RoboScience发布Visics大模型:VLOA架构首次公开

前苹果AI负责人田野创立的RoboScience昨日发布通用具身大模型Visics,首次完整披露VLOA架构。用物体轨迹取代关节坐标,让一个模型能跨机器人本体、跨物体类型完成操作任务。
RoboScience发布Visics大模型:VLOA架构首次公开
前苹果AI平台技术负责人田野创立的RoboScience机器科学昨天(6月24日)发布了通用具身大模型Visics,首次完整披露其技术架构VLOA(Vision-Language-Object-Action)。这套架构解决的是具身智能领域最基础的问题:让机器人学会的技能能在不同场景、不同硬件上复用。
发布会现场展示了家具拼装、灵巧抓取、动态流水线等多个实际应用案例。但更值得关注的是架构本身——RoboScience提出用**Object Trajectory(物体3D点云轨迹)**作为统一的中间表征,而不是像现有方案那样直接学习机器人的关节运动数据。
为什么现有方案不够用
大语言模型有Token,自动驾驶有点云,这些标准化的数据格式让模型能在不同场景间迁移。但具身智能一直缺这么个东西。
过去两年行业主流做法是让模型直接学习机器人的关节轨迹——比如让夹爪从A点移动到B点时,记录每个关节的角度变化。这套逻辑的问题很明显:换台机器人、换个物体、换个场景,之前学的都用不上。模型学会的是"这台夹爪怎么抓杯子",而不是理解"抓取"这个动作本质是什么——需要多大的力、物体受力后会怎么反应、接触点选在哪里。
田野在发布会上总结了三大瓶颈:泛化能力差、精细操作难、长程任务误差累积。要解决这些问题,得从数据表征这个底层重新设计。
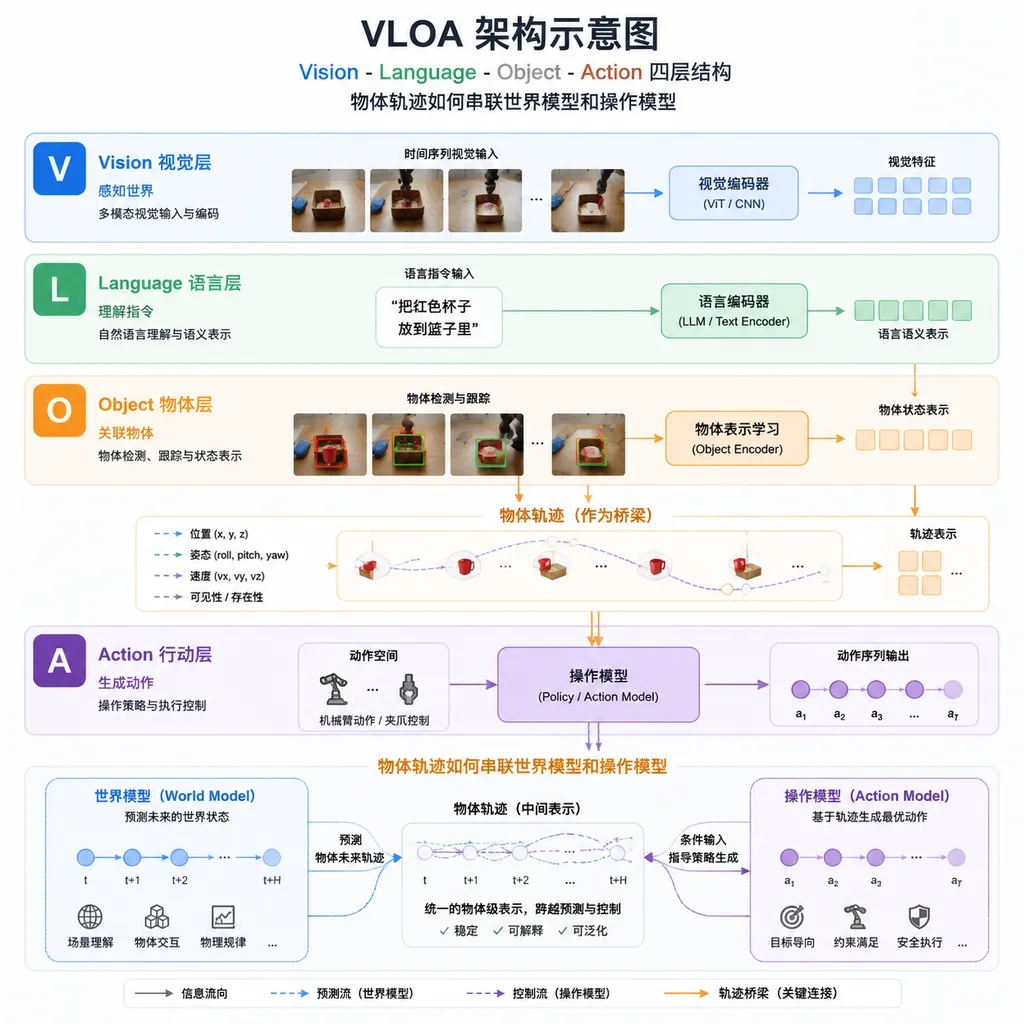
VLOA的核心逻辑:围绕物体建模
VLOA架构的关键是Object Trajectory这个中间表征。它用一串带时间戳的3D点云描述物体未来的位置、姿态和形变,以及周围环境的变化。
田野解释说,"Object这个词同时包含物体、目标两层含义,能够精准定义机器人与物件的交互关系,以及操作后物体需要达成的运动变化状态。"这不是玩文字游戏——围绕物体而不是机器人本身建模,意味着学到的是物理规律本身,而不是某个特定硬件的运动模式。
VLOA内部是双引擎架构,世界模型和操作模型各自独立:
具身世界模型
负责"预演"物体会怎么动。用海量互联网视频做预训练——RoboScience已经积累了超过100万小时的视频数据(上千万clips),并且以每周数十万小时的速度增长,目标是2026年构建千万小时级数据集。
模型学习的是物体状态、三维轨迹、接触力和物理因果关系。给定当前场景和任务描述,它能输出物体未来的运动轨迹——比如抓取一个杯子时,杯子会如何被夹起、倾斜、移动。
通用操作模型
负责把"物体运动轨迹"转化为"机器人该怎么做"。接收世界模型输出的3D点云轨迹,生成具体的接触点、力控参数和关节指令。
这个模型通过物理引擎生成的仿真数据训练——RoboScience自研了多模态物理引擎,已经积累了10B(100亿次)操作数据,2026年目标是1T(1万亿次)。能操作刚体、铰链体、1D/2D/3D可形变体等各类物体,支持跨本体部署,兼容视觉、触觉、力觉等多模态输入。
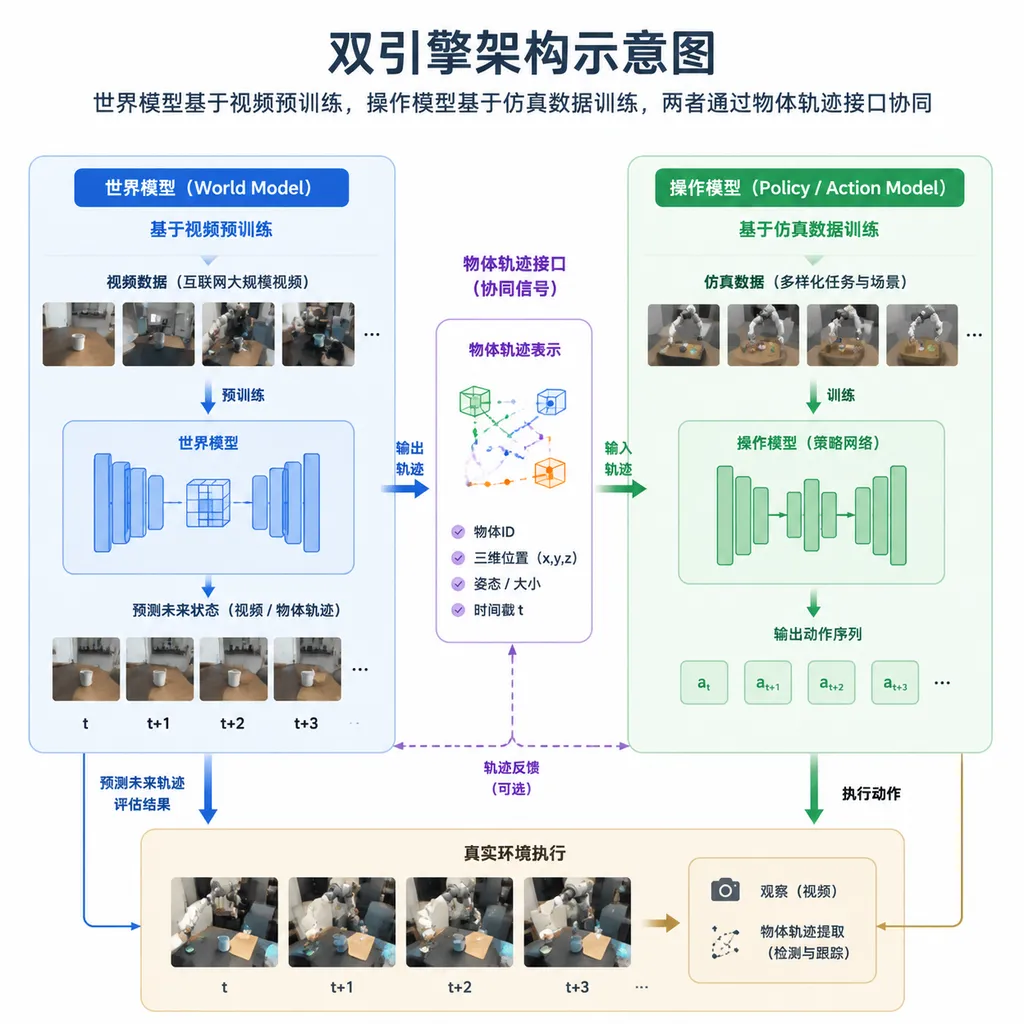
关键是这两个模型分开预训练、分别迭代。世界模型专注理解物理规律,操作模型专注执行动作,互不干扰。中间用Object Trajectory这个标准接口连接,类似于大模型里的Token。
实际效果如何
发布会展示的案例覆盖了几个关键能力:
跨物体泛化:桌面上的异形小鹿玩具、番茄酱瓶、收纳箱里拥挤堆放的零食盒——模型能识别不同物体的几何特征和物理属性,自动选择合适的接触点和夹持力。抓小鹿玩具时选躯干而不是角部,避免损坏;抓番茄酱瓶时夹持中段保持重心平衡。
跨本体部署:同一套策略无缝迁移到不同构型的灵巧手——2指、3指、5指都能直接用,不需要重新训练。X-hand和LEAP Hand在机械设计上完全不同(一个齿轮传动12自由度,一个肌腱驱动16-20自由度),但模型都能稳定操作。
精细力控:开信封需要毫牛级切入力度,立硬币需要动态平衡控制,抓薯片不能压碎,用针管注射液体要精确控制推注速度——这些对力控精度要求极高的任务都能完成。演示中还包括抓海苔、蛋壳、雪糕筒这类易碎物品,以及双臂协同完成家具拼装。
长程任务执行:传送带上的动态抓取,模型实时检测运动物体的速度和姿态,闭环调整抓取点。家具拼装过程中,即便中途被拆解也能自动恢复并接续完成——这依赖持续的视觉反馈和实时决策调整。
推理速度达到3fps以上,能基于物体和环境的点云输入实现闭环控制。与传统方法需要大量成对动作数据不同,Visics是轨迹条件化的——它不需要重新学"该去哪里",只需要掌握"如何到达那里"。
技术路线的差异化
业内现有的操作模型多是"原子技能库"——把任务拆成抓取、放置等独立技能,每个技能对应一个专用模型。这种碎片化方案扩展性差,遇到新任务就得重新训练。
Visics的通用操作模型是一个超10亿参数的大模型,在所有技能上联合训练,形成统一的操作表征。无需为新物体或新动作单独训练子模型,凭共享的物理常识和轨迹先验就能泛化。
实验数据显示,随着模型尺寸增加,成功率和抓取多样性(生成成功抓取关节角的方差)都呈现可预测的幂律提升。这是Scaling Law在具身智能领域的体现——有了标准化的数据格式和足够的数据规模,模型能力可以持续进化。
数据来源方面,世界模型用的是互联网视频,操作模型用的是物理仿真生成的数据。这套"视频+仿真"组合比纯遥操采集效率高得多。RoboScience自研的多模态物理引擎能生成包含力觉、触觉、形变的高质量数据,支持刚体、铰链体、可形变体等全空间物体的操作任务。
团队背景与落地计划
创始人田野本科毕业于中科大物理学院,硕士毕业于斯坦福AI Lab师从吴恩达,曾任苹果AI Platform技术负责人。他在苹果主导开发了多项里程碑技术:被称为"苹果的PyTorch与CUDA"的核心基础设施平台、全球首个端云协同大模型推理系统Apple Intelligence、首个端侧推理系统和多计算单元协同计算系统。服务超10亿用户、20亿设备,在大规模端侧AI部署上经验丰富。
首席科学家邵林是新加坡国立大学计算机系助理教授,博士毕业于斯坦福AI Lab。他提出的UniGrasp深度神经网络架构已成为数据驱动灵巧手抓取的基准方法,跨实体灵巧抓取方法D(R,O)获得ICRA 2025机器人操作与运动最佳论文奖(近五年来亚洲机构首次以第一单位身份获得该奖项)。最新研究Bi-Adapt入围ICRA 2026最佳论文奖提名。
联合创始人刘朋海曾任科沃斯集团副总裁,有20余年新产品开发与供应链管理经验,从0到1搭建了科沃斯的产品开发流程,实现50余款机器人产品量产。联合创始人汪涛曾任商汤国香资本募资负责人,主导了数十亿规模产业基金的募资与落地。
RoboScience成立于2024年12月,目前已完成多轮融资,投资方包括京东集团、商汤科技、达晨财智、招商局创投、零一创投、普华资本等。最新一轮是今年2月完成的数亿元Pre-A轮,由普华资本领投。公司在北京、深圳、苏州、杭州设有研发和生产中心。
落地方面,RoboScience已经与多家零售、物流、康养服务企业以及机器人本体、灵巧手公司开展试点合作,计划今年实现面向工业与商业场景的标准化机器人本体产品量产。
行业意义
具身智能这两年最大的问题是没有标准化的数据格式。每家公司、每个研究团队都在用自己的方式采集数据、训练模型,导致成果难以复用,规模化困难。
RoboScience提出的Object Trajectory作为统一中间表征,如果能被行业接受,意义不亚于Transformer对NLP的影响。它定义了一个清晰的接口:世界模型输出物体轨迹,操作模型消费物体轨迹。两边可以独立进化,互不干扰。
更实际的影响是降低了技能迁移的成本。过去一个抓取模型只能用在特定硬件上,现在理论上可以跨本体部署。机器人公司不需要为每款产品重新训练操作模型,专注做好硬件设计就行。
当然,实际落地还有很多工程问题要解决——力控精度、实时性、安全性、成本控制。但至少在架构层面,VLOA提供了一个可扩展的框架。随着数据规模增长和模型迭代,能力会持续提升。这比碎片化的技能库路线更有想象空间。
参考来源
- 36氪:RoboScience机器科学发布Visics通用具身大模型,实现跨本体、跨物体、跨任务 - 官方发布会报道,包含技术细节和应用案例
- RoboScience官网:VLOA大模型系列解读 - 通用操作模型的技术深度解读
- 智东西:苹果前技术负责人带队,打造具身大模型 - 团队背景和融资信息


