NeMo AutoModel 发布:微调大模型终于不用转检查点了

Hugging Face 与 NVIDIA 联合推出 NeMo AutoModel,让任意 Hugging Face 模型可以直接在 NeMo 框架中微调,省去繁琐的检查点转换流程,支持从单卡到多节点的分布式训练。
NeMo AutoModel 发布:微调大模型终于不用转检查点了
做过大模型微调的人都知道一个痛点:你在 Hugging Face 上看中了一个模型,想用 NVIDIA 的 NeMo 框架来训练,结果光是检查点转换就能折腾你半天。格式对不上、权重映射出错、验证流程繁琐——这些问题让「快速实验」变成了一句空话。
现在这个问题有了官方解法。Hugging Face 与 NVIDIA 联合发布了 NeMo AutoModel,一个让 Hugging Face 模型可以直接在 NeMo 框架中运行的高级接口。不需要转换检查点,不需要重写模型定义,加载即用。
解决了什么问题
先说清楚 NeMo 框架原本的工作方式。
NVIDIA NeMo 是一套面向大规模训练的框架,底层用的是 Megatron-Core 和 Transformer-Engine。它的优势很明显:在多卡、多节点场景下能跑出很高的吞吐量和 MFU(Model Flops Utilization)。但代价是,你不能直接拿 Hugging Face 的模型来用。
原本的流程是这样的:
- 从 Hugging Face 下载模型权重
- 用 NeMo 提供的转换脚本把权重格式转成 Megatron-Core 格式
- 验证转换后的模型在推理、微调、评估各个阶段都能正常工作
- 如果出问题,回头排查是转换脚本的 bug 还是模型架构不兼容
这个流程对于 Llama、Mistral 这些主流模型还好,NeMo 团队已经写好了转换脚本。但如果你想用一个刚发布的新模型——比如某个社区微调版本,或者某个小众架构——就得自己写转换逻辑,甚至可能要等 NeMo 官方支持。
这就造成了一个时间差:模型在 Hugging Face 上发布了,但你要等几周甚至几个月才能在 NeMo 里高效训练它。
AutoModel 的思路很简单:既然 Hugging Face 的模型定义已经很完善了,为什么不直接用它?
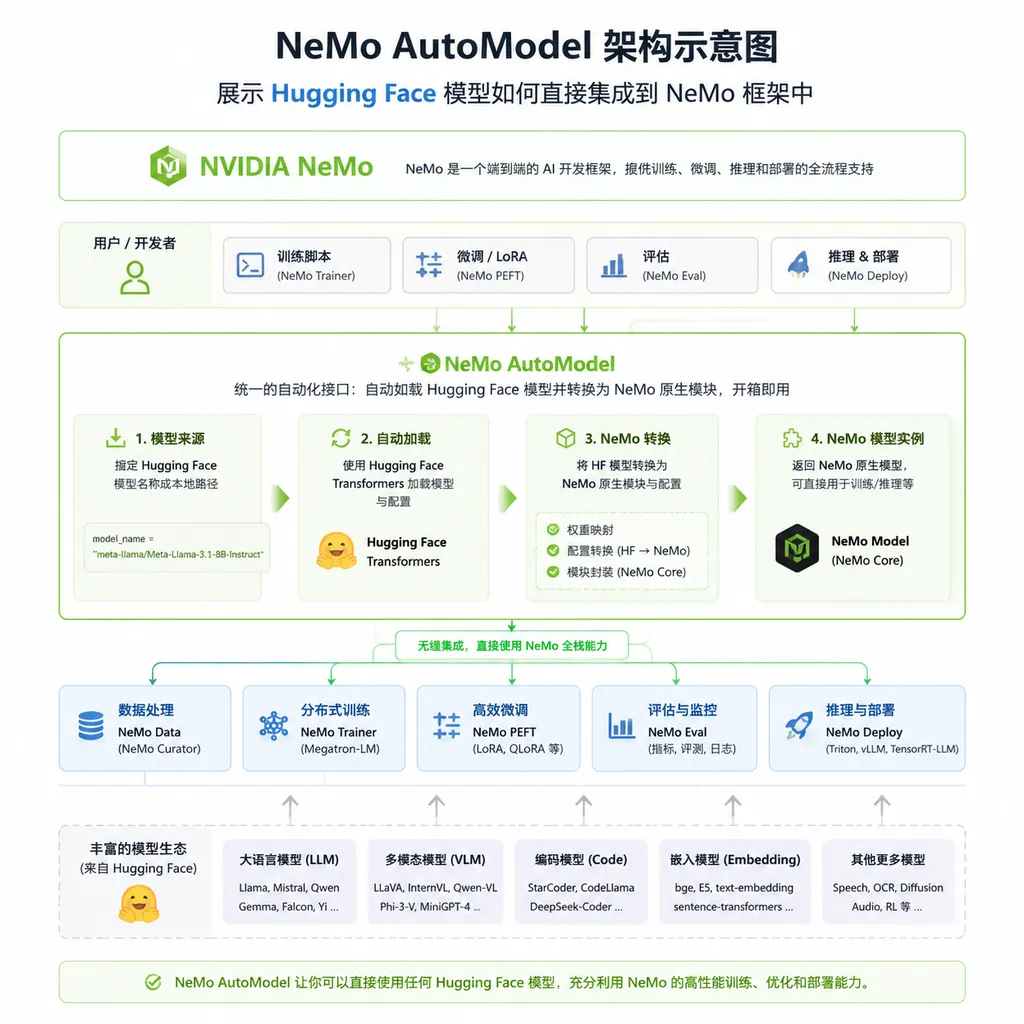
AutoModel 怎么用
代码层面的变化非常小。
以前用 Megatron-Core 后端加载 Llama 模型是这样写的:
import nemo.collections.llm as llm
# Megatron-Core 方式:需要指定具体的模型类和配置
model = llm.LlamaModel(llm.Llama32Config1B())
strategy = nl.MegatronStrategy(ddp="pytorch", ...)
现在用 AutoModel 只需要:
import nemo.collections.llm as llm
# AutoModel 方式:直接用 Hugging Face 的 model_id
model = llm.HFAutoModelForCausalLM(model_id="meta-llama/Llama-3.2-1B")
就这么一行。模型会直接从 Hugging Face Hub 拉取,不需要任何转换步骤。
更完整的微调脚本示例:
# 使用 NeMo AutoModel 微调 Qwen2.5-7B
python3 examples/llm_finetune/finetune.py \
-c examples/llm_finetune/qwen/qwen2_5_7b_squad_peft.yaml \
--model.pretrained_model_name_or_path Qwen/Qwen2.5-7B \
--step_scheduler.max_steps 20
配置文件里指定数据集、学习率、batch size 这些常规参数,模型部分只需要一个 pretrained_model_name_or_path 就够了。
对于更大的模型,比如 Qwen2.5-32B,可以用 QLoRA 来降低显存占用:
python3 examples/llm_finetune/finetune.py \
-c examples/llm_finetune/qwen/qwen1_5_moe_a2_7b_qlora.yaml \
--model.pretrained_model_name_or_path Qwen/Qwen2.5-32B \
--loss_fn._target_ nemo_automodel.components.loss.te_parallel_ce.TEParallelCrossEntropy \
--step_scheduler.local_batch_size 1 \
--step_scheduler.max_steps 20
注意这里用了 TEParallelCrossEntropy,这是 Transformer-Engine 提供的并行交叉熵实现,在多卡场景下效率更高。
两个后端,各有所长
现在 NeMo 框架实际上有两条路径可选:
Megatron-Core 后端:
- 经过深度优化,支持张量并行、流水线并行、专家并行等多种并行策略
- MFU 更高,适合大规模生产训练
- 但只支持官方已经适配的模型列表
AutoModel 后端:
- 支持任意 Hugging Face 模型,无需转换
- 同样支持 FSDP2、张量并行、流水线并行
- 可以使用 FP8 精度优化
- 适合快速实验和新模型验证
两者不是互斥的。官方推荐的工作流是:
- 用 AutoModel 快速验证某个模型在你的任务上是否 work
- 如果效果不错,切换到 Megatron-Core 后端做正式训练
- 切换只需要改几行代码
这就像是给你提供了两档变速:AutoModel 是快速迭代档,Megatron-Core 是全速生产档。
支持哪些模型
理论上,AutoModel 支持所有 Hugging Face Transformers 库能加载的模型。目前官方测试过的包括:
大语言模型(LLM):
- Meta Llama 系列(Llama 2、Llama 3、Llama 3.2)
- Google Gemma 系列
- Mistral、Mixtral(包括 MoE 架构)
- Qwen 系列(Qwen 2、Qwen 2.5、Qwen 3)
- DeepSeek R1
- NVIDIA Nemotron 和 Llama Nemotron
- Codestral、Codestral Mamba
视觉语言模型(VLM):
- AutoModel 也覆盖了 VLM 类别,可以用同样的接口加载和微调多模态模型
官方文档提到,后续还会扩展到视频生成等更多模型类别。
从实际使用角度看,热门模型基本都能直接跑。如果你用的是某个社区微调版本(比如某个 Llama 的中文版),只要它在 Hugging Face 上能正常加载,AutoModel 就能用。
分布式训练支持
单卡微调只是基本功。AutoModel 真正的价值在于它继承了 NeMo 框架的分布式训练能力。
支持的并行策略包括:
- FSDP2(Fully Sharded Data Parallel):PyTorch 原生的分布式数据并行,把模型参数、梯度、优化器状态分片到多个 GPU 上
- 张量并行(Tensor Parallelism):把单个算子的计算分布到多卡上,适合单个模型太大放不进一张卡的情况
- 流水线并行(Pipeline Parallelism):把模型的不同层放到不同设备上,形成流水线
- 专家并行(Expert Parallelism):专门为 MoE(Mixture of Experts)架构设计
- 上下文并行(Context Parallelism):处理超长序列时使用
这些并行策略可以组合使用。比如在 8 卡 A100 上训练一个 70B 模型,可能需要同时用张量并行和 FSDP2。
另外,AutoModel 集成了 TransformerEngine 的算子和 DeepEP 的通信优化,支持 FP8 精度训练。在 Blackwell 架构的 GPU 上,FP8 可以带来显著的吞吐量提升。
与其他微调方案的对比
市面上做大模型微调的工具不少,AutoModel 的定位是什么?
对比 Hugging Face Trainer:
Trainer 是 Hugging Face 官方的训练工具,上手简单,社区资源丰富。但它在多卡场景下的效率不如 NeMo,尤其是需要用到张量并行、流水线并行的时候。AutoModel 可以看作是「Trainer 的易用性 + NeMo 的训练效率」的结合。
对比 DeepSpeed:
DeepSpeed 也是多卡训练的主流选择,ZeRO 系列优化在大模型训练中应用很广。NeMo AutoModel 的优势在于对 NVIDIA 硬件的深度优化,特别是 Transformer-Engine 和 FP8 支持。如果你用的是 A100/H100/Blackwell,NeMo 通常能跑出更高的 MFU。
对比 LLaMA-Factory:
LLaMA-Factory 专注于 LLM 微调,提供了 WebUI 和丰富的预设配置,上手门槛很低。AutoModel 更偏底层一些,灵活性更高,但需要更多配置工作。如果你只是想快速微调一个聊天模型,LLaMA-Factory 可能更合适;如果你需要定制训练流程或者做大规模分布式训练,AutoModel 是更好的选择。
对比 Axolotl:
Axolotl 也是一个流行的微调框架,以配置驱动著称。AutoModel 的差异点在于它是 NeMo 生态的一部分,可以无缝切换到 Megatron-Core 后端做生产级训练,而且有 NVIDIA 官方的持续投入。
总的来说,AutoModel 的目标用户是那些需要在 NVIDIA GPU 上做高效微调、同时又希望保持与 Hugging Face 生态兼容的团队。
实际使用体验
我们在一台 DGX Spark(搭载 Blackwell 架构 GPU)上跑了一下官方示例。
环境搭建很简单,官方提供了现成的 Docker 镜像:
# 拉取官方镜像
docker pull nvcr.io/nvidia/nemo-automodel:26.02
# 启动容器
docker run --gpus all -it nvcr.io/nvidia/nemo-automodel:26.02
镜像里已经装好了所有依赖,包括 PyTorch、Transformers、NeMo 框架和 Transformer-Engine。
跑一个 Qwen3-8B 的微调:
python3 examples/llm_finetune/finetune.py \
-c examples/llm_finetune/qwen/qwen3_8b_squad_spark.yaml \
--model.pretrained_model_name_or_path Qwen/Qwen3-8B \
--step_scheduler.local_batch_size 1 \
--step_scheduler.max_steps 20 \
--packed_sequence.packed_sequence_size 1024
这里用了 packed sequence 优化,把多个短样本打包成一个长序列,减少 padding 的浪费。
整个流程确实比以前顺畅很多。以前用 NeMo 微调一个新模型,光是调通检查点转换可能就要花半天;现在基本上是改一下 model_id 就能跑。
当然也有一些需要注意的地方:
-
显存占用:AutoModel 后端的显存占用比 Megatron-Core 后端稍高一些,因为没有做那么深度的优化。如果显存吃紧,建议用 LoRA/QLoRA。
-
速度差异:对于 Llama、Qwen 这些主流模型,Megatron-Core 后端的训练速度还是更快。AutoModel 的优势在于通用性,不在于极致性能。
-
模型兼容性:虽然官方说支持「任意 Hugging Face 模型」,但实际上一些特殊架构(比如非标准的 attention 实现)可能会有问题。遇到问题可以去 NeMo 的 GitHub 提 issue。
微调完之后怎么办
训练出来的 checkpoint 可以直接推送到 Hugging Face Hub:
# 在容器内执行
huggingface-cli login
huggingface-cli upload your-username/your-model-name ./output_checkpoint
因为 AutoModel 用的就是 Hugging Face 的模型格式,所以 checkpoint 是完全兼容的,可以直接用 Transformers 库加载推理:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("your-username/your-model-name")
tokenizer = AutoTokenizer.from_pretrained("your-username/your-model-name")
也可以部署到 vLLM、TGI 这些推理框架上,不需要任何额外转换。
这一点比原来的 Megatron-Core 流程好很多。以前用 NeMo 训练出来的模型,还得转换回 Hugging Face 格式才能部署,现在省掉了这一步。
对开发者意味着什么
AutoModel 的发布反映了一个趋势:大模型工具链正在走向「开箱即用」。
两年前,用 NeMo 做微调还是一件有门槛的事情,你需要理解 Megatron-Core 的架构、熟悉检查点转换的各种坑、处理多卡训练的通信问题。现在这些复杂度被封装起来了,你只需要关心「我要训什么模型」和「我要用什么数据」。
对于中小团队来说,这是个好消息。以前想用 NVIDIA 的高效训练框架,要么花大量时间学习,要么招专门的 MLOps 工程师。现在门槛降低了,一个熟悉 Hugging Face 生态的算法工程师就能上手。
对于大厂来说,AutoModel 提供了一条从实验到生产的平滑路径。研究团队可以用 AutoModel 快速验证想法,确认有价值之后再交给工程团队用 Megatron-Core 做优化。两个后端共用一套代码结构,交接成本很低。
当然,工具再好用也只是工具。模型效果好不好,最终还是取决于数据质量和训练配方。AutoModel 解决的是「怎么高效地跑起来」的问题,不解决「跑什么才能出效果」的问题。
未来规划
根据官方博客透露的信息,AutoModel 后续会扩展到更多模型类别,包括视频生成模型。这意味着 Sora 类模型发布后,可能很快就能在 NeMo 里微调。
另外,NeMo 团队承诺会对热门模型保持「Day 0 支持」——也就是说,新模型在 Hugging Face 上发布的当天,就能在 NeMo AutoModel 里使用。这对于追新模型的研究者来说是个重要承诺。
从 NVIDIA 的角度看,AutoModel 也是推广自家 GPU 的一个手段。Transformer-Engine、FP8 这些优化只有在 NVIDIA 硬件上才能发挥作用。把使用门槛降下来,更多人会选择在 NVIDIA GPU 上做训练,这对 NVIDIA 来说是双赢。
总结:NeMo AutoModel 做的事情不复杂——让 Hugging Face 模型能直接在 NeMo 框架里跑。但这件「不复杂」的事情,解决了很多人实际遇到的痛点。如果你在用 NVIDIA GPU 做大模型微调,同时又想保持与 Hugging Face 生态的兼容,AutoModel 值得一试。
参考来源
- 在 NVIDIA NeMo 框架的首发日支持下即时运行 Hugging Face 模型 - 知乎:NVIDIA 官方技术博客的中文翻译,详细介绍了 AutoModel 的设计理念和使用方法
- Accelerating Transformers Fine-Tuning with NVIDIA NeMo AutoModel - Hugging Face Blog:Hugging Face 与 NVIDIA 联合发布的官方博客,包含性能基准测试数据
- NeMo AutoModel 集成文档 - Hugging Face Docs:Hugging Face 官方文档中关于 NeMo AutoModel 的集成指南


