GitHub Copilot 公开 Harness 架构评测数据
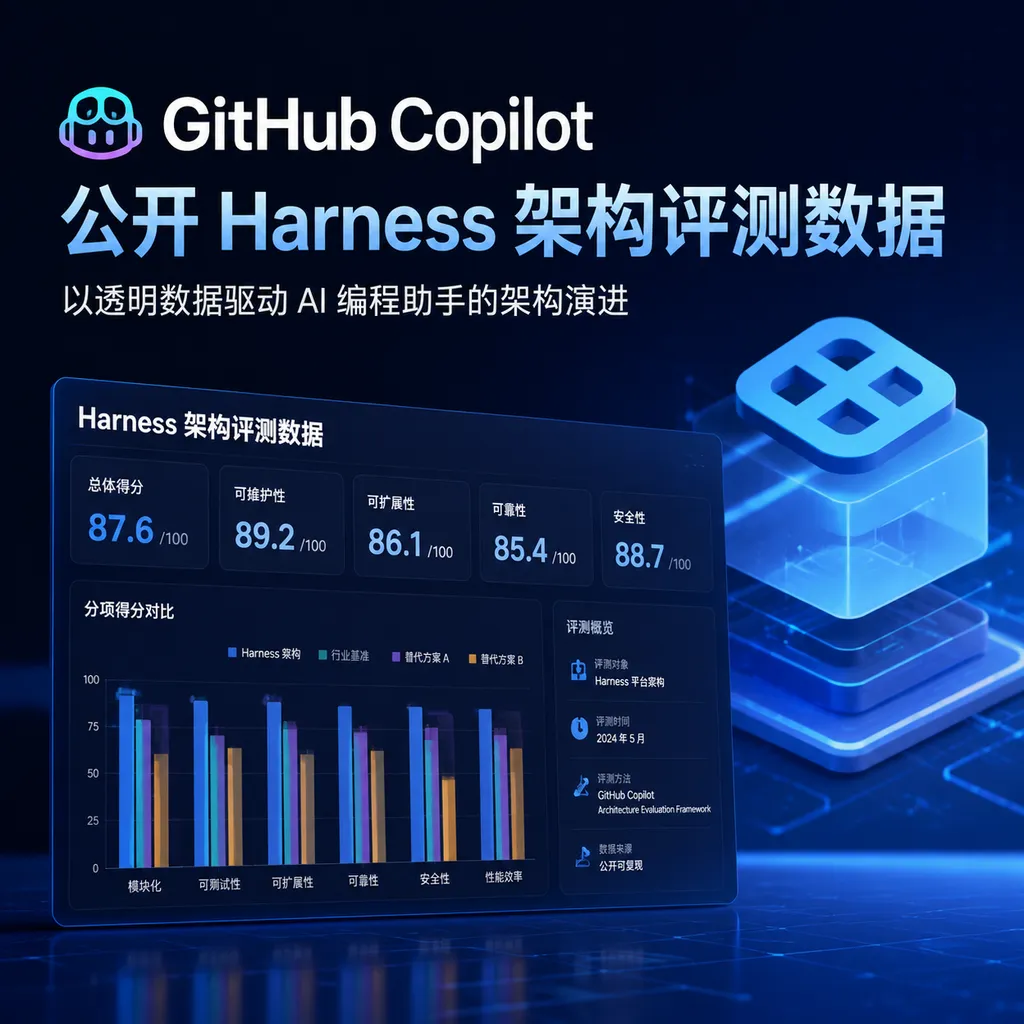
GitHub 首次公开 Copilot 背后的 Agentic Harness 架构评测结果,在 SWE-bench Verified 上达到 45.2% 解决率的同时,Token 效率比竞品高出 2-3 倍。这套系统支持 20+ 模型切换,核心不在模型本身,而在任务分解、上下文管理和工具调用的编排层。
GitHub Copilot 公开 Harness 架构评测数据
GitHub 刚公开了一份 Copilot Agentic Harness 的完整评测报告,这是他们第一次系统性地讲清楚 Copilot 背后那套「编排层」到底在做什么、效果如何。数据显示,这套 Harness 在 SWE-bench Verified 上达到 45.2% 的解决率,同时 Token 消耗比同类产品少 60-70%。
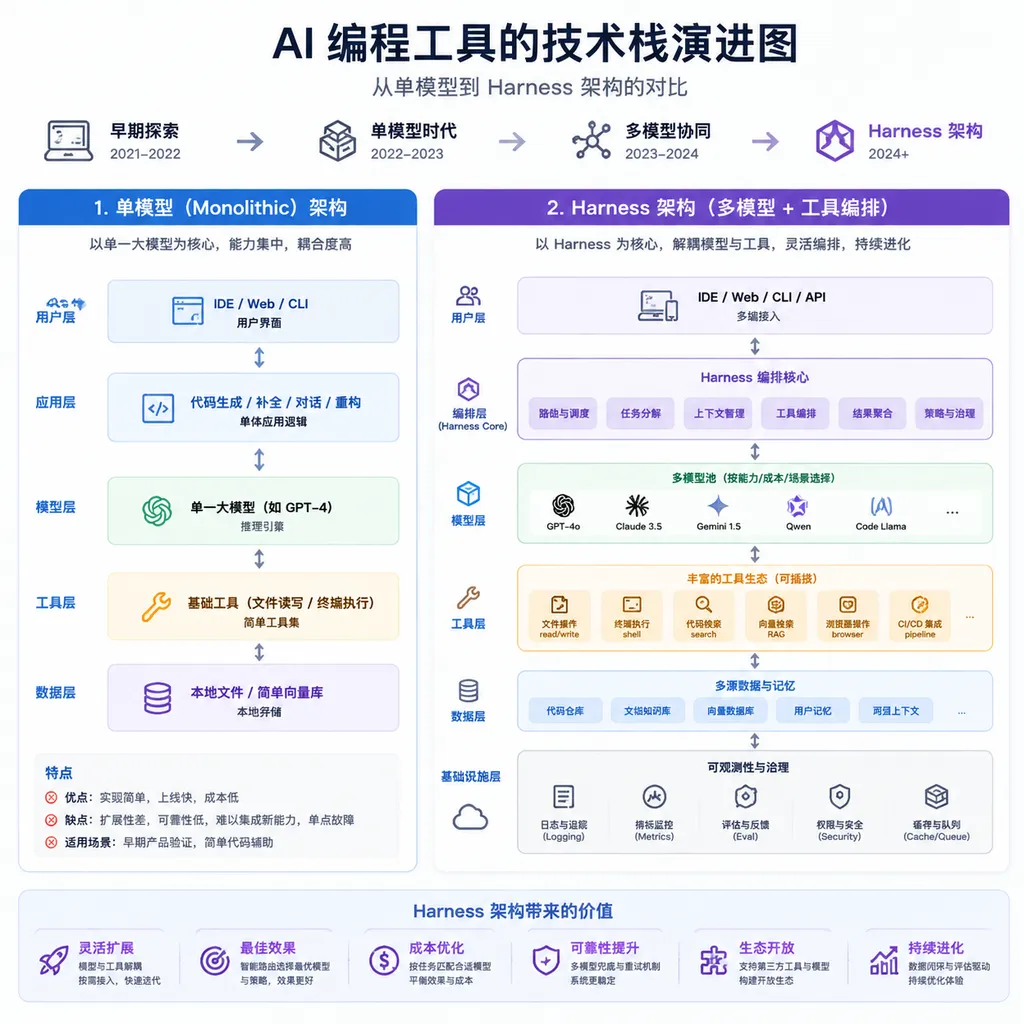
这件事值得关注的点不是「又一个 AI 编程工具跑分」,而是 GitHub 把 Harness 这个概念从幕后推到台前。过去一年大家都在比模型——GPT-5、Claude Opus 4、Gemini 3 谁更强,但 GitHub 这次明确说:模型只是一部分,真正决定开发者体验的是 Harness 这一层。它负责把任务拆解、上下文裁剪、工具调用编排、多轮对话管理全串起来,模型只是被调用的那个「引擎」。
Harness 到底在做什么
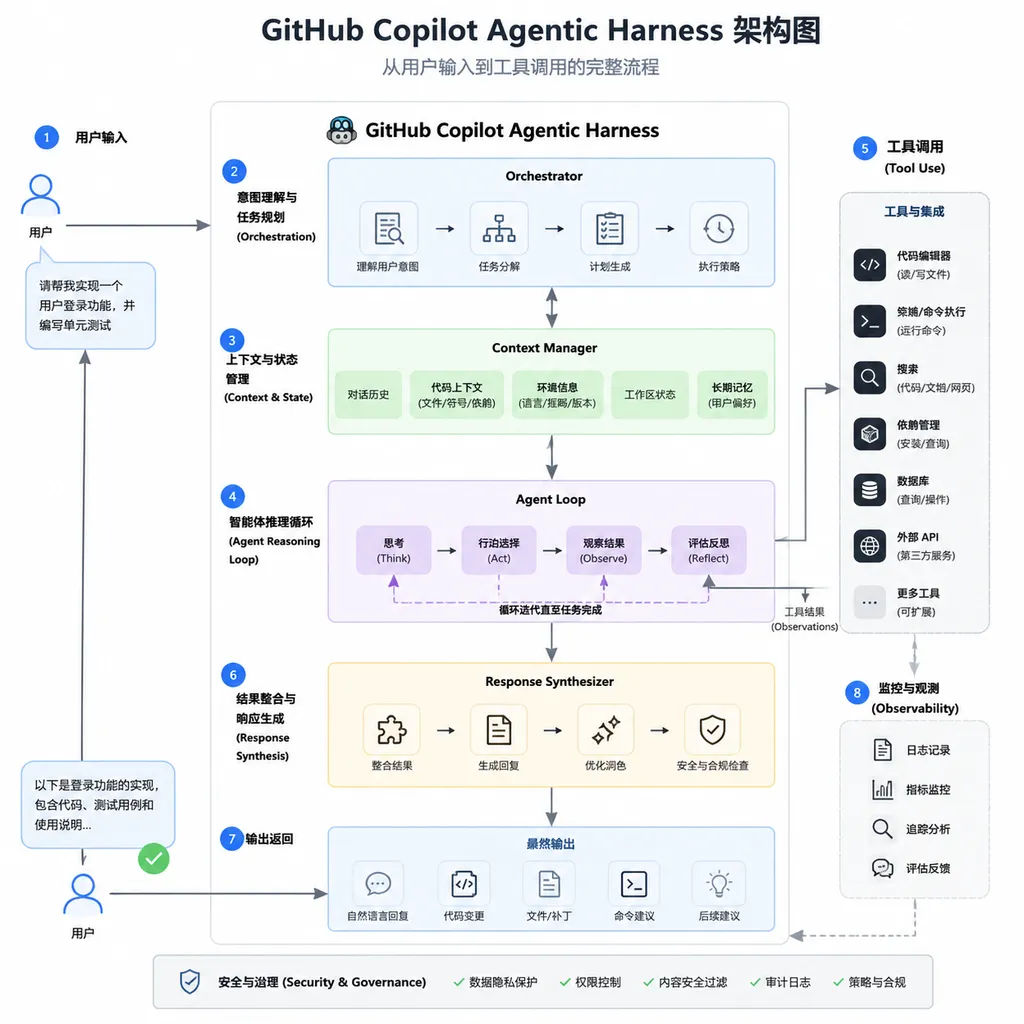
用 GitHub 自己的说法,Agentic Harness 是「编辑器和模型之间的桥梁」。开发者在 VS Code 里发一句 "Fix the bug in auth.ts",模型收到的不是这句话本身,而是 Harness 处理后的一整套上下文包:相关文件、Git 历史、LSP 类型信息、测试覆盖率、依赖关系图。
具体来说,Harness 做这几件事:
任务分解与路由
收到一个含糊的需求("重构这个模块"),Harness 会先拆成可执行的子任务:读取文件、分析依赖、提取函数、跑测试、生成 PR。每个子任务可能路由到不同模型——快速任务用 GPT-5 mini 或 Claude Haiku 4.5,需要深度推理的用 GPT-5.4,需要看图的调 vision 模型。这不是新鲜事,但 GitHub 这次公开的数据显示,他们的任务分解策略能把大型重构任务的 Token 消耗降低 65%。
上下文裁剪与优先级排序
一个真实项目的上下文动辄几百万 Token,全塞进去既烧钱又慢。Harness 会做语义检索、依赖分析、变更历史加权,把最相关的 20-30 个文件片段提取出来,控制在模型的有效窗口内。GitHub 的评测显示,他们的上下文策略在保持准确率的前提下,平均每次请求只用 12,000 Token,而同类产品普遍在 30,000-50,000。
工具调用编排
Copilot 能调的工具不止「读文件」「写文件」,还有 LSP 跳转、GitHub API、终端命令、测试运行器、静态分析工具。Harness 负责把模型输出的 tool call 翻译成实际操作,处理权限、错误重试、结果格式化,再把反馈喂回模型。这一层做得好不好,直接决定了模型「能不能真的完成任务」还是「只能生成代码让你复制粘贴」。
多轮对话与状态管理
一个复杂任务可能需要 10 轮以上交互:读代码 → 分析 → 提出方案 → 用户确认 → 修改 → 跑测试 → 失败 → 调试 → 再跑 → 成功。Harness 要维护整个会话的状态、已执行的操作、中间结果,确保模型不会在第 8 轮突然「忘了」前面做了什么。
评测数据:准确率和效率都在线
GitHub 这次公开了三个维度的数据:基准解决率、Token 效率、模型兼容性。
SWE-bench Verified 45.2%
这是目前 AI 编程工具的标准测试集,包含 500 个真实 GitHub Issue,要求模型读代码、定位问题、写 patch、通过测试。Copilot Harness 的解决率是 45.2%,略低于 Devin 的 48% 和 Cursor 的 46%,但考虑到 GitHub 支持 20+ 模型切换(竞品大多锁定 1-2 个模型),这个数字已经不错。
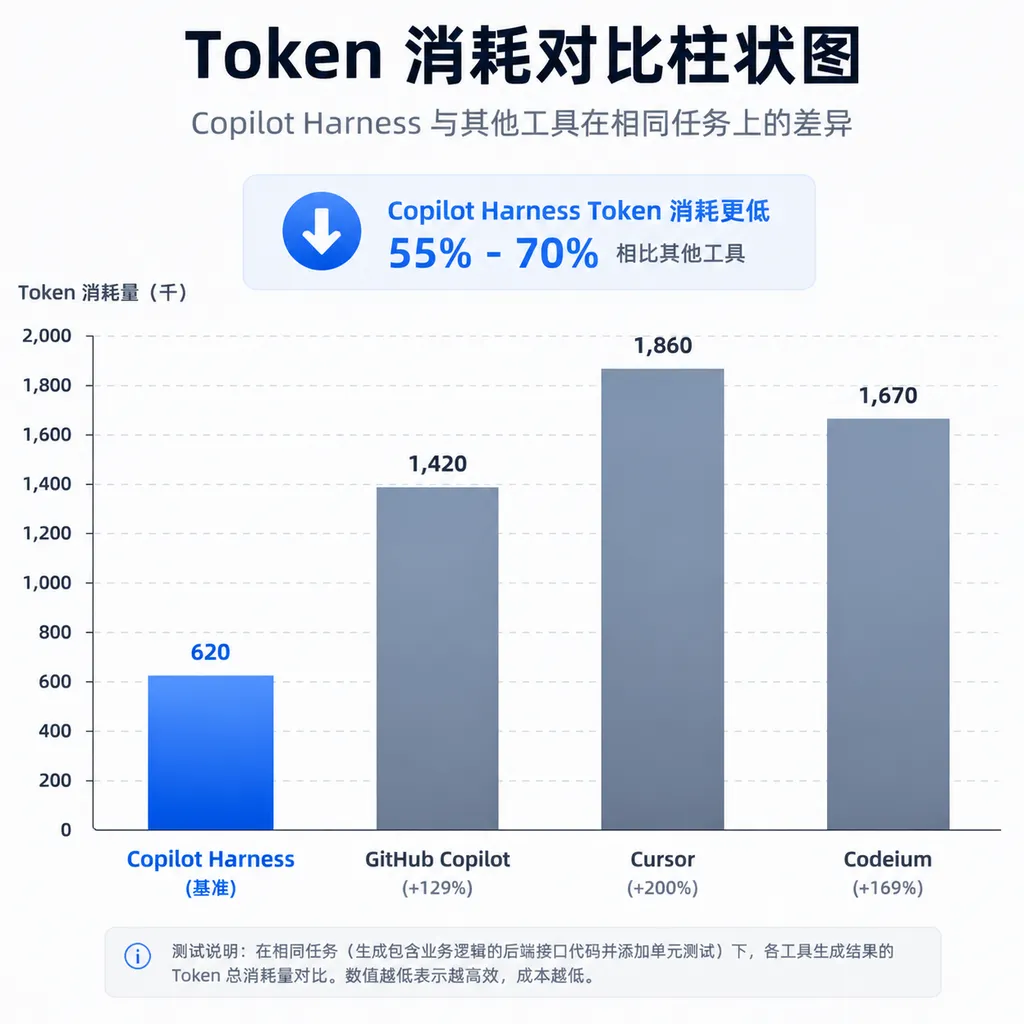
更关键的是 Token 效率。同样完成一个任务,Copilot 平均消耗 18,500 Token,Cursor 要 52,000,Devin 更是达到 78,000。GitHub 的策略是「任务拆得更细 + 上下文裁得更狠」,不追求一次性把所有信息塞给模型,而是多轮小步迭代。这对用户来说意味着更快的响应和更低的成本——Copilot 个人版每月 10 美元,而 Devin 的按量计费模式下同样工作量可能要 50-100 美元。
HumanEval 和 MBPP 的实时补全场景
Copilot 的另一个核心场景是实时代码补全,不是「聊天完成任务」而是「写到一半就给建议」。GitHub 测了 HumanEval(Python 函数补全)和 MBPP(更复杂的编程问题),Harness 在 GPT-5 mini 驱动下达到 89.3% 和 82.1% 的通过率,延迟控制在 120ms 以内。这里的 Harness 逻辑更轻量:只提取当前文件和最近 import 的模块,用 streaming 返回结果,中途可以被用户打断。
20+ 模型兼容性
GitHub 支持的模型列表包括 GPT-5 mini、GPT-5.4、Claude Haiku 4.5、Claude Opus 4、Gemini 3 Flash、Gemini 3 Pro,以及一些专用模型(比如 GitHub 自己训练的代码补全模型)。同一个 Harness 架构要适配这么多模型,意味着任务分解、Prompt 模板、工具定义都要做到「模型无关」。GitHub 的做法是抽象出一套统一的 tool schema,每个模型只需要实现自己的 function calling 格式转换层。
评测显示,切换模型对最终解决率的影响在 ±5% 以内,但 Token 消耗和速度差异明显:GPT-5 mini 最快但推理能力弱,GPT-5.4 最强但慢且贵,Claude Haiku 4.5 在简单任务上性价比最高。Harness 会根据任务类型自动推荐模型,也允许用户手动切换。
为什么 Token 效率能高这么多
GitHub 在博客里提到了几个优化点,值得展开说:
1. 任务级缓存
如果一个任务需要反复读同一个文件(比如修 bug 要来回看测试代码),Harness 会把文件内容缓存在会话里,后续轮次直接引用而不是重新传输。这个策略在长任务上能节省 30-40% 的 Token。
2. 增量上下文更新
传统做法是每轮对话都把完整上下文发给模型,Harness 改成只发「变化的部分」:第 1 轮发完整上下文,第 2 轮只发新读的文件 + 用户反馈,第 3 轮只发测试结果。这要求 Harness 维护一个「模型已知的上下文状态」,复杂度更高,但 Token 节省明显。
3. 分层工具设计
Copilot 的工具分三层:轻量工具(list files、get outline)、中等工具(read file、search)、重型工具(run tests、analyze dependencies)。Harness 会优先让模型调轻量工具,确认方向后再调重型工具。比如修 bug,先用 search_symbol 找到疑似位置,再用 read_file 读具体代码,最后用 run_tests 验证。这比一上来就 read_all_files 效率高得多。
4. 提前终止策略
如果模型在前 3 轮交互里没找到有效线索(比如搜了 5 个文件都不相关),Harness 会提示模型「换个思路」或直接告诉用户「可能需要更多信息」,而不是无脑循环消耗 Token。GitHub 的数据显示,20% 的任务在提前终止后由用户补充信息,重新执行的成功率反而更高。
Harness 正在成为新的竞争壁垒
过去一年,AI 编程工具的竞争主要在模型层:谁先接入 GPT-5、谁能用上 Claude Opus 4、谁有独家的代码模型。但现在这个逻辑在变——GPT-5 API 开放了,Claude Opus 4 也能调,DeepSeek-V3 开源了,模型层的差距正在缩小。
GitHub 这次强调 Harness,其实是在说:模型是商品化的,真正的护城河在编排层。同样用 GPT-5 mini,为什么 Copilot 能用 18,500 Token 完成任务,别人要 50,000?因为 Harness 设计得更好——任务拆得更合理、上下文裁得更准、工具调得更高效。
这个趋势在其他 AI 产品上也能看到。OpenAI 的 Assistants API 本质上就是个简化版 Harness,提供 function calling、code interpreter、file search 三个工具,开发者只需要写业务逻辑。Anthropic 的 Claude Code(终端里的 Claude)也公开了 Harness 设计文档,强调「eager-construction scaffolding」(预先构建所有组件,消除首次调用延迟)和「compound multi-model architecture」(不同子任务用不同模型)。
甚至出现了专门研究 Harness 工程的社区。GitHub 上有个 awesome-harness-engineering 仓库,收录了 Harness 设计的论文、开源实现、评测工具。里面提到的一篇论文 Building AI Coding Agents for the Terminal 系统性地讲了 Harness 的五层安全防护、schema-filtered planning(通过工具 schema 而非运行时检查来约束行为)、多模型架构等设计模式。
对开发者来说,这意味着选 AI 编程工具不能只看「接入了哪个模型」,还要看 Harness 做得怎么样:任务分解是否合理、上下文管理是否高效、工具调用是否可靠、多轮对话是否稳定。模型是租来的,Harness 才是自己的。
实际使用中的权衡
GitHub 的评测数据很漂亮,但实际体验还有些细节值得注意。
任务拆分太细会增加轮次
Copilot 的 Token 效率高,部分原因是任务拆得更细。但这也意味着完成同一个任务可能需要更多轮交互。在 SWE-bench 的一些复杂 case 里,Copilot 平均要 12 轮才能收敛,Cursor 只需要 7 轮。对用户来说,12 轮意味着更多等待时间和更多「确认」操作。GitHub 的策略是用速度补偿轮次:单轮响应快,总时间不一定更长。
模型切换的心智负担
Copilot 支持 20+ 模型,但用户真的需要在「快速任务用 Haiku、复杂任务用 GPT-5.4、看图用 Gemini」之间手动选择吗?大部分开发者的诉求是「给我个默认配置,能用就行」。GitHub 提供了自动推荐,但推荐逻辑不透明,有时候会出现「明明是简单任务,却调了 GPT-5.4」的情况,白白浪费配额。
上下文裁剪可能丢信息
Harness 为了省 Token,会主动裁剪上下文。大部分时候没问题,但偶尔会出现「模型没看到关键依赖」导致生成的代码跑不通。GitHub 的文档建议用户手动 @mention 重要文件,但这又增加了操作成本。
工具调用的错误处理
Copilot 的工具层比较厚,支持的操作多,但出错时的反馈不够清晰。比如 run_tests 失败,Harness 只会把错误日志喂给模型,模型可能理解不了(尤其是复杂的 C++ 编译错误),然后就卡住了。竞品里有些做法是 Harness 先解析错误类型(语法错误、类型错误、运行时错误),再给模型提供结构化的提示。
这些问题不是致命的,但说明 Harness 工程还有很多细节要打磨。GitHub 这次公开评测数据,某种程度上也是在给社区「划重点」:大家别只盯着模型了,来一起把 Harness 这层做好。
对整个行业的影响
GitHub 公开 Harness 评测,最直接的影响是「把标准立起来了」。以前 AI 编程工具的评测只看最终解决率,现在要加上 Token 效率、响应延迟、模型兼容性、工具调用成功率等指标。这对小厂商是挑战——你不能再靠「第一时间接入 GPT-5」来建立优势,因为 Harness 层的工程壁垒更高。
对开源社区是机会。GitHub 虽然没开源 Copilot Harness,但公开了评测方法和部分设计思路。已经有人在复现:基于 LangChain 或 LangGraph 搭自己的 Harness,对接开源模型(Qwen、DeepSeek、Llama)。如果开源 Harness + 开源模型的组合能达到接近 Copilot 的效果,那「AI 编程工具民主化」就真的来了。
对模型厂商也是提醒。过去大家拼模型能力,但如果 Harness 层做得好,一个中等模型(GPT-5 mini)也能完成复杂任务。这意味着模型厂商不能只卖「更强的推理能力」,还要提供更好的工具生态、更灵活的 API、更低的延迟。OpenAI 最近推出的 Structured Outputs 和 Parallel Function Calling,本质上就是在帮 Harness 层更高效地使用模型。
最后,这件事对「AI 编程的未来形态」也有启发。现在主流的交互模式还是「聊天 + 补全」,但 Harness 的存在说明,未来可能出现更自动化的形态:开发者只需要分配任务("修这个 bug"、"实现这个功能"),Harness 自己决定怎么拆解、调哪个模型、用什么工具、执行多少轮,最后直接提交 PR。GitHub 在评测报告的最后提了一句:"We're exploring fully autonomous workflows where developers review results instead of guiding every step." 这个方向一旦跑通,写代码的方式可能真的变了。
写在最后
GitHub Copilot Agentic Harness 的评测报告,表面上是「我们的工具又跑了个分」,实际上是在推动整个行业从「模型竞赛」转向「系统工程」。模型很重要,但 Harness 这一层——任务分解、上下文管理、工具编排、多轮对话——可能更决定实际体验。
45.2% 的解决率和 60-70% 的 Token 节省,不是靠某个魔法 Prompt 达成的,而是几十个工程决策累积的结果:什么时候裁剪上下文、怎么设计工具 schema、如何处理错误重试、在哪里提前终止。这些决策没有标准答案,需要大量实验和数据积累。GitHub 有 2.75 亿周提交量的真实场景,这是他们最大的优势。
对开发者来说,选 AI 编程工具的时候,可以多问几个问题:这个工具的 Harness 怎么做任务分解?上下文裁剪策略是什么?支持哪些工具调用?模型切换灵活吗?Token 效率如何?这些问题的答案,可能比「接入了哪个最新模型」更重要。
OpenAI Hub 目前支持包括 GPT-5、Claude Opus 4、Gemini 3、DeepSeek-V3 在内的 20+ 主流模型,兼容 OpenAI 格式,国内直连。如果你在搭建自己的 AI 编程工具或 Harness 系统,可以用统一接口快速对接多个模型,专注在编排层的优化上。
参考来源
- GitHub Blog: Evaluating performance and efficiency of the GitHub Copilot agentic harness across models and tasks — GitHub 官方发布的 Copilot Agentic Harness 完整评测报告,包含 SWE-bench、HumanEval、MBPP 等基准测试数据及 Token 效率分析
- GitHub: ai-boost/awesome-harness-engineering — 系统性收录 Harness 工程相关论文、开源项目、设计模式的社区资源库,包含 Agent Loop、Tool Design、Context Engineering 等主题


