Grok登陆谷歌云,昔日对手变房东

Google Cloud Vertex AI 近日上架 xAI 的 Grok 4.1 Fast 和 Grok 4.20 共三款模型,这是马斯克系 AI 模型首次登陆谷歌云平台,开发者可通过 Vertex API 直接调用。
马斯克的模型,搬进了谷歌的地盘
Google Cloud Vertex AI 近日悄然上架了三款来自 xAI 的 Grok 模型:Grok 4.1 Fast(Reasoning)、Grok 4.1 Fast(Non-Reasoning)以及 Grok 4.20(Non-Reasoning)。
没有发布会,没有博客长文,就这么直接出现在了 Vertex 的模型列表里。但这件事本身的信号意义,远比上架动作本身要大得多——这是马斯克旗下 xAI 的模型,第一次正式登陆谷歌的云基础设施。
要知道,马斯克和谷歌在 AI 领域的关系,用"微妙"来形容都算客气了。从早年共同创立 OpenAI 到后来反目,从公开抨击谷歌的 AI 安全立场到 xAI 以挑战者姿态入场,这两家在舆论场上几乎没有和平共处过。但商业就是商业,模型需要分发渠道,云平台需要丰富的模型生态。Vertex 上架 Grok,本质上是双方各取所需。
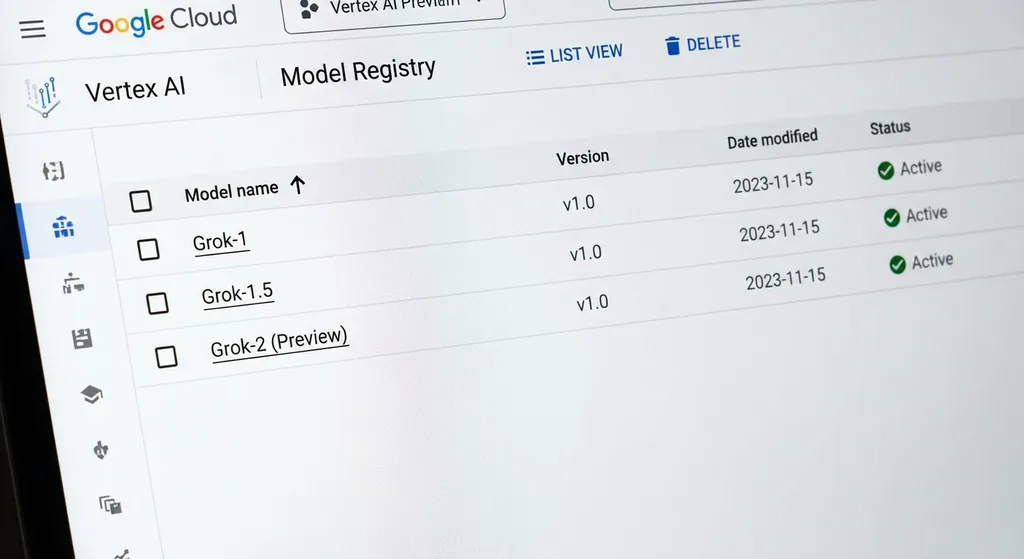
上架了哪些模型?各自什么定位?
这次上架的三款模型,定位各有不同,值得拆开来看:
- Grok 4.1 Fast(Reasoning):带推理能力的快速版本。可以理解为 Grok 4.1 Thinking 的轻量化部署版,保留了链式推理能力,但在推理延迟上做了优化。适合需要逻辑推导但对响应速度有要求的场景。
- Grok 4.1 Fast(Non-Reasoning):不带推理链的快速版本。直接输出答案,不展示思考过程,响应速度最快。适合对话、内容生成、信息提取等不需要复杂推理的日常任务。
- Grok 4.20(Non-Reasoning):xAI 最新发布的迭代版本,今年 2 月马斯克在 X 平台预告时称"较 4.1 版改进重大"。目前在 Vertex 上以非推理模式上架。
一个有意思的细节:Vertex 上架的是 "Fast" 变体,而不是完整的 Grok 4.1 或 Grok 4.1 Thinking。这说明 xAI 在云端分发策略上做了取舍——把推理速度更快、部署成本更低的版本优先推向第三方平台,完整版大概率还是留给自家 API 和 Grok 客户端。
这个策略其实很聪明。对于通过 Vertex 接入的企业开发者来说,Fast 版本在绝大多数生产场景下已经够用,而且成本和延迟更可控。
回顾一下:Grok 4.1 到底有多能打?
要理解这次上架的分量,得先回顾 Grok 4.1 本身的实力。
2025 年 11 月 17 日,xAI 发布 Grok 4.1,直接在 LMArena 文本排行榜上完成了"双冠"操作:Grok 4.1 Thinking 以 1483 Elo 登顶,非推理版 Grok 4.1 以 1465 Elo 拿下亚军,比 Gemini 2.5 Pro 高出 31 分。
这个成绩放在当时的竞争格局里相当炸裂。O3、Claude Sonnet 4.5、Kimi K2 这些强势选手全部被甩开,形成了明显的档位差。
几个关键数据:
- 幻觉率:从前代的 12.09% 降到 4.22%,降幅接近三倍。这在信息检索和事实性问答场景里是质的飞跃。
- 用户偏好:在为期两周的双盲 A/B 测试中,64.78% 的用户在不知情的情况下选择了 Grok 4.1 的回答。超过六成的偏好率,说明提升是用户可感知的,不是刷榜刷出来的。
- 情感智能:在 EQ-Bench3 测试中,Grok 4.1 的推理和非推理模式包揽前两名,在情绪理解、同理心、人际交往技能等维度上全面领先。
技术层面,xAI 沿用了 Grok 4 的大规模强化学习基础设施,但引入了一个关键创新:用前沿推理模型作为奖励模型。传统的 RLHF 依赖人类标注反馈,而 xAI 的方案让 AI 模型自己当裁判,能够大规模自主评估输出质量并快速迭代。这直接带来了更稳定的风格输出和更低的幻觉率。
而 Grok 4.20 作为 4.1 的后续迭代,马斯克在今年 2 月预告时用了"改进重大"这个措辞。从 Vertex 上架的节奏来看,4.20 应该已经完成了内部验证,进入了对外分发阶段。
这件事为什么值得关注?
模型上架云平台,这事本身不新鲜。Anthropic 的 Claude 在 AWS Bedrock 和 Google Vertex 上都有,Meta 的 Llama 更是到处都是。但 Grok 上 Vertex,有几层不一样的意思。
第一,竞争关系的重新定义。
谷歌自己有 Gemini,而且 Gemini 2.5 Pro 一直是 Vertex 上的头牌模型。现在把直接竞品 Grok 也放上来,说明谷歌在云业务上的策略越来越"平台化"——不再执着于只推自家模型,而是把 Vertex 打造成一个模型超市。AWS Bedrock 早就这么干了,谷歌现在跟上了。
对开发者来说这是好事。你不用为了用 Grok 就去对接 xAI 的 API,也不用为了用 Claude 就开 AWS 账号。一个 Vertex 项目,主流模型都能调。
第二,xAI 的分发策略在变。
早期的 xAI 更像一个封闭生态——Grok 主要通过 X 平台和自家 API 触达用户。但把模型放到 Vertex 上,意味着 xAI 开始认真对待企业级分发。毕竟,大量企业客户的基础设施就建在 GCP 上,让他们为了一个模型去搭新的 API 对接链路,摩擦成本太高。
第三,模型市场的"去阵营化"。
一年前,大家还在讨论 AI 领域会不会形成类似移动互联网时代的阵营对立——谷歌系、OpenAI 系、Meta 系各自为战。但现在的趋势越来越清晰:模型层在走向商品化,云平台在走向中立化。马斯克的模型跑在谷歌的 GPU 上,这在两年前是不可想象的,但在 2026 年,它就这么自然地发生了。
开发者怎么用?
如果你已经在用 Vertex AI,接入 Grok 模型的方式和调用其他模型没有本质区别。Vertex 的统一 API 层会处理底层的模型路由。
当然,对于很多国内开发者来说,直接访问 Vertex AI 可能存在网络和账号门槛。这种情况下,通过 OpenAI 兼容格式的 API 聚合服务来调用是更实际的选择。比如 OpenAI Hub 就支持以统一的 OpenAI 格式调用包括 Grok 在内的多家模型,国内直连,省去了折腾基础设施的麻烦。
下面是一个通过 OpenAI 兼容格式调用 Grok 模型的示例:
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.openai-hub.com/v1"
)
# 调用 Grok 4.1 Fast(非推理模式)
response = client.chat.completions.create(
model="grok-4.1-fast",
messages=[
{"role": "system", "content": "你是一个有帮助的助手。"},
{"role": "user", "content": "用简洁的语言解释一下大语言模型中的 RLHF 是什么?"}
],
temperature=0.7,
max_tokens=1024
)
print(response.choices[0].message.content)
# 调用 Grok 4.1 Fast(推理模式)
response = client.chat.completions.create(
model="grok-4.1-fast-reasoning",
messages=[
{"role": "user", "content": "一个水池有两个进水管和一个出水管。A管单独注满需要6小时,B管单独注满需要8小时,出水管单独放完需要12小时。三管同时打开,多久能注满水池?"}
],
temperature=0.0
)
print(response.choices[0].message.content)
# 调用 Grok 4.20(非推理模式)
response = client.chat.completions.create(
model="grok-4.20",
messages=[
{"role": "user", "content": "帮我写一段 Python 代码,实现一个简单的 LRU 缓存。"}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
三款模型的选择建议:
| 模型 | 适用场景 | 特点 | |------|----------|------| | Grok 4.1 Fast (Reasoning) | 数学推理、逻辑分析、代码调试 | 带思维链,准确率高,延迟稍高 | | Grok 4.1 Fast (Non-Reasoning) | 对话、内容生成、信息提取 | 响应快,成本低,适合高并发 | | Grok 4.20 (Non-Reasoning) | 通用任务、创意写作、复杂对话 | 最新迭代,综合能力更强 |
Grok 4.1 vs 4.20:升级了什么?
虽然 Grok 4.20 的完整技术细节还没有公开的详尽报告,但从已知信息可以拼出一些轮廓。
马斯克在 2 月的预告中说"改进重大",结合 Grok 4.1 的已知短板来推测,4.20 大概率在以下方向做了重点优化:
- 长上下文能力:4.1 在超长文本处理上还有提升空间,4.20 很可能扩展了有效上下文窗口或改善了长距离信息检索的准确率。
- 多模态增强:4.1 已经展示了不错的图像生成能力,4.20 可能在多模态理解和生成上进一步打通。
- 指令遵循的一致性:这是所有大模型的持续优化方向,尤其在复杂多步骤指令场景下。
从 Vertex 上架的形态来看,4.20 目前只有 Non-Reasoning 版本,没有 Reasoning 变体。这可能意味着两件事:要么 4.20 的推理版本还在调优中,后续会补上;要么 xAI 认为 4.20 的基础能力已经足够强,不需要额外的推理链就能处理大多数任务。
后者如果成立,倒是一个有趣的技术方向——通过提升基础模型的能力上限,减少对显式推理链的依赖。这和 OpenAI 在 GPT 系列上的演进思路有些相似。
云平台模型大战的新格局
把视角拉远一点,Vertex 上架 Grok 是云平台模型生态竞争的一个缩影。
目前主流云平台的模型阵容大致是这样的:
- AWS Bedrock:Claude(Anthropic)、Llama(Meta)、Mistral、Cohere、Stability AI 等
- Google Vertex AI:Gemini(自家)、Claude(Anthropic)、Llama(Meta)、Mistral,现在加上 Grok(xAI)
- Azure:GPT 系列(OpenAI)、Llama(Meta)、Mistral 等
谷歌这步棋走得挺聪明。Vertex 之前在第三方模型丰富度上不如 Bedrock,现在拿下 Grok 这个独家(至少目前 Bedrock 上还没有),算是补上了一块拼图。而且 Grok 在 LMArena 上的成绩摆在那里,对于在意模型质量的企业客户来说,多一个强力选项总不是坏事。
对 xAI 来说,Vertex 的企业客户基础是现成的分发渠道。xAI 自己的 API 平台虽然也在运营,但在企业级销售、合规认证、SLA 保障这些方面,跟 GCP 这种成熟云平台比还有差距。借力打力,是当前阶段最务实的选择。
写在最后
马斯克的 AI 模型跑在谷歌的云上,这个画面放在两年前大概会被当成段子。但 2026 年的 AI 行业,务实正在取代站队。
模型厂商需要分发,云平台需要生态,开发者需要选择。当这三方的利益对齐时,再深的"恩怨"也挡不住商业逻辑。
对开发者来说,这是个好消息。不管你是在 GCP 上用 Vertex 直接调用,还是通过 OpenAI Hub 这样的聚合平台一个 Key 打通所有模型,可选项都在变多,接入成本都在变低。
至于 Grok 4.20 的完整实力到底如何,等更多开发者上手测试后,答案自然会浮出水面。
参考来源
- Vertex 已上架 Grok 三款模型 — Linux.do 社区讨论帖,首次披露 Vertex 上架 Grok 模型的信息
