豆包音频模型1.0:一条Prompt直出成片级音频

火山引擎发布豆包音频生成模型1.0,首次实现对白、配乐、音效单次端到端生成,支持长时音色一致性和零样本声音创建,直接改变了传统音频制作的多轨剪辑工作流。
豆包音频模型1.0:一条Prompt直出成片级音频
火山引擎昨天在 FORCE 原动力大会上发布了豆包音频生成模型 1.0(Doubao-Seed-Audio 1.0)。这是一个端到端的音频生成模型,核心卖点是:一次推理同时输出角色对白、背景音乐和环境音效,不需要分别生成再手动合成。
这意味着什么?传统音频制作流程里,配音演员录对白、作曲提供配乐、音效师做拟音、混音师最终合成——至少四个环节、四种工具。Seed-Audio 1.0 试图用一条 Prompt 替代这条链路的前几个环节。
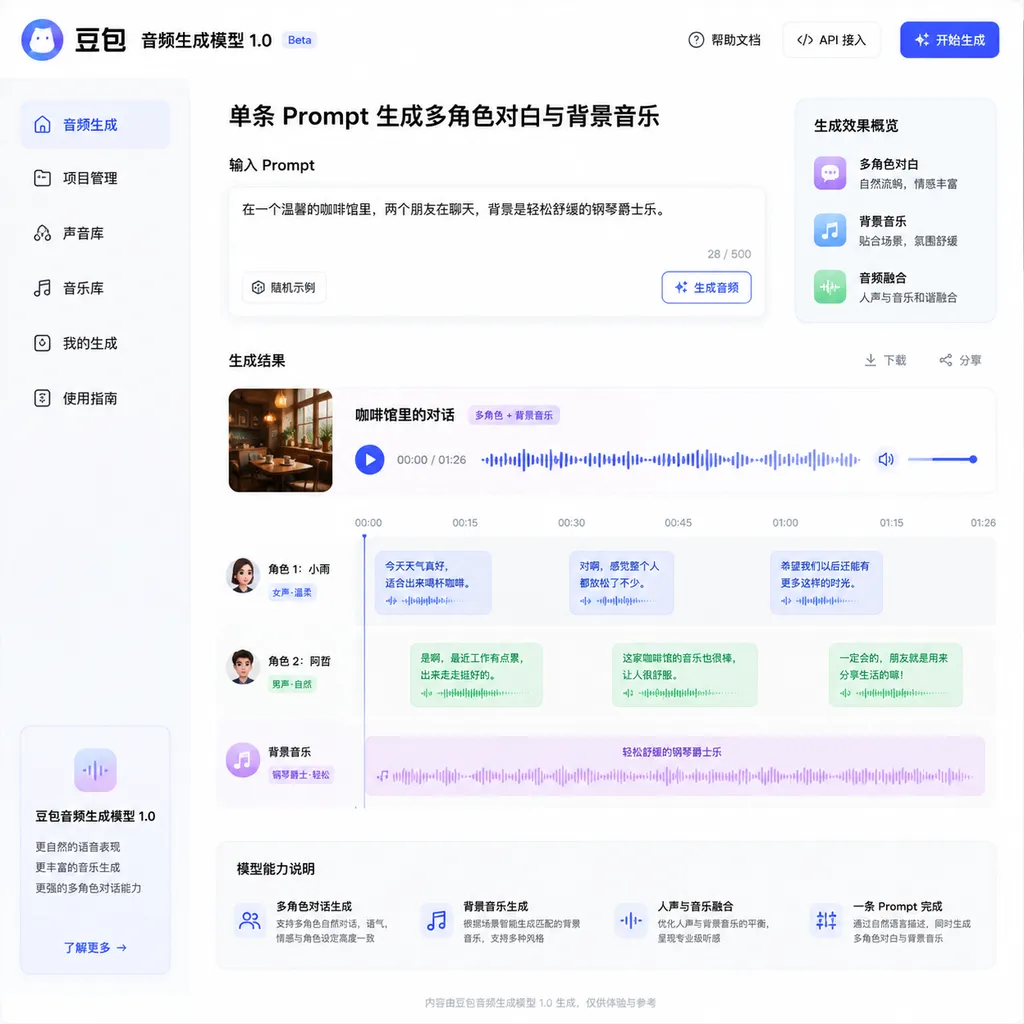
三个核心能力,对应三个真实痛点
影视级音频单次直出
最直观的能力是「全要素生成」。在一条 Prompt 里,你可以同时定义:
- 多角色对白:包括台词内容、情绪节奏、语气变化
- 非语言表达:笑声、叹息、停顿、方言口音
- 背景音乐:风格、节奏、情绪基调
- 环境音效:场景氛围、拟音特效
模型在一次生成中同步编排这些元素,输出的是混合好的成品音频,而不是需要你再去对齐时间轴的多个音轨。
举个具体例子:你想做一段悬疑广播剧的开场。传统流程是——先写好对白脚本,找配音演员分别录制,再从音乐库里挑配乐,然后让音效师加脚步声、开门声、雨声,最后混音师把这些素材对齐合成。整个流程可能要几天。
用 Seed-Audio 1.0,你写一段描述:
「深夜,暴雨。男主角(30岁,声音低沉疲惫)推开门,脚步沉重。女主角(25岁,带着哭腔):'你终于回来了……'背景是持续的雨声和偶尔的雷鸣,配乐是低沉的弦乐,营造紧张氛围。」
模型直接输出一段带有对白、雨声、雷声、脚步声和背景音乐的完整音频。
这不是「更快」的问题,是工作流被重构的问题。
长时音色一致性
做过有声书或播客的人都知道,单句质量从来不是最大的挑战。真正让人崩溃的是:第一章的主角和第十章的主角听起来不像同一个人。
传统 TTS 工具在长音频场景下经常出现「音色漂移」——同一个角色的声音特征在不同段落之间发生微妙变化。这就需要后期大量的修音工作,或者干脆重新生成。
Seed-Audio 1.0 的解决方案是文生音频与参考音频的深度联动。具体来说:
- 模型一次支持生成 2 分钟的音频
- 你可以把已生成的音频作为参考输入,延长后续内容
- 在多次延长过程中,模型会锁定之前建立的音色特征
这对有声书、长播客、多集广播剧等场景的价值是直接的。一个 20 集的广播剧,每集 30 分钟,传统流程里需要配音演员保持状态一致,或者后期花大量时间调整。现在模型层面就能保证音色统一。
但这里有个需要验证的问题:「2分钟一次,多次延长」的机制在实际使用中是否稳定?延长 10 次、20 次之后,音色漂移是否会累积?官方没有给出长程生成的具体测试数据,这需要实际跑一跑才知道。
零样本多模态参考
第三个能力是「零样本声音创建」。传统声音克隆需要你先提供一段参考音频——录一段目标声音的样本,模型学习后再用于生成。
Seed-Audio 1.0 支持纯文本定义声音特征:
「中年男性、略带沙哑、南方口音、语速偏慢」
模型根据这段描述推理出匹配的声音特征,直接用于生成。不需要你去找一个真人录参考音频。
这对中小团队的意义很明显——不是每个播客主都有录音棚和配音演员资源。纯文本就能定义角色声音,把门槛拉低了一个量级。
但同样,这里有个可控性的问题:「中年男性、略沙哑」可以对应无数种具体音色。你能否通过文本精确控制到你想要的特定声音风格,还是只能「抽卡」直到满意?这直接决定这项功能在商业场景中的实用性。
ElevenLabs 的做法是提供声音克隆和预设声音库来解决精确性问题。Seed-Audio 1.0 的零样本路线能否在精度上追平,需要更多实际案例验证。
跟 ElevenLabs 比,差异在哪?
说 Seed-Audio 1.0,不能不提 ElevenLabs。这是目前全球音频生成领域的标杆,产品矩阵包括:
- Eleven v3:TTS 模型,支持 70+ 语种
- ElevenMusic:音乐生成,Suno 级别的质量
- Sound Effects:音效生成
- Text-to-Dialogue:多角色对话
- Studio 3.0:时间轴编辑器,组合以上元素
产品线非常完整。但 ElevenLabs 的架构是「分别生成、手动组合」——TTS、音乐、音效是三个独立 API 和模型,用户需要在 Studio 时间轴中逐轨添加和对齐。
Seed-Audio 1.0 的差异是「单次端到端生成」——对白、配乐、音效在同一次推理中协同输出,不需要用户手动对齐节奏和时序。
| 对比维度 | Seed-Audio 1.0 | ElevenLabs | |---------|----------------|------------| | 生成方式 | 单次端到端直出 | 分别生成后手动组合 | | 语种支持 | 未公布(推测以中英文为主) | 70+ 语种 | | 音乐生成 | 内置于端到端流程 | 独立的 ElevenMusic 模型 | | 企业合规 | 未公布 | SOC 2/HIPAA 认证 | | API 成熟度 | 邀测阶段 | 成熟定价体系 | | 大客户背书 | 字节系产品内测 | Meta 等头部客户 |
如果 Seed-Audio 1.0 的「单次直出」能力在实际使用中稳定可用,它在制作效率上的优势是结构性的——你省掉的不是几分钟操作时间,而是整个「多轨对齐」的工作环节。
但 ElevenLabs 的生态优势同样是结构性的:语种覆盖、API 成熟度、企业级合规、大客户背书——这些不是功能参数能弥补的。Seed-Audio 1.0 作为 1.0 版本,在这些维度上需要时间追赶。
国内竞品方面,阿里和腾讯都有 TTS 产品线,但没有公开发布「对白+配乐+音效单次直出」的端到端音频生成模型。快手在可灵体系内的音频能力也以 TTS 为主。Seed-Audio 1.0 在国内市场暂无直接功能对标。
放在豆包多模态矩阵里看
Seed-Audio 1.0 不是一个孤立发布。同一场大会上,火山引擎还发布了 Seedance 2.5(视频模型)和 Seedream 5.0 Pro(图像模型)。
把时间线拉长:
- 2月:Seedance 2.0 发布,音视频联合生成架构
- 4月:Seedance API 开放
- 5月:Seedance 1.0 lite 发布,兼顾效率与性价比
- 6月:Seedance 2.5、Seedream 5.0 Pro、Seed-Audio 1.0 同时发布
四个月内,字节 Seed 团队完成了视觉和听觉生成的全模态覆盖。这个节奏在国内没有对手。
组合逻辑是:
Seedream(图像) → Seedance(带声音的视频) → Seed-Audio(纯音频)
三个模型覆盖了 AIGC 内容生成的主要形态。Seedance 2.0 在发布时就采用了音视频联合生成架构——视频和音频在同一次推理中同步产出。Seed-Audio 1.0 补的是「纯音频场景」——有声书、播客、广播剧这些不需要视频画面的内容形态。
但覆盖不等于成熟。Seedance 2.0 从发布到 API 全面开放经历了两个月,到企业侧大规模商用又经历了两个月。Seed-Audio 1.0 作为全新模型线的 1.0 版本,从发布到可稳定调用的时间线大概率也不会短。
实际使用:现在能体验什么?
目前的开放状态:
- API:火山方舟已开启邀测,需要申请
- 个人体验:火山方舟体验中心可直接使用,有 30 分钟的免费创作额度
- 产品集成:即将上线剪映、即梦、番茄等字节系产品
对于想尝鲜的开发者,30 分钟的免费额度够跑几个测试场景了。建议从简单的多角色对话开始,逐步加入背景音乐和音效,观察模型在不同复杂度下的表现。
对于内容创作者,剪映和即梦的集成值得关注。这两个产品的用户基数大,如果 Seed-Audio 1.0 的能力被良好封装成易用的功能入口,可能会很快跑出一批新的内容形态。
三个待验证的问题
作为 1.0 版本,Seed-Audio 有几个问题需要实际使用后才能回答:
第一,长音频场景的稳定性。官方演示的是短片段效果,但有声书、播客等场景动辄几十分钟甚至几小时。「2分钟一次,多次延长」的机制在累积使用后是否会出现音色漂移、节奏错乱或音质下降,需要实际跑长程测试。
第二,零样本声音生成的可控性。纯文本描述声音特征的粒度有限——「中年男性、略沙哑」可以对应无数种具体音色。用户能否通过文本精确控制到所需的特定声音风格,还是只能「抽卡」直到满意,直接决定这项功能在商业场景中的实用性。
第三,API 开放时间和定价。发布会没有公布 Seed-Audio 1.0 的 API 正式开放时间表和定价。对于有声书、播客等长音频场景,按什么方式计费、成本结构是否能比传统配音+音乐授权+音效库的组合成本更低,是决定其商业化渗透速度的关键。
对音频内容行业意味着什么?
如果 Seed-Audio 1.0 的能力在实际使用中足够稳定,它可能会改变几个细分市场的竞争格局:
有声书市场
传统有声书制作成本高、周期长,主要是因为配音演员和后期制作的人力成本。AI 配音已经在这个市场渗透了一段时间,但之前的方案是「AI 生成对白 + 人工添加配乐音效」,后期工作量仍然不小。
如果 Seed-Audio 1.0 能真正做到「一条 Prompt 出成品」,有声书的边际生产成本可能会进一步下降。这对长尾图书的有声化有直接推动作用——之前不值得投入制作成本的书,现在可能值得做了。
播客和短音频
播客创作者的痛点一直是「门槛不高但天花板很高」。入门容易(有个麦克风就能录),但做出有质感的节目很难——需要好的剪辑、配乐、音效设计。
Seed-Audio 1.0 可能会催生一批「AI 原生」的播客形态:不是真人主播录制后用 AI 辅助剪辑,而是从一开始就用 AI 生成整个节目。虚拟主播播客、AI 生成的新闻简报、自动化的有声日报——这些形态可能会更快落地。
游戏和互动内容
游戏 NPC 对话、互动剧情的音频内容,传统上需要大量配音资源。特别是需要多语言版本的游戏,配音成本是可观的支出。
端到端音频生成如果能做到足够的质量和可控性,可能会改变游戏音频制作的方式。不是「预先录好所有对话」,而是「实时生成符合情境的音频」。这对开放世界游戏、AI NPC 等方向有直接的支撑作用。
总的来说,豆包音频生成模型 1.0 的「单次端到端生成」是一个有意思的技术方向。它试图解决的问题很具体:把多轨制作压缩成单次生成。如果这个方向跑通,音频内容的生产效率会有结构性的提升。
但作为 1.0 版本,它离「可稳定商用」可能还有一段距离。API 还在邀测,定价未公布,长音频场景的稳定性未经大规模验证。建议有需求的开发者先去火山方舟体验中心跑跑测试,实际感受一下模型在自己场景下的表现,再决定是否投入生产环境。
参考来源
- IT之家:火山引擎发布豆包音频生成模型 1.0 - 首发报道,包含官方功能介绍

