千问发布首个原生语言世界模型,AI 智能体训练进入新阶段

阿里千问今日发布 Qwen-AgentWorld,这是首个从预训练阶段就开始建模环境的语言世界模型,单一模型覆盖七大智能体交互领域,为 AI 智能体的训练和部署提供了全新范式。
千问发布首个原生语言世界模型,AI 智能体训练进入新阶段
阿里千问今天正式发布 Qwen-AgentWorld,官方将其定位为「首个原生语言世界模型」。这不是又一个通用大模型的性能刷榜,而是在回答一个更根本的问题:AI 智能体要在真实环境中干活,能不能先在一个模拟世界里学会怎么干?
答案是可以,而且效果相当不错。
什么是「语言世界模型」?
先解释一下这个概念。传统的智能体训练有个尴尬的问题:你想让 AI 学会操作电脑、浏览网页、执行终端命令,就得让它在真实环境里反复试错。但真实环境成本高、风险大,而且很难规模化——你不可能同时开一万台真机让 AI 去折腾。
语言世界模型的思路是:用一个语言模型来模拟环境的响应。AI 智能体发出一个动作(比如点击按钮、输入命令),世界模型就预测环境会返回什么结果。整个训练过程可以完全在「虚拟世界」里进行,不需要真实环境参与。
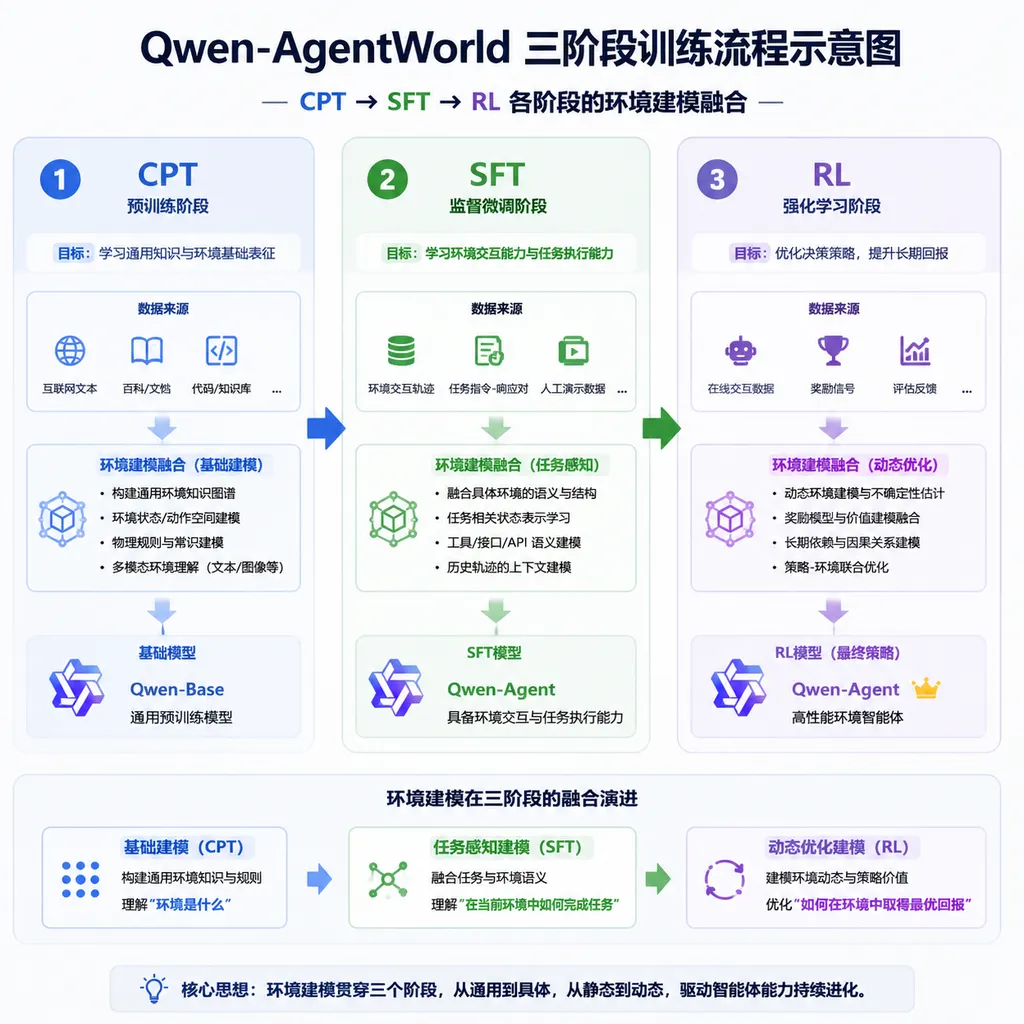
这个思路并不新鲜,但之前的实现方式通常是:先训练好一个通用大模型,再针对特定环境做微调。Qwen-AgentWorld 的做法不同——环境建模从继续预训练(CPT)阶段就开始了,贯穿 CPT → SFT → RL 全流程。这就是「原生」的含义。
打个比方:之前的方案像是给一个成年人恶补某个领域的知识,而 Qwen-AgentWorld 是从小就在这个环境里长大的「原住民」。
一个模型,七大领域
更有意思的是覆盖范围。Qwen-AgentWorld 用单一模型同时支持七个智能体交互领域:
文本类环境:
- MCP:Model Context Protocol,AI 调用外部工具的标准协议
- Search:搜索引擎交互
- Terminal:命令行操作
- SWE:软件工程环境,代码仓库级别的操作
GUI 类环境:
- Web:网页浏览和操作
- OS:桌面操作系统
- Android:移动端应用
为什么要塞到一个模型里?因为这些领域之间有大量可迁移的知识。你在终端里学会的目录操作概念,在文件管理器 GUI 里也能用;你在网页上学会的表单填写逻辑,在移动端也是类似的。单一模型可以实现跨领域知识迁移,而不是每个领域单独训练一个专家模型。
从技术路线上看,这是一个相当激进的选择。很多团队会选择「小而专」的路线,针对特定领域做深度优化。千问选择了「大而全」,用更大的模型容量来换取通用性。
两个尺寸,对标旗舰
Qwen-AgentWorld 提供两个规格:
| 规格 | 总参数量 | 激活参数量 | 定位 | |------|----------|------------|------| | 35B-A3B | 350 亿 | 30 亿 | 轻量部署 | | 397B-A17B | 3970 亿 | 170 亿 | 旗舰性能 |
从命名规则看,这是 MoE(混合专家)架构,A 后面的数字是激活参数量。397B-A17B 意味着虽然总参数接近 4000 亿,但单次推理只激活 170 亿参数,在性能和效率之间取得平衡。
官方给出的对比数据:在自家的 AgentWorldBench 评测中,Qwen-AgentWorld-397B-A17B 的整体模拟质量超过了 GPT-5.4、Claude Opus 4.8 和 Gemini 3.1 Pro。
这个对比需要谨慎看待。首先,这是在千问自己设计的评测基准上的结果;其次,「模拟质量」是一个复合指标,具体怎么算的还需要看技术报告。但至少说明这个模型在环境模拟这个特定任务上,已经达到了第一梯队的水平。
训练数据:超过 1000 万条真实交互轨迹
语言世界模型的质量,很大程度上取决于训练数据的质量和规模。Qwen-AgentWorld 基于超过 1000 万条真实环境交互轨迹训练而成。
这个数据量相当可观。每条轨迹包含:智能体的动作序列、环境的状态变化、最终的执行结果。收集这些数据需要在真实环境中运行大量的智能体任务,记录下完整的交互过程。
数据来源可能包括:
- 内部智能体系统的日志
- 公开的智能体评测数据集
- 合成生成的交互轨迹
具体比例官方没有披露,但从覆盖七个领域来看,数据的多样性应该是重点投入方向。
AgentWorldBench:配套的评测基准
同步发布的还有 AgentWorldBench,这是一个覆盖七大领域的语言世界模型评测基准。
这个基准有个关键特点:每条测试样本都配备了真实环境执行所得的观测数据。也就是说,评测时不是让模型凭空想象环境应该怎么响应,而是对比模型的预测和真实环境的实际响应,看两者有多接近。
这种评测方式更加客观,也更能反映模型在实际应用中的表现。
模型和评测基准都可以从 Hugging Face 和 ModelScope 获取,这意味着其他研究团队可以复现结果、进行对比研究。
两种应用范式
千问在技术文档中描述了 Qwen-AgentWorld 的两种应用方式:
范式一:解耦的环境模拟器
把 Qwen-AgentWorld 当作一个独立的环境模拟器,用来训练其他智能体模型。
传统的智能体强化学习需要在真实环境中采样,这带来几个问题:
- 成本高:真实环境的计算资源、API 调用都要花钱
- 速度慢:受限于真实环境的响应速度
- 不可控:很难构造特定的边界情况来测试
用语言世界模型替代真实环境后,这些问题都能缓解。而且,模拟环境可以实现一些真实环境做不到的事情——比如可控的场景构造。你可以让模拟环境故意返回各种异常情况,强迫智能体学会处理边界 case。
官方实验显示:在模拟环境中训练的智能体,效果显著优于仅在真实环境中训练的智能体。这验证了「可控模拟」的价值。
范式二:统一的智能体基础模型
更有想象力的用法是:把 Qwen-AgentWorld 本身当作智能体的基础模型。
逻辑是这样的:一个能准确预测环境响应的模型,对环境的理解一定是深刻的。这种理解可以迁移到智能体任务上——不需要额外的强化学习微调,直接用世界模型来执行任务。
官方的验证结果:经过世界模型预训练后,模型可以有效迁移到涵盖七个基准的多轮智能体任务,其中三个基准完全没有出现在训练集中。这说明模型学到的是通用的环境交互能力,而不是死记硬背特定任务的解法。
这个方向如果走通,意味着未来的智能体开发流程可能会变成:先在世界模型上做大规模预训练,获得通用的环境理解能力,再针对具体任务做轻量级适配。
放在行业背景下看
语言世界模型并不是千问的独创概念。OpenAI、DeepMind、Meta 都有相关的研究工作。但 Qwen-AgentWorld 的特点在于:
- 原生建模:从预训练阶段就融入环境建模,而不是事后适配
- 多领域统一:单一模型覆盖文本和 GUI 两大类、七个具体领域
- 开源发布:模型和评测基准都对外开放
特别是第三点,在当前的开源生态中很有价值。智能体是大模型应用落地的关键方向,但高质量的环境模拟器一直是稀缺资源。Qwen-AgentWorld 的开源,可能会加速整个领域的研究进展。
千问的智能体野心
把这次发布放在千问的产品线中看,逻辑就更清晰了。
今年 1 月,千问 App 上线了「任务助理」功能,打通淘宝、支付宝、飞猪、高德等阿里生态,让 AI 可以直接帮用户下单、订票、叫车。这是智能体在 C 端的落地。
4 月发布的 Qwen3.6-Plus 强化了编程和智能体能力,在 SWE-bench 等评测中表现突出。这是智能体在开发者场景的落地。
现在发布的 Qwen-AgentWorld,则是智能体训练基础设施的布局。
三步棋连起来看:千问不只是要做一个能干活的智能体,而是要建立一套完整的智能体研发和部署体系。从基础模型、到训练方法、到应用落地,全链条都要覆盖。
这个战略思路和 OpenAI 的 Operator、Anthropic 的 Computer Use 形成了正面竞争。区别在于,千问选择了开源路线,试图通过生态建设来获取竞争优势。
实际应用:谁会用这个模型?
从应用场景看,Qwen-AgentWorld 的目标用户主要是:
1. 智能体研发团队
如果你在开发 AI 智能体产品,Qwen-AgentWorld 可以作为训练环境的替代品,降低数据采集成本,加速迭代周期。
2. 学术研究者
智能体和强化学习是学术热点,但真实环境的实验成本很高。一个高质量的开源世界模型,可以让更多研究者参与进来。
3. 企业自动化场景
对于需要大规模部署 RPA(机器人流程自动化)的企业,Qwen-AgentWorld 可以用来预训练自动化脚本,提高任务成功率。
当然,这些应用都还需要时间验证。模型刚发布,实际效果如何,还要看社区的反馈。
技术细节的一些推测
官方的技术文档还没有完全公开,但从已有信息可以做一些推测:
架构方面:大概率基于 Qwen 系列的 MoE 架构,397B-A17B 的规格和之前的 Qwen 模型一致。可能在 attention 机制上做了针对序列预测的优化。
训练方面:CPT 阶段应该是用「动作-观测」序列来构造训练数据,让模型学习 P(observation | action, context) 这个条件概率。SFT 和 RL 阶段则是针对模拟质量和一致性进行优化。
推理方面:作为环境模拟器使用时,需要支持自回归式的多轮交互。这对上下文管理和一致性维护提出了较高要求。
具体细节还是要等技术报告出来才能确认。
值得关注的后续发展
这次发布是一个开始,后续值得关注的点包括:
- 技术报告的详细内容:训练方法、数据构造、评测细节
- 社区的复现和对比:其他团队在 AgentWorldBench 上的表现
- 下游应用的落地:有没有团队基于 Qwen-AgentWorld 做出实际产品
- 与其他世界模型的对比:比如 DeepMind 的 Genie、Meta 的相关工作
语言世界模型是一个正在快速发展的方向,千问这次的发布,至少证明了这条路线的可行性。至于能走多远,还要看后续的研究和应用验证。
参考来源
- 阿里千问发布首个原生语言世界模型 Qwen-AgentWorld - IT之家对本次发布的详细报道


