英伟达开源MoE加速神器:一行代码,微调快3.7倍
英伟达开源 NeMo AutoModel,通过专家并行、DeepEP 和 Transformer Engine 三板斧,让 Transformers v5 上的 MoE 模型微调吞吐量提升 3.7 倍,显存占用降低 32%,门槛低到只需一行 import。
英伟达开源MoE加速神器:一行代码,微调快3.7倍
英伟达刚刚开源了 NeMo AutoModel,一个专门为 MoE(混合专家)模型设计的训练加速库。
效果很直接:在 Transformers v5 基础上,30B 级别的 MoE 模型微调吞吐量提升 3.4 到 3.7 倍,峰值显存占用降低 29% 到 32%。而开发者需要做的,只是在代码里加一行 import。
这不是 PPT 发布,是已经能跑的东西。
MoE 微调的痛点:专家太多,卡不够用
先说清楚为什么需要这个工具。
MoE 架构这两年火起来,核心逻辑是「稀疏激活」——模型有很多专家(Expert),但每个 token 只路由到其中几个。这样总参数量可以很大,但推理时的计算量保持可控。DeepSeek-V3、Mixtral、Qwen-MoE 都是这个路子。
但微调 MoE 模型是另一回事。
训练时,所有专家的权重都要加载到显存里,梯度也要算。一个 30B 参数的 MoE 模型,实际显存占用可能比同等激活参数的 Dense 模型高出好几倍。更麻烦的是,专家之间的负载不均衡——有的专家被频繁激活,有的长期闲置,但它们都占着显存。
多卡训练时问题更复杂。传统的数据并行(Data Parallel)对 MoE 不友好,因为每张卡都要存全部专家。张量并行(Tensor Parallel)可以切分,但专家之间的通信开销会吃掉加速收益。
结果就是:很多团队有训 MoE 的需求,但要么卡不够,要么效率太低,要么需要深度定制分布式代码。
这正是 NeMo AutoModel 要解决的。
NeMo AutoModel 的三板斧
英伟达这次的方案,核心是三个技术组件的整合:
1. 专家并行(Expert Parallelism)
专家并行不是新概念,但之前实现起来很麻烦。
基本思路是:把不同的专家分配到不同的 GPU 上,每个 GPU 只负责一部分专家的计算。当某个 token 需要路由到特定专家时,通过 All-to-All 通信把数据发过去,算完再发回来。
听起来简单,做起来全是坑。通信模式要设计好,负载要均衡,和其他并行策略(数据并行、张量并行、流水线并行)要能组合使用。
NeMo AutoModel 把这些封装好了。开发者不用手写通信逻辑,只需要在配置里指定专家并行度,框架自动处理分配和通信。
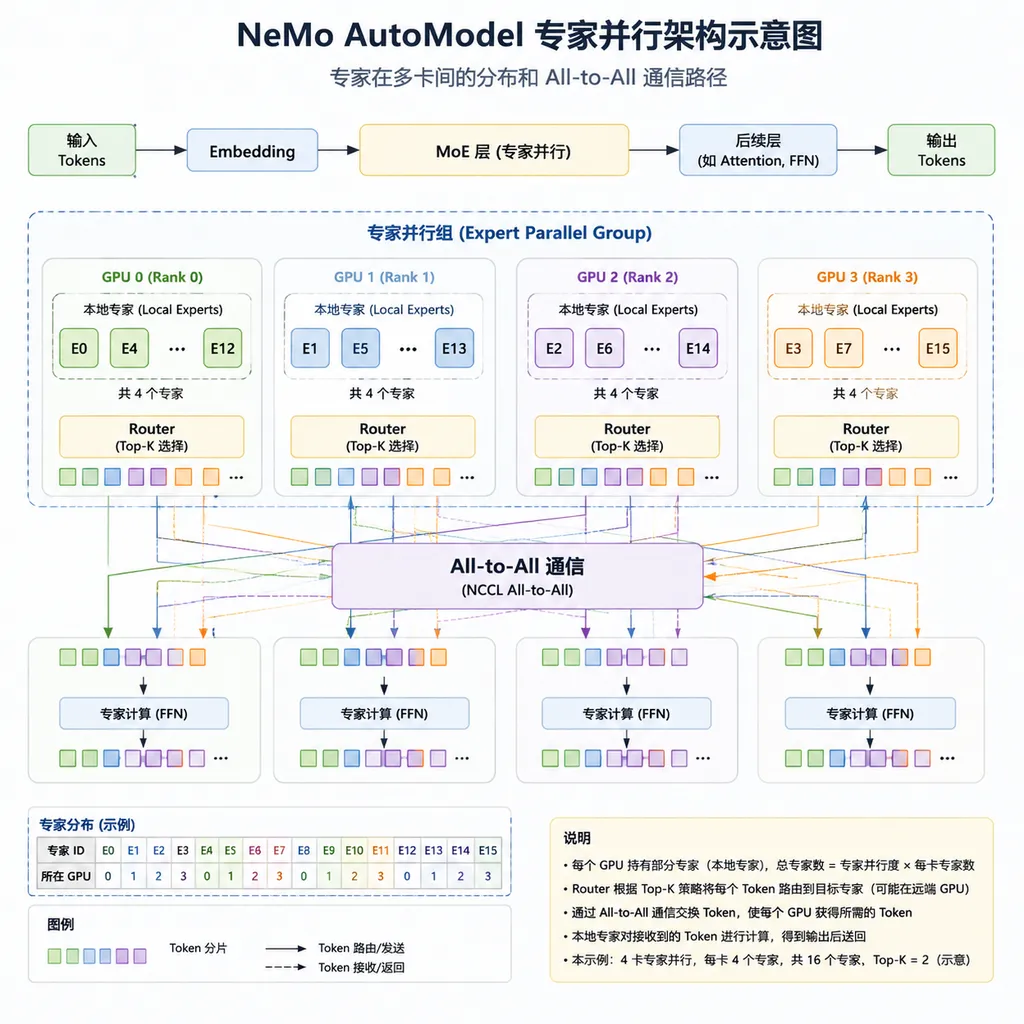
2. DeepEP:低开销的专家通信
专家并行的瓶颈在通信。All-to-All 操作在大规模集群上很贵,尤其是跨节点时。
英伟达的 Megatron-Core 团队搞了一个叫 DeepEP 的通信优化库,专门解决这个问题。
几个关键优化:
- 通信-计算重叠:在等待专家返回结果的时候,先算其他层的东西,不让 GPU 干等
- 分层通信:节点内用 NVLink,跨节点用 NVSwitch/InfiniBand,根据拓扑选最优路径
- 动态负载均衡:根据实际的专家激活分布,动态调整通信策略
实测数据显示,DeepEP 能把专家并行的通信开销压到比较低的水平,在 8 卡 A100/H100 节点上,通信时间占比可以控制在 15% 以内。
3. Transformer Engine:FP8 训练加速
第三个组件是英伟达的 Transformer Engine(TE),这个已经存在一段时间了,但和 MoE 的结合是这次的重点。
TE 的核心能力是 FP8 混合精度训练。在 H100 等 Hopper 架构 GPU 上,FP8 的计算吞吐量是 FP16 的两倍。但 FP8 精度低,直接用会掉点,TE 通过动态缩放(Dynamic Scaling)和选择性精度(关键层用高精度)来解决这个问题。
对 MoE 模型来说,专家层的 FFN(前馈网络)是计算大头,也是最适合用 FP8 加速的部分。TE 还提供了 GroupedGEMM 内核,可以把多个专家的矩阵乘法打包成一个批次执行,进一步提高 GPU 利用率。
三个组件加起来,效果就是开头说的:吞吐量 3.7 倍,显存降 32%。
实测数据:30B 级别 MoE 模型
英伟达给出的基准测试是在单节点 8 卡 H100 上做的,对比对象是原生 Transformers v5 + torch._grouped_mm(PyTorch 官方的 MoE 优化)。
测试模型包括几个 30B 参数级别的开源 MoE 模型:
| 指标 | Transformers v5 原生 | NeMo AutoModel | 提升 | |------|---------------------|----------------|------| | 训练吞吐量 (tokens/sec) | ~3,500 | ~13,000 | 3.7x | | 峰值显存占用 | 基准 | -32% | 显著降低 | | 单卡算力利用 (TFLOPs/sec) | ~70 | 190-280 | 2.7-4x |
几个值得注意的点:
吞吐量提升不是均匀的。 模型越大、专家越多,提升越明显。对于 8 专家的模型,提升在 3.4 倍左右;16 专家的模型可以到 3.7 倍。因为专家越多,并行切分的收益越大。
显存节省主要来自两个地方。 一是专家并行本身——每张卡只存部分专家;二是 FP8 训练——权重和激活值的存储减半。两者叠加,32% 的降幅是合理的。
算力利用率的提升比吞吐量还夸张。 从 70 TFLOPs 到 190-280 TFLOPs,说明原生实现有大量的 GPU 空闲时间,被通信阻塞或者内核效率低。NeMo AutoModel 把这些 gap 填上了。
当然,这些数字是在理想条件下测的。实际项目里,数据加载、预处理、checkpoint 保存等环节都会影响端到端性能。但即使打个七折,2.5 倍的实际提升也很香。
代码层面:真的只需要一行 import 吗?
英伟达宣传的「一行 import」是这样的:
# 原来的代码
from transformers import AutoModelForCausalLM, Trainer
model = AutoModelForCausalLM.from_pretrained("some-moe-model")
trainer = Trainer(model=model, ...)
trainer.train()
# 加速后的代码
import nemo.collections.llm.automodel # 就这一行
from transformers import AutoModelForCausalLM, Trainer
model = AutoModelForCausalLM.from_pretrained("some-moe-model")
trainer = Trainer(model=model, ...)
trainer.train()
原理是 NeMo AutoModel 通过 import hook 机制,自动替换 Transformers 里的关键组件——把原生的 MoE 层换成优化过的版本,把 Trainer 的分布式逻辑换成支持专家并行的版本。
这种设计的好处是侵入性低,已有代码几乎不用改。坏处是黑盒程度高,出了问题不好调试。
实际使用时,还是建议显式配置一下并行策略:
import nemo.collections.llm.automodel
from nemo.collections.llm import ParallelConfig
# 显式指定并行策略
config = ParallelConfig(
expert_parallel=4, # 专家并行度
tensor_parallel=2, # 张量并行度
use_fp8=True, # 启用 FP8
use_grouped_gemm=True, # 启用 GroupedGEMM
)
# 后面正常用 Transformers API
还有几个前置条件:
- GPU 要求:FP8 加速需要 Hopper 架构(H100/H200),Ampere(A100)也能用但没有 FP8 收益
- 驱动版本:CUDA 12.0+,cuDNN 8.9+
- Transformers 版本:需要 v5.0+,老版本的 MoE 实现不兼容
- 模型兼容性:目前支持 Mixtral、Qwen-MoE、DeepSeek-MoE 等主流架构,自定义 MoE 结构可能需要适配
和其他方案的对比
MoE 训练加速不是新赛道,市面上已经有一些方案。
vs Unsloth
Unsloth 也宣称能加速 MoE 微调,用的是 Split LoRA 方法——只训练部分专家的 LoRA 权重。
根据 Unsloth 自己的数据,他们的方案比 Transformers v5 快 2 倍,显存省 35%。而 NeMo AutoModel 是 3.7 倍和 32%。
但两者不是简单的数字比较:
- Unsloth 只支持 LoRA/QLoRA,不支持全参数微调。NeMo AutoModel 两种都支持。
- Unsloth 的优化偏向单卡场景,多卡扩展能力有限。NeMo AutoModel 本身就是为分布式设计的。
- Unsloth 更轻量,安装简单,适合个人开发者。NeMo AutoModel 依赖链更重,但功能更全。
如果你只有一两张卡,跑 LoRA 微调,Unsloth 可能更合适。如果有多卡集群,想做全参数微调或者更大规模的训练,NeMo AutoModel 是更好的选择。
vs DeepSpeed-MoE
微软的 DeepSpeed 也有 MoE 支持,是之前很多团队的选择。
对比下来:
- DeepSpeed-MoE 的优化更通用,不依赖英伟达特定硬件。NeMo AutoModel 深度绑定英伟达生态(TE、DeepEP),在 N 卡上效果更好,但换到 AMD 或其他硬件就没法用。
- DeepSpeed 的 ZeRO 优化可以和 MoE 结合,NeMo AutoModel 目前没看到类似的内存优化策略。
- 集成度不同。DeepSpeed 需要改 Trainer 代码,NeMo AutoModel 的 import hook 更无缝。
vs Megatron-LM
英伟达自己的 Megatron-LM 是大模型训练的老牌框架,支持 MoE。
问题是 Megatron-LM 的学习曲线太陡。它有自己的数据格式、模型定义方式、训练脚本结构,和 Transformers 生态完全不兼容。想用 Megatron-LM 训一个 HuggingFace 上的模型,得先做模型转换,很麻烦。
NeMo AutoModel 可以看作是把 Megatron 的优化能力「平民化」——保留性能,降低门槛。
这对开发者意味着什么?
说几个实际的影响:
30B 级别 MoE 模型的微调门槛大幅降低
以前微调 Mixtral-8x7B 这种模型,要么用 QLoRA 在单卡上慢慢跑,要么租一堆卡然后自己折腾分布式。现在有了 NeMo AutoModel,8 卡 H100 就能跑得很顺畅,效率还不错。
对于有几张高端卡的团队(高校实验室、创业公司),这是直接的利好。
MoE 架构的应用会更广
训练门槛降低,意味着更多团队会尝试 MoE。之前 MoE 主要是大厂在玩,小团队很难跟进。现在至少微调这一环不再是瓶颈。
可以预见,接下来会有更多基于 MoE 的垂直领域模型出现。
英伟达的生态锁定更深了
NeMo AutoModel 的性能优势,很大程度上来自 Transformer Engine 和 DeepEP 这些英伟达专有技术。用了这套方案,就很难迁移到其他硬件上。
这不是阴谋论,只是客观事实。英伟达的 CUDA 生态护城河又深了一层。
局限性和注意事项
几个当前的限制:
-
预训练支持有限。目前 NeMo AutoModel 主要优化的是微调场景,预训练的支持还在完善中。如果你想从头训一个 MoE 模型,可能还是得用 Megatron-LM。
-
模型覆盖不全。官方验证过的模型列表有限,一些新出的 MoE 模型可能需要社区适配。
-
调试困难。import hook 的方式虽然方便,但出了问题(比如显存 OOM、训练 loss 异常)不好定位是框架的问题还是用户代码的问题。
-
文档还在完善。开源刚放出来,文档和示例还不够丰富,遇到问题可能需要看源码或者等社区沉淀。
怎么开始用?
安装:
pip install nemo_toolkit[all]
# 或者只装 LLM 相关
pip install nemo_toolkit[llm]
确保环境满足要求后,跑一个最小示例:
import nemo.collections.llm.automodel
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
from datasets import load_dataset
# 加载模型和数据
model_name = "mistralai/Mixtral-8x7B-v0.1"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 准备数据集(示例)
dataset = load_dataset("your-dataset")
# 配置训练参数
training_args = TrainingArguments(
output_dir="./output",
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
num_train_epochs=1,
bf16=True,
logging_steps=10,
)
# 训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
)
trainer.train()
如果一切正常,你应该能在日志里看到 NeMo AutoModel 的初始化信息,以及明显更高的训练吞吐量。
写在最后
英伟达这次开源 NeMo AutoModel,时机选得挺好。
MoE 架构正在成为主流,从 GPT-4 到 DeepSeek-V3 到 Grok,大家都在往这个方向走。但训练和微调 MoE 的工具链一直不够完善,成了落地的瓶颈。
现在英伟达把自己内部的优化技术打包开源,一方面是在巩固 CUDA 生态的护城河,另一方面确实降低了 MoE 的使用门槛。
3.7 倍的加速、32% 的显存节省,这些数字不是革命性的突破,但足够让很多之前「差一点就能跑」的项目变得可行。
如果你在做 MoE 相关的工作,值得花时间试一下。
参考来源
- 知乎专栏 - 大模型生成提速2倍!单GPU几小时搞定微调 - 大模型微调加速方法综述
- GitHub - Firefly 大模型训练工具 - 开源大模型训练框架,支持多种模型的微调


