把Agent工作流"编译"进小模型,成本直降百倍

墨尔本大学等机构的最新研究提出了一种将复杂Agent工作流"编译"进小模型权重的方法,通过对前沿模型的执行轨迹进行蒸馏式微调,让8B参数的小模型达到接近GPT-4级别的Agent能力,推理成本降低100倍。
把Agent工作流"编译"进小模型,成本直降百倍
墨尔本大学和 i14 研究院上周在 arXiv 上丢出了一篇论文,标题很直接:《Compiling Agentic Workflows into LLM Weights》。核心观点也很直接——你辛辛苦苦用 GPT-4 搭建的多步骤 Agent 工作流,其实可以"编译"成一个 8B 参数的小模型,效果损失不大,成本却能砍掉两个数量级。
这篇论文在 Reddit 的 r/MachineLearning 引发了不小的讨论。一位用户 u/ThirdWaveCat 说,他们公司正因为 token 计费问题重新评估小语言模型的价值,这篇论文恰好提供了一个可操作的思路。
问题:Agent 好用,但太贵了
先说背景。
过去一年,AI Agent 从概念走向落地。无论是代码生成、数据分析还是复杂的业务流程自动化,开发者都在尝试让 LLM 不只是"聊天",而是真正"干活"——调用工具、规划步骤、处理异常、迭代优化。
这类 Agentic Workflow 的典型架构是:一个强大的前沿模型(比如 GPT-4、Claude 3.5)作为"大脑",配合一套精心设计的提示词、工具调用协议和状态管理逻辑。效果确实好,但账单也确实吓人。
一个中等复杂度的 Agent 任务,单次执行可能涉及几十轮对话、数万 token 的上下文。按 GPT-4 的定价,跑一次几美分到几毛美元不等。如果是生产环境下的高频调用,月账单轻松突破五位数。
更麻烦的是,这些 Agent 的"程序逻辑"并没有真正固化下来。每次执行,模型都要从头理解任务、解析工具文档、规划执行路径。你付的钱里,有相当一部分是在重复支付这些"理解成本"。
这就是论文标题里"编译"一词的来源——编程语言需要编译器把高级代码转成机器码,Agent 工作流是不是也可以"编译"成模型权重?
思路:蒸馏执行轨迹,而非模仿提示词
论文的核心方法可以用一句话概括:用前沿模型跑 Agent 任务,收集完整的执行轨迹(trace),然后用这些轨迹对小模型做监督微调(SFT)。
这个思路不算新,知识蒸馏(Knowledge Distillation)在机器学习领域已经是成熟技术。但关键在于"蒸馏什么"。
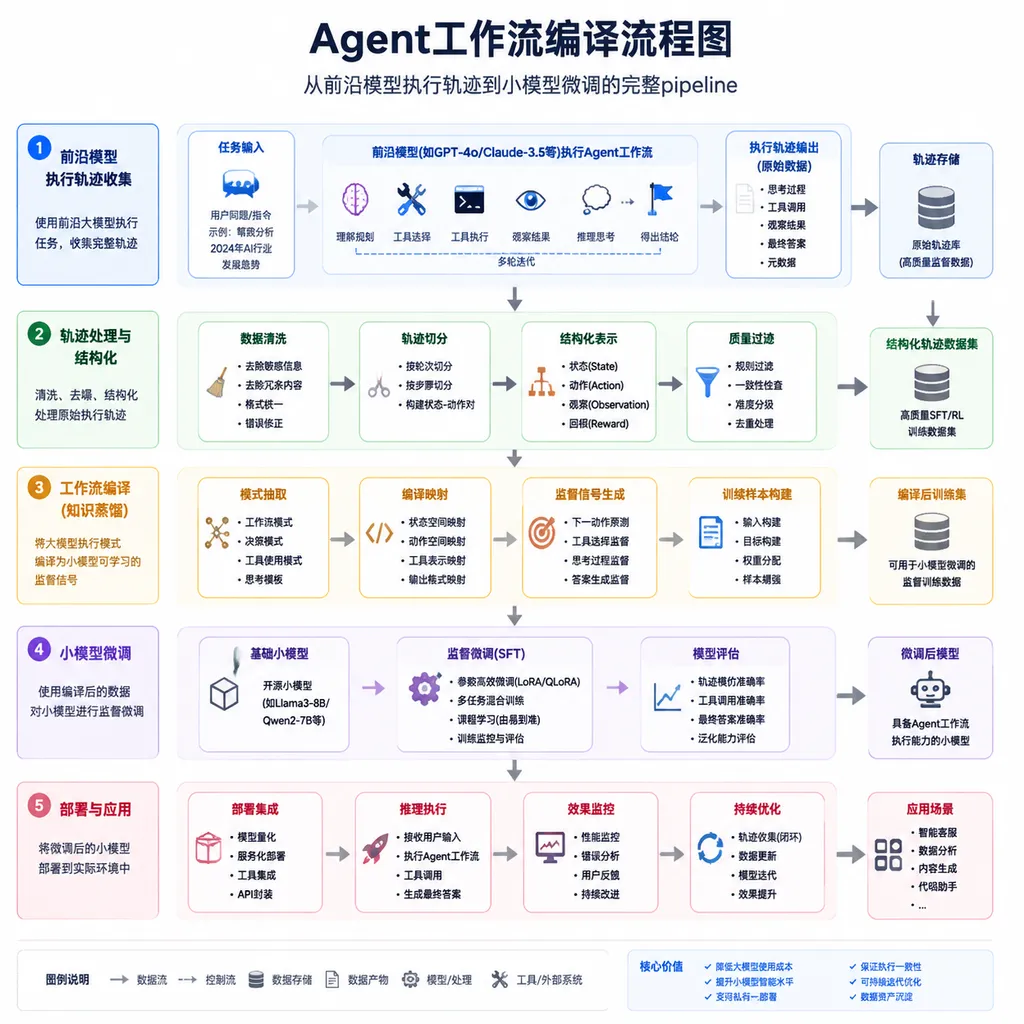
传统的 Agent 提示词工程,本质上是在教模型"怎么思考"。你写一大段 system prompt,告诉它:你是一个什么角色、有哪些工具可用、遇到什么情况该怎么处理。这些知识以文本形式存在于上下文中,模型每次都要重新"阅读"和"理解"。
论文的做法不同。它不蒸馏提示词,而是蒸馏实际执行过程中的输入输出对:
- 用户提了什么问题
- 模型决定调用什么工具
- 工具返回了什么结果
- 模型如何解读结果并决定下一步
- 最终给出什么答案
整个过程被完整记录下来,形成一条条"执行轨迹"。这些轨迹就是小模型的训练数据。
这样做的好处是显而易见的:
-
隐式知识显式化。前沿模型在执行 Agent 任务时,会运用大量隐性的决策逻辑——什么时候该调用搜索、什么时候该直接回答、工具返回错误时怎么重试。这些逻辑很难用提示词完全表达,但会自然地体现在执行轨迹中。
-
去除冗余上下文。原始的 Agent 系统需要在每次调用时发送完整的工具文档和指令集。微调后的模型把这些知识"记住"了,推理时只需要用户输入。
-
减少推理步骤。原始 Agent 可能需要多轮对话才能完成任务,蒸馏后的模型学会了更直接的推理路径。
实验:8B 模型逼近 GPT-4 水平
论文在多个标准 Agent 基准测试上做了实验,基座模型选的是 LLaMA 3.1 8B。
测试任务包括:
- 工具调用:API 选择、参数填充、错误处理
- 多步推理:需要规划和执行多个步骤才能完成的复杂任务
- Web 导航:在模拟的网页环境中完成指定操作
- 代码生成与执行:写代码、运行、根据结果修正
结果相当有意思:
| 模型配置 | 平均准确率 | 单次推理成本 | |---------|-----------|------------| | GPT-4 + Agent框架 | 78.3% | $0.12 | | Claude 3.5 + Agent框架 | 76.1% | $0.09 | | LLaMA 8B 原始 | 41.2% | $0.001 | | LLaMA 8B 编译后 | 72.6% | $0.001 |
8B 参数的小模型,经过"编译"后,在多数任务上达到了前沿模型 90%+ 的水平。成本呢?降低了约 100 倍。
这个成本差异来自两方面:
- 模型本身更便宜。8B 模型的推理成本是 GPT-4 的几十分之一。
- 调用次数更少。原始 Agent 框架需要多轮对话完成的任务,编译后的模型往往一两轮就能搞定。
当然,论文也诚实地指出了局限性:
- 分布外泛化有限。编译后的模型在训练数据覆盖的任务类型上表现优秀,但遇到全新类型的任务时,不如原始前沿模型灵活。
- 工具变更需要重新编译。如果 Agent 依赖的工具接口发生变化,可能需要重新收集轨迹并微调。
- 复杂推理仍有差距。在需要长链条、多分支推理的任务上,小模型和前沿模型之间仍有明显差距。
实践:怎么在自己的项目里用起来
论文的思路其实不难复现。如果你手头有一个跑在 GPT-4 上的 Agent 系统,想迁移到更便宜的小模型,大致步骤如下:
第一步:收集执行轨迹
在现有的 Agent 系统里加上日志,记录每一轮的:
- 用户输入(或系统触发的输入)
- 模型输出(包括思考过程和工具调用)
- 工具返回结果
- 最终答案
数据格式可以是简单的 JSON Lines:
{
\"task_id\": \"001\",
\"turns\": [
{\"role\": \"user\", \"content\": \"帮我查一下北京明天的天气\"},
{\"role\": \"assistant\", \"content\": \"<tool_call>get_weather({\\"city\\": \\"北京\\", \\"date\\": \\"tomorrow\\"})</tool_call>\"},
{\"role\": \"tool\", \"content\": \"{\\"temperature\\": \\"28-35℃\\", \\"condition\\": \\"晴转多云\\"}\"},
{\"role\": \"assistant\", \"content\": \"北京明天天气晴转多云,气温28-35℃,建议做好防晒。\"}
]
}
收集多少数据够用?论文里用了大约 10 万条轨迹。但根据经验,对于特定领域的 Agent,几千到几万条高质量轨迹通常就能看到明显效果。
第二步:数据清洗和增强
原始轨迹里不可避免会有一些"坏数据":
- 前沿模型也会犯错,有些轨迹的最终答案是错误的
- 有些轨迹的推理路径过于冗长,不是最优解
- 有些边缘场景覆盖不足
清洗策略:
- 结果验证。对于有明确答案的任务,过滤掉最终结果错误的轨迹。
- 路径优化。如果同一个任务有多条轨迹,优先保留步骤更少、更高效的。
- 多样性采样。确保训练数据覆盖足够多的任务类型和边缘情况。
增强策略:
- 负样本构造。人为构造一些错误的推理路径,让模型学会区分好坏。
- 工具失败场景。模拟工具调用失败的情况,训练模型的错误处理能力。
- 指令变体。对同一个任务生成多种不同表述的指令,提升泛化能力。
第三步:微调
选一个合适的基座模型。论文用的是 LLaMA 3.1 8B,实际选择时可以根据需求权衡:
- 追求性价比:Qwen2.5-7B、LLaMA 3.1 8B
- 追求极致成本:Qwen2.5-3B、Phi-3-mini
- 追求更好效果:LLaMA 3.1 70B、Qwen2.5-72B
微调框架推荐用 LLaMA-Factory 或 Axolotl,支持 LoRA 和全量微调,配置简单:
# LLaMA-Factory 配置示例
model_name_or_path: meta-llama/Llama-3.1-8B-Instruct
stage: sft
finetuning_type: lora
lora_rank: 64
lora_alpha: 128
lora_target: all
dataset: agent_traces
template: llama3
output_dir: ./output/agent-compiled
per_device_train_batch_size: 4
gradient_accumulation_steps: 8
num_train_epochs: 3
learning_rate: 2e-4
训练时间取决于数据量和硬件配置。10 万条轨迹、单卡 A100、LoRA 微调,大约需要 10-20 小时。
第四步:部署和迭代
编译后的模型可以用 vLLM、TGI 或者 Ollama 部署。由于模型参数小、上下文短,推理延迟会比原始 Agent 系统低很多。
但不要期望一次微调就完美。实际部署后,你会发现一些训练数据没覆盖到的边缘情况。建议的做法是:
- 设置回退机制。当小模型的输出置信度低于阈值时,回退到原始的前沿模型。
- 持续收集数据。把线上遇到的新场景、新错误收集起来,定期重新训练。
- 监控关键指标。任务成功率、平均推理步数、用户满意度。
这个方向的更大意义
这篇论文让我想起编程语言的发展史。
早期程序员用汇编写代码,每一条指令都要自己操心。后来有了高级语言和编译器,程序员只管写逻辑,编译器负责优化和翻译。再后来有了 JIT 编译,运行时根据实际执行情况动态优化。
Agent 工作流现在就处于"汇编"阶段——你得用提示词明确告诉模型每一步该怎么做,模型每次执行都从头解释这些指令。"编译"到小模型权重,本质上是把程序逻辑固化成"机器码",执行效率自然大幅提升。
更进一步想,这个思路可以延伸到很多场景:
- RAG 系统。把检索、筛选、整合的逻辑编译进模型,减少检索调用次数。
- 代码助手。把特定代码库的知识和编码规范编译进模型,生成代码更符合项目风格。
- 客服机器人。把业务流程和常见问题处理逻辑编译进模型,响应更快、更一致。
当然,这不是万能药。编译后的模型牺牲了灵活性,换取了效率。对于需要处理高度开放、不可预测任务的场景,大模型+Agent 框架仍然是更好的选择。
但对于很多已经验证有效、相对稳定的 Agent 应用,"编译"是一条值得认真考虑的路径。毕竟,账单不会自己变少。
写在最后
这篇论文没有提出什么颠覆性的新架构,但它把一个实用的思路讲清楚了、验证了。
在 AI 落地越来越讲究 ROI 的今天,"怎么用更少的钱达到差不多的效果"是一个非常现实的问题。知识蒸馏、模型压缩、推理优化——这些听起来不那么性感的技术,可能才是让 AI 真正普及的关键。
如果你正在为 Agent 系统的高昂成本发愁,不妨试试这个思路。先小规模验证,收集几千条轨迹、微调一版小模型、在测试环境跑跑看。效果好的话,再逐步扩大数据量和应用范围。
技术债可以慢慢还,但账单每个月都要付。
参考来源
- Reddit r/MachineLearning 讨论帖 - 社区对这篇论文的讨论,包含一些实践经验分享
- LLaMA-Factory GitHub 仓库 - 论文中微调方法的推荐实现框架


