OpenAI 自研芯片 Jalapeño 发布,要从英伟达手里抢回算力定价权

OpenAI 发布首款自研 AI 推理芯片 Jalapeño,与博通合作设计,专为 LLM 推理优化。从设计到流片仅用 9 个月,计划 2026 年底部署,目标是打破英伟达对 AI 算力的垄断。
OpenAI 自研芯片 Jalapeño 发布,要从英伟达手里抢回算力定价权
OpenAI 今天官宣了自己的第一颗芯片:Jalapeño。
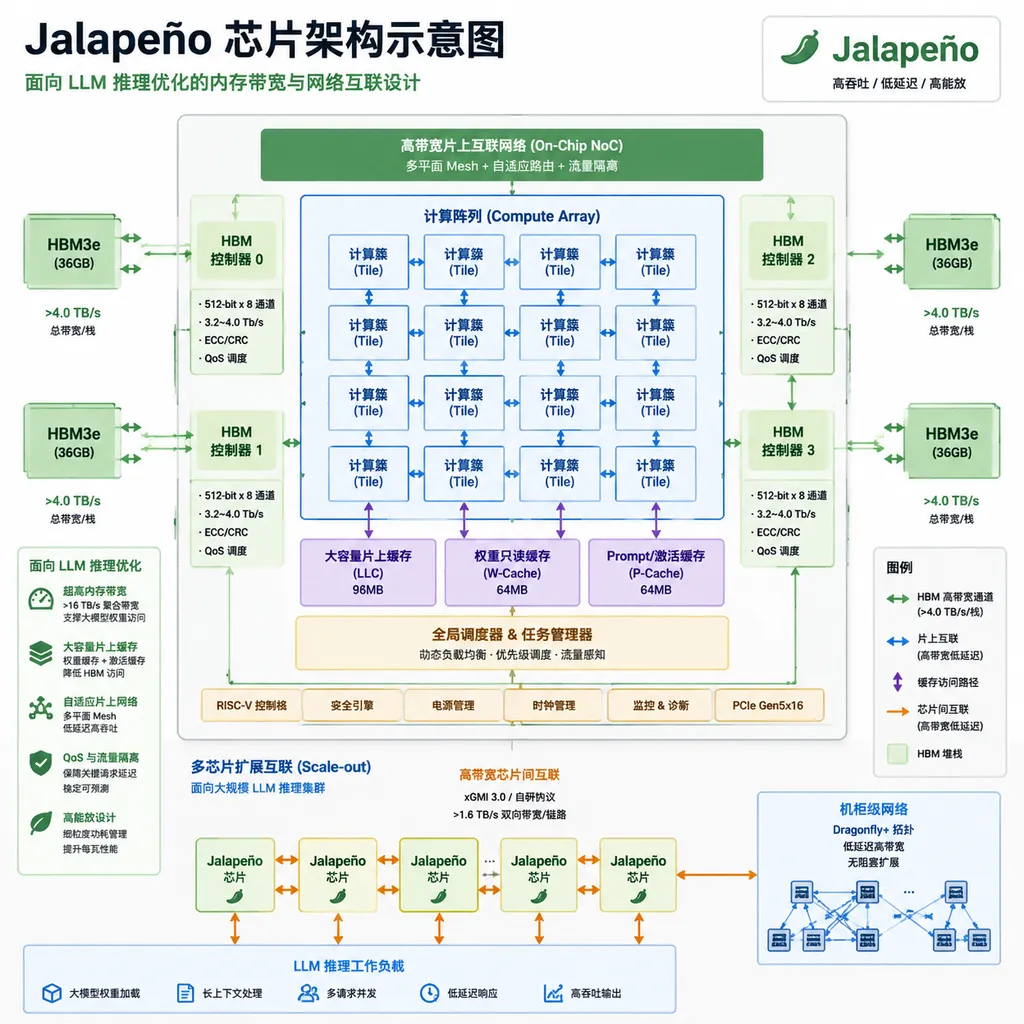
这颗芯片不做训练,只做推理——也就是让 ChatGPT 回答你问题、让 Codex 帮你写代码、让 API 响应开发者请求的那部分计算。OpenAI 说,Jalapeño 是从零开始设计的,不是在通用 AI 加速器上改改参数,而是完全围绕现代 LLM 的推理需求来做架构。
合作方是博通(Broadcom),硅谷最老牌的芯片代工巨头之一。从官宣的时间线看,这颗芯片从启动设计到 tape-out(流片)只用了 9 个月。OpenAI 特意提了一句:部分设计流程是用自家模型加速的。
工程样片已经在实验室跑起来了,测试负载包括 GPT-5.3-Codex-Spark。初步数据显示,Jalapeño 的每瓦性能明显优于当前最先进的方案——虽然 OpenAI 没点名,但大家都知道说的是英伟达的 H100/H200。
计划 2026 年底开始部署,规模是「吉瓦级」。
为什么 OpenAI 要自己做芯片?
答案很简单:钱。
推理成本是 OpenAI 商业化的命门。训练大模型是一次性投入,但推理是持续性支出——每个用户的每次对话、每个 API 请求、每个 Codex 任务,都要烧算力。ChatGPT 的日活用户早就过亿,高峰期的并发量是天文数字。
英伟达在 AI 芯片市场的份额超过 80%,定价权完全在它手里。H100 一张卡卖 3 万美元,还长期缺货。OpenAI、微软、谷歌、Meta 这些大客户,本质上是在给英伟达打工。
自研芯片的逻辑就是:把算力成本控制在自己手里。
这不是 OpenAI 一家在做。谷歌有 TPU,亚马逊有 Trainium 和 Inferentia,Meta 也在搞自己的 MTIA。但 OpenAI 的处境更特殊——它没有云业务可以分摊硬件成本,算力开销直接吃进利润表。
而且 OpenAI 的模型架构它最清楚。通用 GPU 是为各种负载设计的,在 LLM 推理这个具体场景上,一定有优化空间。Jalapeño 的设计就是把这些空间吃掉。
Jalapeño 到底优化了什么?
官方信息有限,但从公开的技术描述来看,Jalapeño 主要针对以下几个方向:
1. 内存带宽
LLM 推理是典型的内存带宽受限任务。生成每个 token 时,模型需要从显存里读取庞大的权重矩阵。以 GPT-4 级别的模型为例,参数量在数千亿级别,每次前向传播都要搬运海量数据。GPU 的计算单元经常在等数据,利用率上不去。
解决方案通常有两个方向:要么堆更大的显存带宽(贵),要么优化内存访问模式让数据搬运更高效(难)。Jalapeño 大概率两边都做了。
2. 稀疏计算
现代 LLM 越来越多地使用 Mixture of Experts(MoE)架构,比如 GPT-4 就被外界猜测是 MoE 结构。MoE 的特点是每次推理只激活部分专家网络,计算是稀疏的。通用 GPU 对稀疏计算的支持不够好,很多计算单元在空转。
专用芯片可以针对这种稀疏模式做硬件级优化,把空转的晶体管用起来。
3. 长上下文支持
128K 甚至更长的上下文窗口已经是主流。长上下文意味着 KV Cache 会变得很大,显存压力剧增。如何高效管理 KV Cache、如何在多卡之间切分长序列,都是工程难题。
通用方案是用 vLLM 这类框架做 PagedAttention,但硬件层面如果能原生支持这种访问模式,效率会更高。
4. 网络互联
大规模推理集群需要多卡甚至多机协同。卡间通信、机间通信的带宽和延迟,直接影响整体吞吐。博通在高速网络芯片领域有深厚积累,Jalapeño 和博通的网络技术做了深度整合。
官方还提到了 Celestica 的板卡和机架系统。这意味着 OpenAI 不只是做一颗芯片,而是在搭建完整的推理基础设施。
9 个月从设计到流片,怎么做到的?
芯片行业的传统节奏是 2-3 年一代。9 个月从设计到 tape-out,确实很快。
OpenAI 说部分流程是用自家模型加速的。这不是空话。EDA(电子设计自动化)工具链里有大量可以用 AI 优化的环节:
- 布局布线:芯片上数十亿晶体管怎么摆、怎么连,是个组合优化问题。传统方法靠启发式算法,AI 可以学习历史设计经验来加速搜索。
- 时序分析:确保信号在芯片上传输时满足时钟约束。AI 可以预测潜在的时序违例,减少迭代次数。
- 功耗优化:AI 可以在设计早期就预估功耗热点,指导架构调整。
谷歌 2021 年就发过论文,用强化学习做芯片布局,效果比人类工程师的方案更好。OpenAI 手握最强的 LLM,在 EDA 流程上吃到红利并不意外。
不过 9 个月只是 tape-out,离量产还有距离。流片回来要测试验证,发现问题可能要改版重流。计划 2026 年底部署,时间表其实挺紧的。
对英伟达的冲击有多大?
短期看,冲击有限。
Jalapeño 是推理芯片,不做训练。训练大模型还是得靠英伟达的 H100/H200/B100。而且 Jalapeño 只供 OpenAI 自己用,不会对外卖。英伟达的其他客户——云厂商、企业用户、研究机构——还是得买英伟达的卡。
但长期看,这是个信号。
AI 公司自研芯片的趋势已经很明显了。谷歌的 TPU 迭代到第五代,在自家云上跑得很好。亚马逊的 Trainium 2 也开始大规模部署。Meta 的 MTIA 还在早期,但方向很清晰。
这些玩家的共同点是:他们都是 AI 模型的设计者,最清楚自己的负载特点。通用 GPU 要兼顾游戏、科学计算、AI 训练、AI 推理等各种场景,不可能对每个场景都做到极致。自研芯片可以把所有晶体管预算都花在最需要的地方。
英伟达的护城河在于 CUDA 生态。过去十年,所有的 AI 框架、算子库、优化工具都是基于 CUDA 开发的。迁移到其他平台的成本很高。
但 OpenAI、谷歌、Meta 这些公司有能力自己写底层软件栈。他们不需要 CUDA,甚至不需要通用的 PyTorch/TensorFlow。针对自己的模型,写一套专用的推理引擎,效率可以更高。
黄仁勋显然看到了这个趋势。英伟达最近也在强调软件、强调云服务、强调 AI 全栈能力。单纯卖硬件的生意,护城河在变浅。
对开发者意味着什么?
如果你是通过 OpenAI API 调用 GPT、Codex 的开发者,Jalapeño 的部署可能带来几个变化:
1. 响应速度更快
推理芯片效率提升,首字延迟(Time to First Token)和生成速度都有望改善。尤其是高峰期,排队时间可能会缩短。
2. 成本可能下降
OpenAI 的算力成本降了,理论上有空间降价。当然,这取决于 OpenAI 的商业策略。也可能是保持现有价格,但提供更好的服务质量。
3. 更长的上下文、更复杂的任务
硬件能力上来了,模型能力的天花板也会提高。比如支持更长的上下文窗口、更复杂的 Agent 任务。Codex 能执行的代码量、能分析的代码库规模,都可能增加。
4. API 可用性更稳定
自研芯片意味着 OpenAI 对供应链的控制更强。不用担心英伟达缺货,不用和其他客户抢产能。服务稳定性有保障。
当然,这些都是 2026 年底以后的事。Jalapeño 刚流片,距离大规模部署还有一段时间。开发者现在能做的,就是继续用现有的 API,等 OpenAI 把基础设施升级做完。
全栈 AI 公司的野心
回看 OpenAI 过去两年的动作:
- 模型层:GPT-4、GPT-4o、GPT-5 系列持续迭代
- 产品层:ChatGPT、Codex、Sora、各种 Agent 产品
- 平台层:API、Plugin 生态、GPT Store
- 基础设施层:自建数据中心、自研芯片
这是一个完整的 full-stack AI 公司的布局。
和早期 OpenAI 的「研究机构」定位完全不同。Sam Altman 的野心是把 OpenAI 做成 AI 时代的基础设施供应商。模型、产品、算力,全部自己控制。
这个路径和苹果很像。苹果也是从软件(macOS、iOS)开始,然后做硬件(iPhone、Mac),最后自研芯片(M 系列、A 系列)。全栈整合带来的好处是:每一层都可以为其他层优化,整体效率最高。
当然,这也意味着更重的资产、更高的资本投入、更长的回报周期。OpenAI 最近几轮融资的估值已经到了 3000 亿美元级别,这个估值背后需要的是持续增长的收入和不断扩大的市场份额。
自研芯片是这个增长故事的重要一环。控制算力成本,才能控制毛利率;控制毛利率,才能支撑高估值。
写在最后
Jalapeño 这个名字挺有意思。墨西哥辣椒,小小一个但是很辣。OpenAI 的意思大概是:这颗芯片虽然是第一代,但能给推理性能带来「辣」的提升。
不过我更关心的是后续几代会叫什么。按这个风格,Ghost Pepper?Carolina Reaper?
玩笑归玩笑,Jalapeño 的发布确实是 AI 行业的一个重要节点。它标志着头部 AI 公司从「模型军备竞赛」进入「基础设施军备竞赛」的新阶段。
模型能力的竞争已经进入平台期。GPT-4 级别的能力,主流玩家都能做到。下一阶段的竞争焦点是:谁能把同等能力的模型,用更低的成本、更快的速度、更稳定的服务交付给用户。
这就需要在芯片、网络、数据中心这些基础设施上下功夫。Jalapeño 是 OpenAI 在这个方向上的第一步。
对于使用 OpenAI API 的开发者来说,好消息是 OpenAI Hub 会持续跟进这些变化。无论 OpenAI 底层用什么芯片,API 接口保持稳定。你的代码不用改,性能提升自动享受。
参考来源
- OpenAI 发布首款自研 AI 芯片 Jalapeño,用于 ChatGPT、Codex 和 API 推理 - Linux.do 社区对 OpenAI 官方公告的整理,包含芯片的关键技术参数和部署时间表
- OpenAI 发布首款自研 LLM 推理芯片 Jalapeño?? - Linux.do 社区讨论,包含对 OpenAI「全栈 AI 公司」战略的分析


