通义开源VimRAG:一个框架吃下文本、图片和视频

通义实验室开源多模态RAG框架VimRAG,首次在单一架构内统一文本、图像与视频三种模态的检索增强生成,配套发布Qwen2.5-VL-7B-VRAG模型,直指企业混合知识库的真实痛点。
通义实验室这两天放了个大招——开源了 VimRAG,一个能同时处理文本、图像和视频的统一 RAG 框架,配套的 Qwen2.5-VL-7B-VRAG 模型也一并上了 ModelScope。
这不是又一个「多模态」噱头。它瞄准的是一个行业里喊了很久、但一直没人真正解决好的问题:当你的知识库不只是文档,还有图片和视频的时候,RAG 该怎么做?
先说清楚问题出在哪
RAG 这条路线大家都熟了。把企业知识库切块、向量化、检索、喂给大模型,让 AI 说话有据可查。2024 年到现在,几乎每家做 AI 应用的公司都在搞这套。
但现实世界的知识库长什么样?
拿一家制造企业举例:10 万份 PDF 技术文档里夹着各种图表,5 万张 CAD 设计图和产线照片,再加上上千条每条半小时到一小时的操作培训视频。当有人问「去年 Q3 产品设计改了哪些地方?会议录像里怎么讨论的?」——这个问题横跨三种模态,答案散落在 PDF 的文字段落、CAD 图纸的标注层、以及某条视频第 47 分钟的对话里。
传统 RAG 方案面对这种场景基本是拆东墙补西墙:文本走一套 pipeline,图片走另一套,视频?大多数方案直接选择忽略,或者只做个粗粒度的关键帧提取。三条管线各自为政,模态之间的隐式关联全丢了。
这就是 VimRAG 要解决的事。
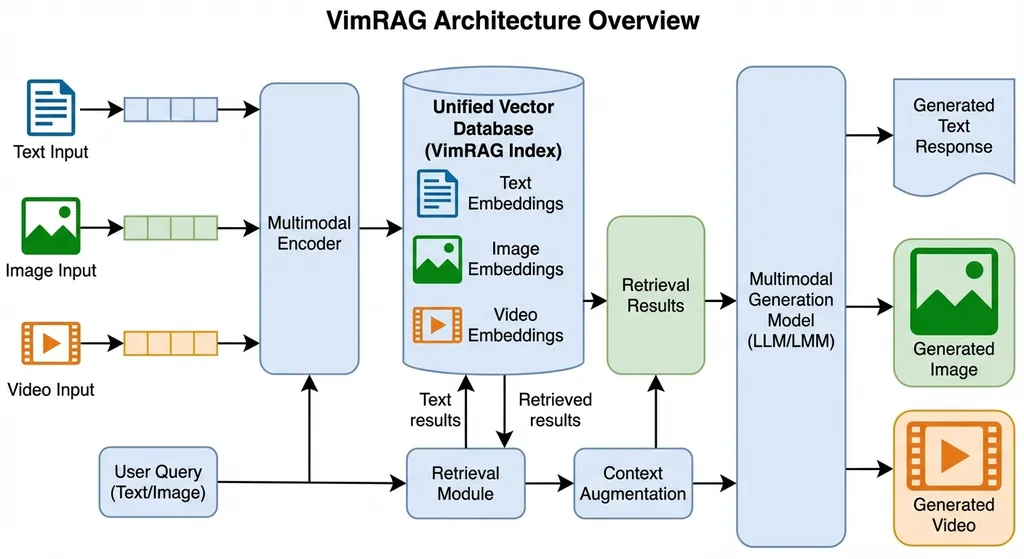
VimRAG 的核心思路
一句话概括:把文本、图像、视频统一到同一个检索-生成框架里,用一个模型、一套流程搞定。
这话说起来轻巧,做起来难度不小。难在哪?三种模态的信息密度和结构差异巨大。一段文本可能几百个 token 就表达清楚了;一张图片的信息量远超等长文本;而一段 60 分钟的视频,信息量更是指数级膨胀,还带有时序结构。把它们塞进同一个检索空间,本身就是个对齐难题。
从目前公开的信息和此前通义实验室在相关方向的工作来看,VimRAG 的技术路线可以拆成几个关键环节:
统一的多模态表征
不同于给每种模态单独建索引再做后期融合的老路子,VimRAG 试图在表征层面就把三种模态拉到同一个语义空间。这背后依赖的是 Qwen2.5-VL 系列模型本身就具备的强视觉-语言对齐能力。7B 参数量的 VRAG 版本,在保持推理效率的同时,对视觉信息的理解粒度做了专门优化。
视频的处理策略
视频是最棘手的模态。一条 30 分钟的培训视频,你不可能把每一帧都编码后扔进检索库——存储和计算成本都扛不住。VimRAG 的做法是对视频做多层次的语义切分:先按场景和语义边界切成片段,再对每个片段提取关键帧和对应的语音/字幕文本,形成「视觉+文本」的复合表征。检索时先定位到相关片段,生成时再回溯到具体的时间点。
这个思路其实和之前通义发布的 ViDoRAG(面向视觉文档的多代理 RAG 框架)一脉相承。ViDoRAG 解决的是图文混排文档的检索问题,用多代理协作和动态迭代推理来处理图表密集的 PDF。VimRAG 可以看作是这条技术路线的自然延伸——从「视觉文档」扩展到「视觉文档 + 视频」。
跨模态关联推理
检索到了相关的文本段落、图片和视频片段之后,还有一个关键问题:怎么让模型理解它们之间的关系?
比如 PDF 里写了「设计方案 B 的应力测试结果见附图 3-7」,附图是一张 CAD 截图,而详细的测试讨论在会议视频的某个时间段。模型需要把这三块信息串起来,才能给出完整的回答。
这正是 VimRAG 框架层面要解决的问题。它不只是做三路检索然后拼接结果,而是在生成阶段让模型同时「看到」多种模态的上下文,利用 Qwen2.5-VL 的长上下文能力做联合推理。
和同类方案比,VimRAG 的位置在哪
多模态 RAG 这个方向最近确实热闹。就在不久前,港大开源了 RAG-Anything,主打统一多模态知识图谱,能处理文字、图表、表格、公式等多种异构信息。
但 RAG-Anything 和 VimRAG 的侧重点不太一样。RAG-Anything 更聚焦于文档内部的多模态元素解析——把一份复杂文档里的各种元素都结构化地提取出来,建成知识图谱。它的强项是文档理解的深度。
VimRAG 的野心更大一些,它要覆盖的是「文档 + 独立图片 + 视频」这种跨载体的混合知识库。这两个框架与其说是竞争,不如说是在多模态 RAG 这条路上解决不同层次的问题。
再看通义自家的技术演进线:
- VRAG-RL:视觉感知多模态 RAG 推理框架,用强化学习优化检索策略
- ViDoRAG:面向视觉文档的多代理 RAG,解决图文混排检索
- VimRAG:统一文本、图像、视频的完整框架
能看出来,通义实验室在多模态 RAG 这个方向上是有系统性布局的,每一步都在扩大模态覆盖范围和场景复杂度。VimRAG 是目前这条线上最完整的一个。
配套模型:Qwen2.5-VL-7B-VRAG
框架开源的同时,通义在 ModelScope 上发布了配套的 Qwen2.5-VL-7B-VRAG 模型。
7B 这个参数量级值得说一下。它意味着这个模型可以在单张消费级显卡(比如 RTX 4090)上跑起来,不需要动用多卡集群。对于想在企业内部私有化部署多模态 RAG 的团队来说,这个门槛是友好的。
不过社区也有一些疑问。有开发者在论坛里提到,官方宣传的场景包括 CAD 设计图识别,但 ModelScope 的模型页面上并没有明确说明对 CAD 格式的支持程度。这一点确实需要通义后续给出更清晰的说明——CAD 图纸的识别和普通照片、截图的识别是完全不同的技术挑战,涉及到工程图纸特有的标注体系、图层结构和尺寸标注等专业元素。
实际接入:怎么用起来
对于开发者来说,VimRAG 基于 Qwen2.5-VL 系列模型,接口上兼容 OpenAI 格式。如果你已经在用 OpenAI 兼容的 API 服务,接入成本很低。
比如通过 OpenAI Hub 调用 Qwen 系列模型做多模态问答,代码大概长这样:
from openai import OpenAI
import base64
client = OpenAI(
api_key="你的 OpenAI Hub API Key",
base_url="https://api.openai-hub.com/v1"
)
# 读取本地图片并编码
with open("design_diagram.png", "rb") as f:
image_data = base64.b64encode(f.read()).decode("utf-8")
response = client.chat.completions.create(
model="qwen-vl-max",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "这张设计图和上次评审版本相比,主要改动了哪些部分?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_data}"
}
}
]
}
]
)
print(response.choices[0].message.content)
当然,VimRAG 作为一个完整的 RAG 框架,真正的价值不在于单次 API 调用,而在于它提供的整套检索-生成 pipeline。你需要把自己的混合知识库接入框架,完成索引构建、检索配置和生成策略的调优。这部分工作量不小,但至少现在有了一个开源的起点。
冷静看几个问题
开源是好事,但也别急着上生产。几个需要关注的点:
第一,视频处理的效果和效率。视频语义切分的质量直接决定了检索的准确率。切得太粗,关键信息被淹没;切得太细,噪声太多。这个平衡点在不同场景下差异很大,需要大量实际数据来验证。
第二,7B 模型的能力上限。多模态理解本身就是个对模型能力要求很高的任务,再叠加 RAG 场景下的长上下文推理,7B 参数量能撑到什么程度,还需要社区更多的测试反馈。好消息是 Qwen2.5-VL 系列还有更大参数量的版本可以替换。
第三,工程落地的复杂度。混合知识库的数据预处理本身就是个大工程——视频转码、音频提取、OCR、图片分类……这些脏活累活框架帮不了你太多,还是得自己搞。
第四,CAD 等专业格式的支持。社区已经在问了,官方还没给明确答复。如果你的场景强依赖工程图纸识别,建议先等等实测结果。
写在最后
多模态 RAG 是 2025 年以来 AI 应用层最重要的演进方向之一。从纯文本 RAG 到图文 RAG,再到现在加入视频,知识库的边界在不断扩大。VimRAG 的开源,给了开发者一个真正意义上覆盖三种主流模态的统一框架。
它不完美,还有很多工程细节需要打磨,但方向是对的。当企业的知识资产越来越多地以视频、图片等非文本形式存在时,能统一处理这些模态的 RAG 方案就不再是锦上添花,而是刚需。
通义实验室在这个方向上的持续投入——从 VRAG-RL 到 ViDoRAG 再到 VimRAG——展现出了清晰的技术路线图。接下来就看社区能把它用到什么程度了。
参考来源:
- 通义实验室正式开源 VimRAG 讨论帖 - Linux.do 社区关于 VimRAG 开源的技术讨论
- 通义实验室发布多代理 RAG 框架 ViDoRAG - 知乎专栏,介绍 VimRAG 前身 ViDoRAG 的技术细节
