些限制叠加在一起,结果就是:你可能额度还剩 95%,但系统已经不让你用了。
这不是假设。今年 3 月,有 V2EX 用户发帖吐槽:买了 Max 套餐,已使用额度不到 5%,剩余约 95%,但 API 返回 429 错误,提示「您的账户已达到速率限制」。
用户买套餐的心理预期是「包月宽带」——付了钱就该随便用。但实际的定价逻辑更接近「带宽计费」——你买的是总流量,但瞬时带宽有上限。
这种认知差距,是智谱 Coding Plan 口碑问题的根源。
2.3 老套餐「被毕业」:4 月的那场风波
今年 4 月,智谱做了一件让老用户不太高兴的事:宣布 GLM Coding Plan 老套餐(无周限额版本)将于 4 月 30 日停止自动续订。
没错,最早的 Coding Plan 是没有周限额的。那批早期用户享受的是真正的「包月」体验。但随着用户量增长,智谱显然发现这个模式不可持续,于是引入了周限额机制,并强制老用户迁移。
作为补偿,智谱给受影响用户赠送了 2 个月同等级新套餐权益。但补偿归补偿,从「无限制」到「有限制」的体验降级是实打实的。
这也解释了为什么这次突然重置让人心情复杂:一方面,额度回来了是好事;另一方面,这种不透明的操作让人对智谱的限额机制更加没底——今天能重置,明天会不会突然收紧?
三、横向对比:国产 AI Coding Plan 的限额乱象
智谱不是唯一一家在限额机制上让用户困惑的厂商。整个国产 AI Coding Plan 赛道,都存在类似的问题。
3.1 计量单位:各说各话
不同厂商用的计量单位五花八门:
| 厂商 | 计量单位 | 换算关系 | |------|----------|----------| | 智谱 | Prompts | 1 Prompts ≈ 15 次请求 | | MiniMax | Prompts | 类似智谱 | | 阿里云 | 请求次数 | 直接计数 | | 火山引擎 | 请求次数 | 直接计数 |
这种计量方式的混乱,让用户很难在不同产品之间做横向比较。你说你有 2000 Prompts,他说他有 10000 次请求,谁的额度更多?不算一遍根本不知道。
3.2 限额窗口:滑动 vs 固定
另一个容易踩坑的点是限额的时间窗口。
有些厂商用的是固定窗口:比如每周一凌晨重置,简单明了。
有些厂商用的是滑动窗口:比如 5 小时滑动窗口,从你开始使用的时刻起算。这意味着如果你下午 2 点开始高强度使用,3 点额度用完,要等到晚上 7 点第一批额度才会恢复——而不是等到某个固定的时间点。
滑动窗口对重度用户非常不友好。如果你的工作节奏是「集中几小时猛干一波」,很容易撞上限额,然后发现等待时间比预期长得多。
3.3 信息透明度:普遍不及格
几乎所有国产 AI Coding Plan 在信息透明度上都做得不够好:
- 套餐页面不标注 QPS、并发、token 速率的具体数值
- API 返回的 rate limit header 信息不完整,缺少剩余配额和重置时间
- 限额规则变更时,很少提前通知用户
这导致开发者在写代码时没法做精确的流控。你不知道自己还剩多少额度,不知道什么时候会撞墙,只能凭感觉试探。
这不是一个成熟 API 产品该有的样子。
四、开发者的真实痛点:不是钱的问题
有意思的是,很多开发者对 Coding Plan 的吐槽,核心并不是「太贵」,而是「用着不踏实」。
4.1 心理账户的价值
知乎上有人写过一段话,我觉得很准确:
除了省那几十块钱,套餐更重要的是消除 token 焦虑——不用盯着每次调用看费用,不用在「让 AI 多试几次」和「算了手动改吧」之间纠结。心理账户上的轻松感,有时候比实际省的钱更值。
这正是 Coding Plan 这个产品形态存在的意义:把按量计费的焦虑,转化为包月制的确定性。
但如果限额机制不透明、实际额度跟宣传差距太大、还时不时来个意外重置,这种确定性就被破坏了。用户买的是「安心」,结果拿到的是「时刻提心吊胆」。
4.2 速度问题:被忽视的体验杀手
除了额度,速度是另一个被低估的痛点。
有开发者反馈,用 GLM-5.1 跑一个复杂任务花了 1 个多小时。这个速度在生产环境下基本不可用——你总不能让用户等一个小时吧。
速度慢有很多原因:模型本身的推理速度、服务器负载、网络延迟等等。但对用户来说,原因不重要,结果才重要。如果一个模型又慢又限额,那便宜也没用。
4.3 能力 vs 可用性:两码事
GLM-5.1 的模型能力确实不错。很多评测显示它的编码质量介于 Claude Sonnet 4.6 和 Opus 4.6 之间,有些场景甚至能打平 Opus。
但能力强不等于可用性高。
一个模型要在生产环境下好用,需要满足多个条件:
- 能力够强(GLM-5.1 做到了)
- 速度够快(存疑)
- 额度够用(存疑)
- 稳定性够好(没有足够数据)
- 文档和工具链够完善(有改进空间)
智谱在第一项上做得不错,但后面几项还有明显的短板。
五、这次重置意味着什么?几种可能的解读
回到这次周限额重置事件,我们可以从几个角度来解读。
5.1 乐观解读:智谱在做用户补偿
一种可能是,智谱意识到最近的限额机制过于激进,导致用户体验下降,所以主动做了一次额度刷新作为补偿。
如果是这种情况,说明智谱在关注用户反馈,并且愿意采取行动改善体验。这是好事。
5.2 中性解读:后台在调整算法
另一种可能是,智谱在调整限额的计算逻辑或统计方式,导致用户端显示的数据发生了变化。
这不一定是「送额度」,可能只是数据展示方式变了。如果是这种情况,用户实际能用的量可能并没有增加。
5.3 悲观解读:系统 bug 或误操作
还有一种可能是纯粹的技术问题——后台出了 bug,或者运维做了误操作,导致部分用户的数据被意外重置。
如果是这种情况,智谱可能会在之后「回滚」这次重置,把额度调回原来的状态。
无论是哪种情况,智谱保持沉默都不是最优解。 一个简短的官方说明——哪怕只是「我们调整了某个机制,具体细节稍后公布」——都比让用户猜来猜去强。
六、给开发者的实操建议
基于目前的情况,如果你正在使用或考虑使用智谱 Coding Plan,以下是一些实操建议:
6.1 如果你已经是 Max 用户
- 趁这波重置,把积压的任务跑一跑。额度既然回来了,先用再说。
- 做好额度监控。在代码里加上对 rate limit 的处理逻辑,及时发现问题。
- 准备备选方案。不要把所有鸡蛋放在一个篮子里,至少保留一个备用的 AI 编码工具。
6.2 如果你在观望
- 先试用,再付费。如果智谱提供试用期,务必在真实工作场景下测试,而不是只跑几个 demo。
- 计算真实成本。不要只看标价,要算「单位产出」的成本。一个便宜但限额紧、速度慢的套餐,实际性价比可能不如更贵但更稳定的选择。
- 关注社区反馈。Linux.do、V2EX、知乎上有大量真实用户的使用报告,比官方宣传更有参考价值。
6.3 通用建议
- 不要对任何单一厂商抱有过高期望。国产 AI Coding Plan 整体还处于早期阶段,产品成熟度和海外头部产品有差距。
- 建立多模型工作流。不同任务用不同模型,既能规避单点故障,也能发挥各家所长。
- 保持信息敏感度。这个领域变化很快,一个月前的「最优解」可能已经过时了。
七、智谱需要做什么?
最后,站在产品的角度,说说智谱可以改进的地方。
7.1 信息透明化
在 Coding Plan 页面明确标注所有限制的具体数值:
- 周限额的精确定义(是 token 数还是请求数?怎么换算?)
- QPS 限制
- 并发限制
- Token 速率限制
- 滑动窗口的具体规则
用户不怕限制多,怕的是不知道限制是什么。
7.2 API 信息完善
在 API 返回的 header 里带上完整的限额信息:
- 当前剩余配额
- 下次重置时间
- 触发限制的具体原因
这样开发者才能在代码里做精确的流控,而不是撞墙了才知道。
7.3 建立沟通机制
遇到限额调整、系统异常等情况,及时通过官方渠道(公告、邮件、站内信)通知用户。不要让用户从社区论坛里「发现」变化。
信任是一点一点建立的,也是一点一点消耗的。每一次不透明的操作,都在消耗用户的信任余额。
八、结语
智谱 Max 周限额重置这件事,说大不大,说小不小。
往大了说,它暴露了国产 AI Coding Plan 在产品成熟度上的普遍短板:限额机制不透明、宣传与实际有差距、用户沟通不到位。
往小了说,它只是一次数据变动,可能明天就被「修正」回去,什么都没发生。
但无论如何,这件事提醒我们:在选择 AI 工具时,不能只看模型能力,还要看产品的整体可用性。一个聪明但不可靠的助手,不如一个稳定但能力稍弱的助手。
GLM-5.1 的模型实力是有的。智谱要做的,是把这个实力包装成一个让开发者用着舒服、用着放心的产品。
目前来看,还有一段路要走。
如果你也在用智谱 Coding Plan,欢迎在评论区分享你的体验。特别是这次重置之后,实际能用的额度有没有变化,速度有没有改善——这些真实数据,比任何分析都有价值。
参考来源
- 智谱 Max 昨晚重置限额了 - Linux.do —— 本次限额重置事件的首发讨论帖
- 智谱:GLM Coding Plan 老套餐 4 月 30 日停止自动续订 - IT之家 —— 智谱套餐迁移政策的官方报道
- 2026年国产AI Coding Plan省钱攻略 - 知乎 —— 国产 AI Coding Plan 横向对比分析

