欧盟押注意大利,400B参数要抢AI主权

欧盟委员会选定意大利公司 Domyn 领导"Europa 联盟",将打造 400B 参数的欧洲本土大模型,配合 115 exaflops 算力的超算基础设施,这是欧洲迄今最激进的 AI 主权行动。
欧盟押注意大利,400B参数要抢AI主权
欧盟委员会本周宣布,将欧洲 AI 战略的核心任务交给一家意大利公司。
Domyn——这家总部位于米兰、由 92 年出生的阿尔巴尼亚裔创始人 Uljan Sharka 领导的公司,将牵头组建名为"Europa"的欧洲 AI 联盟,负责训练一个超过 400B 参数的大型语言模型。
这是欧洲迄今为止最激进的 AI 主权行动。不是口号,是真金白银的投入和明确的技术路线。
为什么是 Domyn?
说实话,这个选择出乎很多人意料。
在欧洲 AI 版图上,法国的 Mistral 声量更大,德国有强大的工业 AI 应用基础,北欧在开源社区里也有相当影响力。但欧盟委员会的评估结论是:Domyn 在"战略愿景、执行能力及潜在影响力方面均表现最为突出"。
仔细看 Domyn 的背景,这个选择有其逻辑。
Domyn 的前身是 iGenius,从成立之初就专注于一个细分赛道:为受监管的关键行业提供 AI 解决方案。银行、保险、医疗、能源——这些行业对数据主权、合规性、可审计性有极高要求,恰好是欧盟最关心的议题。
公司目前的旗舰产品是 Domyn Large,一个 260B 参数的语言模型。单看参数规模,放在全球市场里不算突出——GPT-4 的参数量众说纷纭但普遍认为在万亿级别,Claude 3.5 Opus 也被认为超过了这个量级。但 Domyn Large 的定位不是通用聊天,而是"高度关键的企业应用场景",强调的是可控、可解释、可审计。
这和欧盟的诉求高度契合。

115 exaflops:算力军备竞赛的欧洲答卷
训练 400B 参数的模型需要多少算力?这是个绕不开的问题。
作为参考,Meta 训练 Llama 3 405B 用了约 16000 块 H100,耗时数月。如果要追赶 GPT-4、Claude 3.5 这样的第一梯队模型,算力需求还要翻几倍。
Domyn 的答案是"Colosseum"——一个正在建设中的超算基础设施,中文直译就是"斗兽场"。
根据官方披露的数据:
- GPU 架构:NVIDIA Grace Blackwell 超级芯片
- 峰值算力:超过 115 exaflops
- 目标能力:支持万亿参数量级的模型训练与推理
115 exaflops 是什么概念?
目前全球最快的超级计算机是美国橡树岭国家实验室的 Frontier,峰值算力约 1.7 exaflops(FP64)。当然,AI 训练通常用 FP16 或 FP8 精度,Colosseum 的 115 exaflops 大概率也是低精度算力,两者不能直接对比。但即便如此,这个数字也足够惊人。
如果 Colosseum 能按计划建成,它将是欧洲最大的 AI 专用超级计算机,没有之一。
这不是 Domyn 一家在玩。NVIDIA 已经确认参与合作,意大利政府也在背后提供支持。某种程度上,这是欧洲版的"举国体制"。
欧洲的焦虑:不只是技术落后
理解这个项目,需要先理解欧洲的焦虑。
2026 年 2 月,欧盟委员会正式启动"前沿 AI 重大挑战"计划。这个计划的出发点很直接:欧洲不能永远当技术消费者。
目前的现实是残酷的。全球最强的 AI 模型,OpenAI 的 GPT 系列、Anthropic 的 Claude、Google 的 Gemini,全部来自美国。中国的 DeepSeek、阿里通义、字节豆包也在快速追赶。欧洲呢?Mistral 做得不错,但体量和影响力还是差了一个数量级。
这种差距带来的风险,已经超出了纯技术层面:
1. 数据安全
当欧洲企业使用美国或中国的 AI 服务时,数据必然要流向这些公司的服务器。即使有各种隐私协议和合规承诺,数据一旦出境,控制权就不在自己手里了。
对于金融、医疗、国防这些敏感行业,这是个真实的顾虑,不是杞人忧天。
2. 监管主导权
欧盟的《人工智能法案》是全球最严格的 AI 监管框架。但如果欧洲自己没有强大的 AI 产业,这套监管框架就只能是"管别人"——美国公司、中国公司可以选择遵守或者不遵守,欧洲没有太多筹码。
只有当欧洲有自己的头部 AI 企业,监管者和被监管者才能形成真正的对话和博弈。
3. 语言和文化的边缘化
这一点经常被忽视,但可能是最深远的影响。
当前主流 AI 模型的训练数据以英语为主,不可避免地带有盎格鲁-撒克逊文化的倾向。法语、德语、意大利语、西班牙语……这些语言在训练数据中的占比远低于其实际使用人口。
结果就是:用这些语言和 AI 对话时,模型的表现明显不如英语;更隐蔽的是,模型对这些文化背景下的常识、习俗、法律体系理解不足,容易给出"美国视角"的回答。
欧盟有 24 种官方语言。如果本土模型能够以同等水准处理所有这些语言,语言多样性就能从"结构性劣势"变成"竞争优势"。
400B 参数够用吗?
回到技术层面,一个现实的问题:400B 参数在 2026 年的 AI 竞争中处于什么位置?
先看当前的第一梯队:
| 模型 | 参数规模(估计) | 发布时间 | |------|-----------------|----------| | GPT-4 | 1T+ (MoE) | 2023.3 | | GPT-4o | 未公开 | 2024.5 | | Claude 3.5 Opus | 未公开,传闻 500B+ | 2024.3 | | Gemini Ultra | 未公开,传闻 1T+ | 2023.12 | | Llama 3.1 405B | 405B | 2024.7 | | DeepSeek-V3 | 671B (MoE) | 2024.12 |
从参数量看,400B 大致处于 Llama 3.1 405B 的水平,比 GPT-4、Claude 3.5 Opus 小,但也不算小。
不过,参数量从来不是决定模型能力的唯一因素。
DeepSeek-V3 用 671B 参数(MoE 架构,实际激活参数约 37B)在很多基准测试上打平甚至超过了 GPT-4。这说明架构设计、训练数据质量、训练方法的创新,有时候比单纯堆参数更重要。
欧盟的 400B 模型如果:
- 在欧洲多语言处理上做到业界最佳
- 在合规性、可解释性、可审计性上建立标杆
- 针对金融、医疗、法律等垂直领域深度优化
那它不需要在通用能力上和 GPT-5 硬碰硬,也能找到自己的生态位。
这大概也是欧盟的务实选择:不追求"全球最强",但要做到"欧洲最适合"。
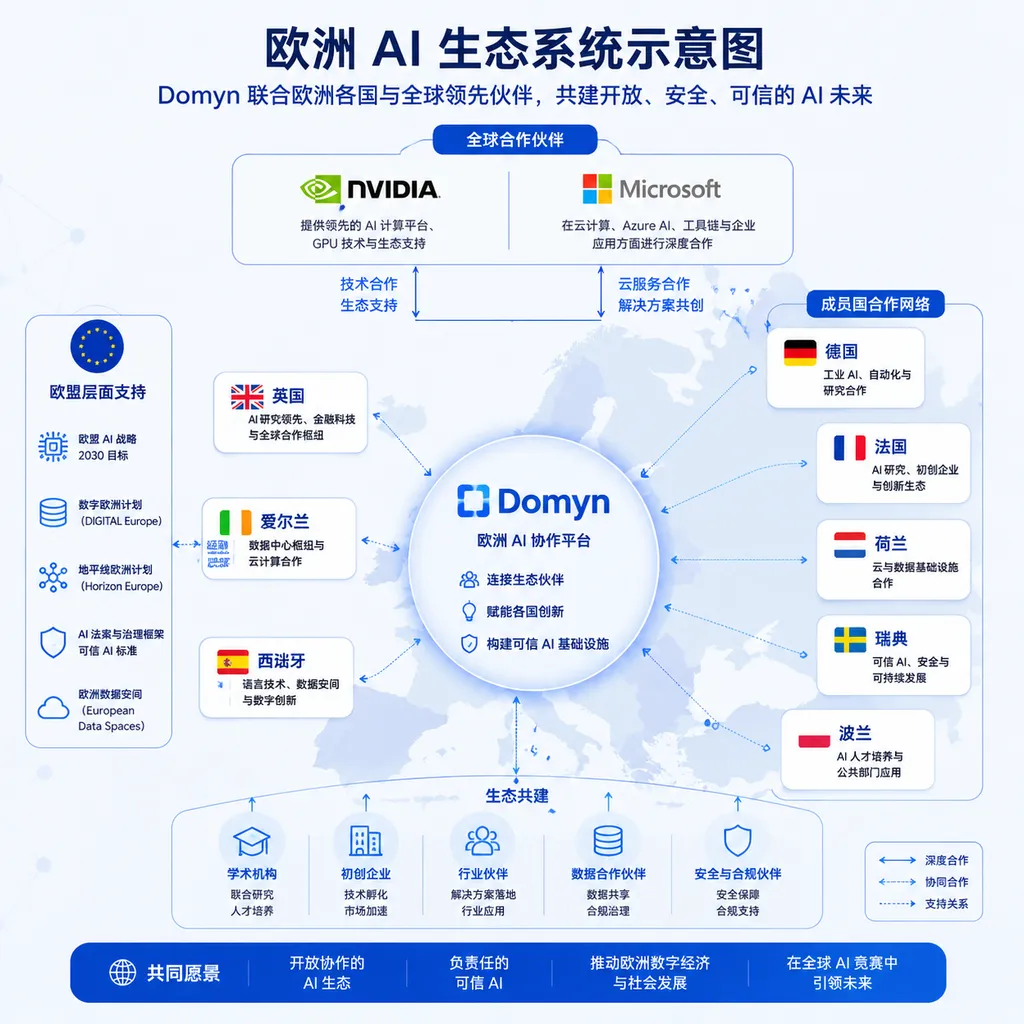
合作伙伴:美国巨头也在牌桌上
有意思的是,这个"主权 AI"项目并没有排斥美国公司。
根据公开信息,Domyn 的战略合作伙伴包括:
- 微软:云基础设施和企业服务
- NVIDIA:GPU 和训练框架
- 多家国际金融与工业集团:应用场景和数据
NVIDIA 的参与尤其深入。除了提供 Grace Blackwell 芯片,NVIDIA 还在帮助 Domyn 使用 Nemotron 技术优化模型——包括神经架构搜索、知识蒸馏、基于合成数据的后训练等。
这种合作模式很务实:欧洲目前没有能和 NVIDIA 竞争的 AI 芯片公司,硬件层面的依赖短期内无法摆脱。但只要模型本身在欧洲训练、数据在欧洲存储、运营在欧洲治理框架下进行,"主权"的核心诉求就能得到满足。
当然,这也是一种风险对冲。如果中美关系进一步恶化,或者美国对 AI 技术出口实施更严格的管控,欧洲至少已经有了自己的模型和算力基础,不会突然断供。
GPAI 行为准则:和 OpenAI、Google 坐在同一张桌子上
Domyn 还有一个身份值得注意:它是欧洲通用人工智能(GPAI)行为准则的签署方之一。
这个准则的其他签署方包括:
- OpenAI
- 微软
- 亚马逊
- IBM
- Mistral AI
这意味着 Domyn 已经被纳入全球顶级 AI 公司的"俱乐部",至少在监管合规层面拥有了对等的话语权。
对于欧盟来说,这也是一种背书:我们选的公司不是草台班子,是能和 OpenAI、Google 坐在同一张桌子上谈判的正规军。
更大的图景:欧洲 AI 生态的协同作战
Domyn 不是孤军奋战。
根据 NVIDIA 的官方博客,欧洲正在形成一个协同作战的 AI 模型构建者网络:
- 法国:H Company、LightOn
- 意大利:Domyn
- 波兰:Bielik.AI
- 西班牙:巴塞罗那超级计算中心(BSC)
- 瑞典:NAISS、KBLab(瑞典国家图书馆)
- 斯洛文尼亚:卢布尔雅那大学
- 斯洛伐克:国家级项目
- 英国:伦敦大学学院
这些机构正在开发支持欧洲 24 种官方语言的开放大语言模型,每个模型都针对本国语言和文化进行优化。它们将使用 NVIDIA Nemotron 技术进行蒸馏和后训练,部署在欧洲本土的 AI 基础设施上。
更有趣的是下游应用。Perplexity——那个每周处理超过 1.5 亿个问题的 AI 搜索引擎——已经宣布将这些欧洲主权模型集成到其平台中。这意味着普通用户很快就能在日常使用中体验到针对欧洲语言和文化优化的 AI 服务。
15 亿欧元和 7 个 AI 工厂
钱从哪里来?
早在 2024 年底,欧盟就宣布通过欧洲高效能运算联合组织(EuroHPC)投资 15 亿欧元,在欧洲建设 7 个"AI 工厂"(AI Gigafactories)。这些设施将提供大规模 AI 训练和推理所需的算力基础设施。
Domyn 的 Colosseum 超算可以视为这个更大布局中的一环。政府投资、私营企业运营、学术机构参与——这是欧洲试图复制美国 AI 生态成功经验的一次尝试。
当然,15 亿欧元听起来很多,但和美国 AI 公司的融资规模比起来还是小巫见大巫。OpenAI 最近一轮融资就拿了 66 亿美元,微软对 OpenAI 的累计投资超过 130 亿美元。
这再次说明,欧洲的策略不是在通用 AI 上和美国硬拼,而是在"主权"这个差异化赛道上建立优势。
技术细节:Colosseum 超算架构
对于关心技术细节的读者,这里整理一下 Colosseum 的已知信息:
硬件配置
- GPU:NVIDIA Grace Blackwell 超级芯片
- 互联:预计采用 NVLink 和 InfiniBand 组合
- 峰值算力:115+ exaflops(低精度)
软件栈
- 训练框架:与 NVIDIA 合作,大概率基于 NeMo 或类似框架
- 推理部署:支持 NVIDIA NIM 微服务
- 模型优化:Nemotron 技术(神经架构搜索 + 知识蒸馏)
运营模式
- 位置:意大利境内
- 治理:欧盟 AI 法案框架下
- 开放性:支持 Europa 联盟成员使用
Grace Blackwell 是 NVIDIA 最新一代 AI 芯片,相比 H100 有显著的性能提升,特别是在训练和推理的能效比上。选择这个芯片说明 Domyn 不是在用过时硬件凑合,而是真的要建一个有竞争力的基础设施。
风险和挑战
不过,也得泼点冷水。
1. 执行风险
从宣布计划到模型上线,中间有大量的执行工作。超算建设可能延期,模型训练可能遇到技术瓶颈,人才可能被美国公司挖走。欧洲历史上不乏雄心勃勃的科技计划最后不了了之的案例。
2. 生态竞争
即使模型训练成功,还要面对生态竞争的问题。OpenAI 有 ChatGPT 的亿级用户基础,Google 有搜索和安卓的分发渠道,Meta 有社交网络的嵌入场景。欧洲的 400B 模型靠什么获取用户?
3. 商业模式
"主权 AI"听起来很有吸引力,但愿意为此付费的客户有多少?企业客户选择 AI 服务,首先看的还是能力和成本,"数据主权"只是加分项。如果欧洲模型在核心能力上和 GPT-5 差距太大,光靠"主权"卖点可能不够。
4. 政治风险
欧盟是一个由 27 个成员国组成的联盟,内部协调从来不是易事。把核心任务交给意大利公司,法国和德国会不会有意见?如果下一届欧盟委员会换人,政策会不会调整?
这些风险都是真实存在的。但反过来说,不做的风险可能更大——继续依赖美国和中国的 AI 技术,长期来看对欧洲的数字主权是更大的威胁。
对开发者意味着什么?
如果你是在欧洲工作的开发者,或者服务欧洲客户的开发者,这个消息值得关注。
短期来看,变化不大。Domyn 的 400B 模型还在开发中,Colosseum 超算还在建设中。你今天还是该用什么用什么。
中期来看,可能会出现新的选择。当欧洲主权模型上线后,对于有数据合规要求的场景(金融、医疗、政府项目),它可能成为比 GPT、Claude 更合适的选择——不是因为能力更强,而是因为合规更简单。
长期来看,整个 AI 服务市场的格局可能会变化。如果"主权 AI"真的成为一个成熟的品类,不同地区可能会发展出各自的模型生态,而不是所有人都用同一套美国模型。这对开发者来说既是挑战(要适配更多模型)也是机会(更多的选择意味着更多的议价空间)。
目前来看,OpenAI Hub 这类 API 聚合平台已经支持市面上主流的大模型调用。如果未来欧洲主权模型开放 API 服务,大概率也会被接入到这类平台中,开发者的迁移成本应该不会太高。
结语
欧盟选择 Domyn 领导"Europa 联盟",是一个政治决定,也是一个技术决定,更是一个关于未来的赌注。
赌的是:在 AI 时代,技术主权和数据主权会变得越来越重要;赌的是:400B 参数配合欧洲本土算力,能够在特定场景下提供有竞争力的服务;赌的是:一个 92 年出生的阿尔巴尼亚裔意大利创业者,能够带领欧洲在全球 AI 竞争中找到自己的位置。
这个赌注会不会成功?说实话,现在下结论为时过早。但至少,欧洲终于不只是在嘴上喊"数字主权"了,而是开始动真格的。
这一步,迈得不算早,但总比不迈强。
参考来源
- 欧盟委员会选定意大利公司 Domyn 引领欧洲人工智能未来 - Linux.do 社区对该事件的详细报道和讨论
- 欧洲与 NVIDIA 合力建造 AI 基础设施 - 知乎专栏关于 NVIDIA 与欧洲合作的分析


