Haystack:被低估的生产级 AI 框架

deepset 开源的 Haystack 框架在 RAG 和 AI Agent 领域默默耕耘多年,如今已演进为成熟的生产级编排框架。相比 LangChain 的「大而全」,Haystack 走了一条更务实的路。
Haystack 不是新东西。这个由德国公司 deepset 开源的 AI 框架,早在 GPT-3 时代就已经存在。但直到最近,当越来越多团队开始把 RAG 和 Agent 应用推向生产环境,Haystack 的价值才真正显现出来。
一句话概括:Haystack 是一个专为生产环境设计的 AI 编排框架,用模块化管道(Pipeline)的方式构建 RAG、语义搜索和 Agent 应用。
为什么现在值得关注
过去两年,LangChain 几乎成了 LLM 应用开发的代名词。但随着项目复杂度上升,不少团队开始抱怨:LangChain 的抽象层太厚,调试困难,生产部署时各种坑。
Haystack 走了另一条路。它的设计哲学很简单——每个组件做一件事,做好一件事,然后用管道把它们串起来。 这听起来像是软件工程的基本原则,但在 LLM 应用框架里,能真正做到的不多。
2.x 版本是个分水岭。deepset 几乎重写了整个框架,包名都从 farm-haystack 改成了 haystack-ai。新架构更轻量、更灵活,也更适合生产部署。
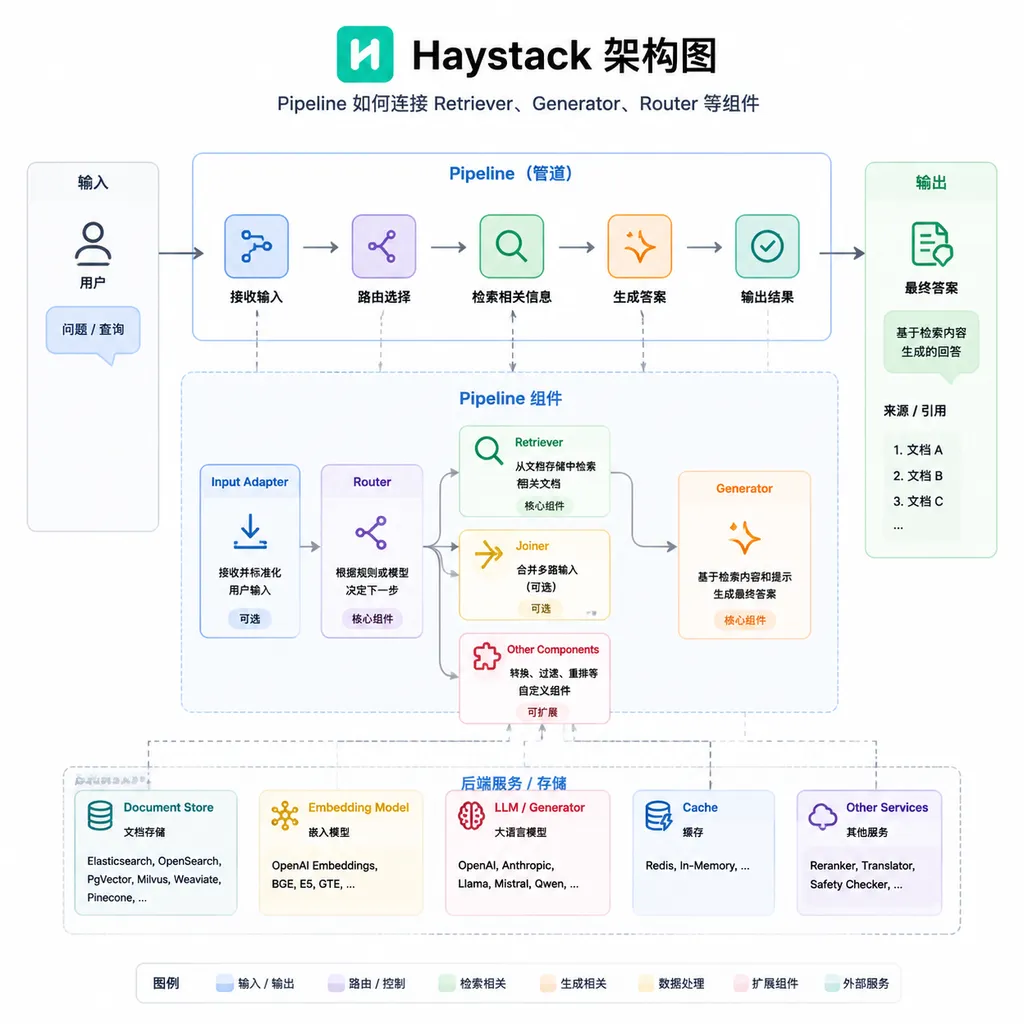
核心概念:三分钟看懂 Haystack
Component(组件)
Haystack 里一切皆组件。检索器是组件,生成器是组件,文本分割器也是组件。每个组件有明确的输入输出接口,像乐高积木一样可以自由拼装。
目前内置的组件覆盖了 AI 应用的核心场景:
- Retriever(检索器):从向量数据库或文档存储中找到相关内容
- Generator(生成器):调用 LLM 生成回答
- Embedder(嵌入器):把文本转成向量
- Router(路由器):根据条件分发请求到不同分支
- Agent(智能体):能调用工具、循环推理的自主组件
Pipeline(管道)
管道是 Haystack 的灵魂。它定义了数据如何在组件之间流动。一个典型的 RAG 管道长这样:
用户问题 → Embedder → Retriever → Prompt Builder → LLM → 回答
关键在于,这个管道是可序列化的。你可以把它导出成 YAML,扔进版本控制,在不同环境之间迁移,甚至用 CI/CD 自动部署。这对生产环境至关重要。
Document Store(文档存储)
Haystack 不绑定特定的向量数据库。Elasticsearch、Chroma、MongoDB、Pinecone、Qdrant、Weaviate——主流方案都有官方或社区集成。换数据库?改一行配置就行。
实战:构建一个 RAG 管道
说再多不如看代码。下面是一个最小化的 RAG 实现:
# 安装依赖
# pip install haystack-ai
from haystack import Pipeline, Document
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.retrievers.in_memory import InMemoryBM25Retriever
from haystack.components.builders import PromptBuilder
from haystack.components.generators import OpenAIGenerator
# 1. 准备文档存储
document_store = InMemoryDocumentStore()
document_store.write_documents([
Document(content="Haystack 是 deepset 开源的 AI 编排框架,支持构建 RAG 和 Agent 应用。"),
Document(content="Haystack 2.x 采用全新架构,包名是 haystack-ai,不要和旧版 farm-haystack 混淆。"),
Document(content="Haystack 支持多种文档存储后端,包括 Elasticsearch、Chroma、MongoDB 等。"),
])
# 2. 定义提示词模板
template = """
根据以下文档回答问题。如果文档中没有相关信息,请如实说明。
文档:
{% for doc in documents %}
- {{ doc.content }}
{% endfor %}
问题:{{ question }}
回答:
"""
# 3. 构建管道
pipeline = Pipeline()
pipeline.add_component("retriever", InMemoryBM25Retriever(document_store=document_store))
pipeline.add_component("prompt_builder", PromptBuilder(template=template))
pipeline.add_component("llm", OpenAIGenerator(model="gpt-4o-mini"))
# 连接组件
pipeline.connect("retriever", "prompt_builder.documents")
pipeline.connect("prompt_builder", "llm")
# 4. 执行查询
result = pipeline.run({
"retriever": {"query": "Haystack 支持哪些数据库?"},
"prompt_builder": {"question": "Haystack 支持哪些数据库?"}
})
print(result["llm"]["replies"][0])
这段代码做了四件事:
- 创建一个内存文档存储,写入几条示例文档
- 定义一个 Jinja2 模板作为提示词
- 用管道把检索器、提示词构建器、LLM 串起来
- 执行查询,拿到结果
注意 pipeline.connect() 这一步。Haystack 的管道连接是显式的,你能清楚看到数据从哪来、到哪去。调试的时候,这种透明性价值连城。
Agent:不只是 RAG
RAG 是 Haystack 的传统强项,但框架的野心不止于此。2.x 版本内置了 Agent 组件,支持工具调用和循环推理。
Agent 的核心思路是让 LLM 自己决定下一步做什么。遇到需要查资料的问题,它会调用检索工具;遇到需要计算的问题,它会调用计算工具;遇到复杂任务,它会拆解成子任务逐个解决。
from haystack.components.agents import Agent
from haystack.tools import Tool
# 定义一个简单的工具
def search_database(query: str) -> str:
"""搜索内部数据库"""
# 实际实现省略
return f"找到了关于 {query} 的 3 条记录"
search_tool = Tool(
name="search_database",
description="搜索公司内部数据库,查找相关信息",
function=search_database
)
# 创建 Agent
agent = Agent(
generator=OpenAIGenerator(model="gpt-4o"),
tools=[search_tool]
)
Haystack 的 Agent 实现相对保守,没有搞太多花哨的抽象。这反而是个优点——代码可预测,行为可解释,出了问题知道往哪查。
对比:Haystack vs LangChain vs LlamaIndex
三个框架经常被拿来比较,但定位其实有差异:
| 维度 | Haystack | LangChain | LlamaIndex | |------|----------|-----------|------------| | 核心定位 | 生产级 AI 编排 | 通用 LLM 应用框架 | 数据索引与查询 | | 设计哲学 | 显式管道,透明可控 | 链式调用,抽象丰富 | 索引优先,查询导向 | | 学习曲线 | 中等 | 较陡(抽象多) | 较平缓 | | 生产就绪 | 强(原生支持序列化、监控) | 中等(需要额外配置) | 中等 | | Agent 能力 | 内置,偏保守 | 丰富,类型多 | 支持,偏查询场景 | | 社区生态 | 中等规模,质量高 | 最大,但参差不齐 | 活跃,专注数据处理 |
选择建议:
- 如果你要快速原型验证,LangChain 的生态最丰富,能找到各种现成的链和工具
- 如果你的核心需求是文档索引和语义搜索,LlamaIndex 更专注
- 如果你要把 RAG 或 Agent 应用推向生产,Haystack 的工程化设计会省很多麻烦
没有银弹。选框架要看团队背景、项目阶段、具体需求。但如果「生产可靠性」是优先项,Haystack 值得认真考虑。
生产部署:Haystack 的硬实力
很多框架在 Jupyter Notebook 里跑得很欢,一到生产环境就露怯。Haystack 在这方面下了功夫。
管道序列化
# 导出管道为 YAML
pipeline.dump(open("rag_pipeline.yaml", "w"))
# 从 YAML 加载管道
loaded_pipeline = Pipeline.load(open("rag_pipeline.yaml"))
序列化意味着你可以:
- 把管道配置纳入版本控制
- 在开发、测试、生产环境使用同一份配置
- 实现管道的热更新,不用重启服务
云原生支持
Haystack 管道是 Kubernetes-ready 的。官方提供了部署指南,涵盖:
- 容器化最佳实践
- 水平扩展策略
- 健康检查和监控集成
- 日志和追踪配置
可观测性
生产环境最怕黑盒。Haystack 内置了详细的日志和追踪支持,每个组件的输入输出都可以记录。配合 deepset Studio(企业版工具),还能可视化调试管道执行流程。
文档存储:丰富的选择
Haystack 支持的文档存储后端相当全面:
向量数据库:
- Chroma(轻量级,适合原型)
- Qdrant(性能好,功能丰富)
- Pinecone(托管服务,省心)
- Weaviate(支持混合搜索)
- Milvus(大规模场景)
传统搜索引擎:
- Elasticsearch(全文搜索 + 向量)
- OpenSearch(AWS 生态)
通用数据库:
- MongoDB Atlas(文档数据库 + 向量)
- PostgreSQL + pgvector(关系型 + 向量)
换后端不需要改业务代码,只需要替换 Document Store 组件。这种设计让技术选型更灵活,也降低了迁移成本。
常见误区
整理几个新手容易踩的坑:
误区一:装错包
# 错误:这是 1.x 旧版,已停止维护
pip install farm-haystack
# 正确:这是 2.x 新版
pip install haystack-ai
两个包 API 完全不兼容,混装会出问题。如果你看到的教程用的是 farm-haystack,基本可以判断是过时内容。
误区二:以为只能做问答
Haystack 1.x 时代确实偏问答场景。但 2.x 已经是通用 AI 编排框架,能做的事情包括但不限于:
- RAG(检索增强生成)
- 语义搜索
- 文档分类
- 信息抽取
- 多模态应用
- 自主 Agent
误区三:觉得比 LangChain 功能少
Haystack 的集成数量确实不如 LangChain 多。但「集成多」不等于「功能强」。Haystack 的策略是做好核心功能,第三方集成通过社区扩展。质量往往比数量更重要。
适合什么场景
根据我的观察,Haystack 特别适合这几类团队:
1. 企业内部知识库
需要对接多种数据源、保证检索准确性、长期维护迭代。Haystack 的模块化设计让系统更容易演进。
2. 对可靠性要求高的场景
金融、医疗、法律等行业,模型输出需要可解释、可追溯。Haystack 的透明管道设计天然支持这一点。
3. 已有技术栈需要整合
公司已经在用 Elasticsearch 或 MongoDB,想加入 AI 能力。Haystack 的无绑定设计能直接对接现有基础设施。
4. 需要私有化部署
对数据安全敏感,不能把内容发到公有云。Haystack 完全开源,可以纯本地运行。
写在最后
回到开头的问题:为什么 Haystack 被低估?
一方面是营销。deepset 是德国公司,风格偏技术务实,不像硅谷创业公司那么会造势。LangChain 融资多、声量大,自然更容易占领心智。
另一方面是时机。Haystack 在 LLM 爆发之前就存在了,早期形象是「NLP 问答框架」。虽然 2.x 已经脱胎换骨,但品牌认知更新需要时间。
但技术选型不应该跟风。如果你正在做 RAG 或 Agent 应用,尤其是要推向生产环境,建议花几个小时试试 Haystack。它可能不会让你眼前一亮,但会让你后期少踩很多坑。
框架的价值不在于 Demo 跑得多炫,而在于生产环境里有多省心。
参考来源
- deepset-ai/haystack - GitHub:Haystack 官方仓库,包含完整源码、示例和贡献指南


