Trellis 支持 Codex Hook 与 Sub-Agent,AI 编程框架进入编排时代

Trellis 近日更新支持 Codex 的 Hook 与 Sub-Agent 机制,让 AI 编程代理具备会话级生命周期管理和多代理编排能力,但上下文占用问题仍待优化。
Trellis 最近推了一个值得关注的更新:正式支持 Codex 的 Hook 与 Sub-Agent 机制。
这不是一个小功能迭代。它意味着 Trellis 从一个「帮你管 spec 和工作流的脚手架」,开始往「AI 代理编排层」的方向走了一步。对于正在用 Codex、Claude Code 这类终端 AI 编程工具的开发者来说,这个变化直接影响你的日常工作流。
先说 Hook 机制到底干了什么
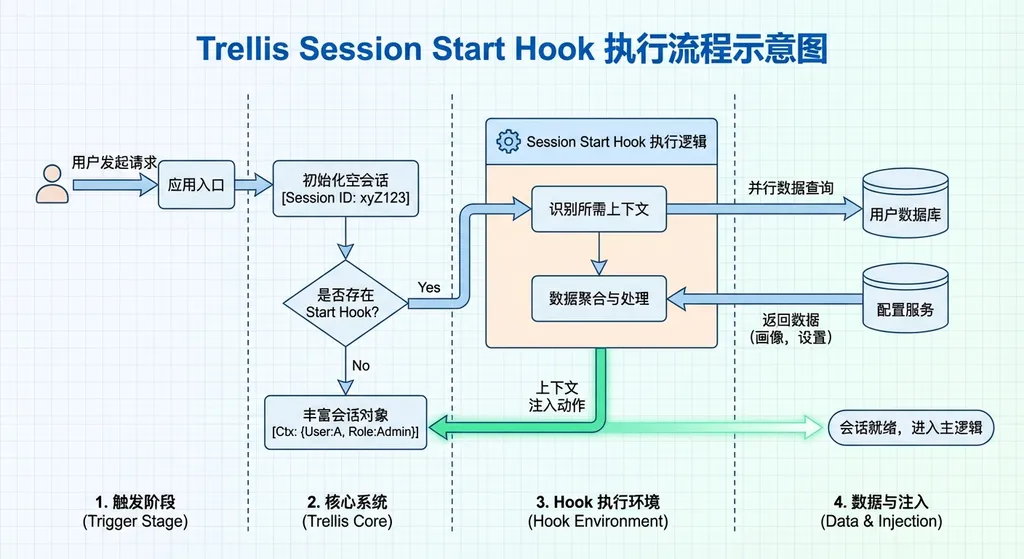
Trellis 的 Hook 机制本质上是给 AI 编程会话加了生命周期钩子。最核心的是 Session Start Hook——每次你启动一个 Codex 会话,Trellis 会自动执行一套初始化流程:
- 读取
workflow.md,把项目的开发规范和流程注入上下文 - 运行
get-context.py,拉取当前开发者身份、Git 状态、活跃任务、历史对话元信息 - 读取 spec 索引,让 AI 知道项目有哪些规范文档可用
- 向开发者汇报上下文,然后问一句 "What would you like to work on?"
听起来简单,但这解决了一个真实痛点:每次开新会话,你不用再花 5 分钟手动给 AI 补背景了。Trellis 的 start.md 会把整个开发会话拉到它的标准单进程串行路径上——同一时间只有一个 agent 在运行,避免多个 AI 代理互相踩踏。
这个设计思路很清晰:AI 编程工具的上下文管理,不应该是开发者的负担。
Sub-Agent:让 AI 代理学会「分工」
比 Hook 更有意思的是 Sub-Agent 机制。
传统的 AI 编程会话是单线程的——你给一个指令,AI 执行,完了你再给下一个。Sub-Agent 的引入意味着主代理可以派生子代理去处理特定子任务,自己继续推进主线。
打个比方:以前你让 AI 重构一个模块,它得先分析代码、再改逻辑、再跑测试、再修 lint 问题,全部串行。有了 Sub-Agent,主代理可以把「跑测试并修复失败用例」这种相对独立的任务交给子代理,自己继续处理下一个文件。
在 Trellis 的实现里,Sub-Agent 和 Hook 是配合工作的。Session Start Hook 负责建立上下文基线,Sub-Agent 在这个基线上执行具体任务。task.py 和 add_session.py 都已经支持 --package 参数,这意味着在 monorepo 场景下,子代理可以被限定在特定包的范围内工作,不会越界。
这对大型项目来说是个实质性改进。想象一个 monorepo 里有 20 个包,你只想改 packages/cli 里的东西,Sub-Agent 可以只加载 spec/cli/backend/ 的规范,而不是把整个仓库的 spec 都塞进上下文窗口。
上下文占用:房间里的大象
但事情没那么美好。
社区里已经有开发者反馈了一个很现实的问题:Session Start Hook 执行完之后,上下文占用大概在 10% 左右。这个数字看起来不大,但如果你在跑一个大工程,Hook 加载 workflow.md 和 start.md 的内容会占到 40K-80K token 的上下文空间。
要知道,Codex 的上下文窗口是有硬上限的。40K-80K 的 token 被框架本身吃掉,留给实际编码任务的空间就少了一大截。有开发者直接指出:workflow.md 和 start.md 里有大量重复说明,能不能精简?
这个问题不是 Trellis 独有的。所有试图给 AI 编程工具加「记忆」和「规范」的框架都面临同样的权衡:注入越多上下文,AI 越了解你的项目;但上下文窗口是有限的,塞太多框架信息,留给实际代码的空间就不够了。
目前来看,Trellis 团队还没有给出明确的优化方案。这是一个需要持续关注的点——如果上下文占用问题不解决,Hook 机制在大型项目上的实用性会打折扣。
Monorepo 支持:不只是目录结构的事
这次更新里另一个值得展开说的是 monorepo 的深度支持。
Trellis 的 trellis init 现在能自动检测 pnpm、npm、Cargo、Go、uv workspaces 以及 git submodules。检测到 monorepo 结构后,它不再生成单一的 .trellis/spec/frontend、.trellis/spec/backend,而是给每个包生成独立的 spec 目录。
# 初始化一个 monorepo 项目
trellis init
# 如果自动检测不准,可以强制指定
trellis init --monorepo
# 也可以从自定义 registry 拉取 spec 模板
trellis init --registry https://github.com/your-org/your-spec-templates -t my-stack
生成的目录结构大概长这样:
.trellis/
├── config.yaml
├── workflow.md
├── scripts/
│ └── get-context.py
├── spec/
│ ├── cli/
│ │ ├── frontend/
│ │ ├── backend/
│ │ └── guides/
│ ├── web-app/
│ │ ├── frontend/
│ │ ├── backend/
│ │ └── guides/
│ └── shared-lib/
│ └── ...
└── workspace/
└── index.md
关键在于 spec_scope 过滤。Session Start Hook 支持按 scope 加载 spec,task.py 支持 --package 参数。这意味着 AI 在处理 cli 包的任务时,只会读取 spec/cli/ 下的规范文档,不会被其他包的信息干扰。
对于维护大型 monorepo 的团队来说,这个设计直接解决了「AI 上下文被无关信息污染」的问题。
多平台接入:不只是 Codex
Trellis 的野心不止于 Codex。从初始化生成的文件可以看出,它同时支持多个 AI 编程平台的接入:
.claude/— Claude Code.cursor/— Cursor.kiro/— Kiro.agents/— 通用 agent 配置AGENTS.md— 项目级 agent 说明
这意味着 Trellis 想做的是一个跨平台的 AI 编程工作流管理层。你的项目规范、开发流程、任务管理写一次,不管团队成员用的是 Codex 还是 Cursor 还是 Claude Code,都能共享同一套上下文。
这个定位很聪明。AI 编程工具的竞争还远没有分出胜负,开发者不想被绑定在某一个工具上。Trellis 把自己放在工具层之上,做「规范和流程的标准化」,不管下面跑的是哪个 AI,上面的工作流是一致的。
对开发者意味着什么
说回实际影响。
Hook + Sub-Agent 的组合,本质上是在回答一个问题:AI 编程代理的「操作系统」应该长什么样?
现在的 AI 编程工具,不管是 Codex、Cursor 还是 Claude Code,都还处于「单任务、无状态」的阶段。每次开会话都是一张白纸,开发者得反复交代背景。Trellis 的 Hook 机制试图解决「无状态」问题,Sub-Agent 试图解决「单任务」问题。
方向是对的,但成熟度还不够。上下文占用的问题说明框架本身的开销还需要优化,Sub-Agent 的调度策略也还在早期。社区里有开发者期待「稳定版发布」,这说明当前版本在生产环境中可能还有一些边界情况没有覆盖到。
如果你的项目已经在用 Codex 做日常开发,Trellis 的这次更新值得试一试。尤其是 monorepo 场景下的 spec 隔离和 Sub-Agent 的包级任务分发,能实实在在减少上下文污染。但如果你的项目规模不大,Hook 带来的上下文开销可能反而得不偿失。
和 API 调用的关系
对于通过 API 调用大模型来构建自己编程工具链的开发者,Trellis 的这套机制提供了一个参考架构。你完全可以在自己的工具里实现类似的 Hook 逻辑——在每次 API 调用前,自动注入项目上下文:
import openai
client = openai.OpenAI(
api_key="your-api-key",
base_url="https://api.openai-hub.com/v1" # OpenAI Hub 支持 GPT/Claude/Gemini/DeepSeek 等主流模型
)
# 模拟 Trellis 的 Session Start Hook:注入项目上下文
def build_session_context(project_path, package=None):
"""读取项目规范,构建会话上下文"""
context_parts = []
# 读取 workflow 规范
with open(f"{project_path}/.trellis/workflow.md") as f:
context_parts.append(f"## 项目工作流\n{f.read()}")
# monorepo 场景:只加载指定包的 spec
if package:
spec_path = f"{project_path}/.trellis/spec/{package}"
else:
spec_path = f"{project_path}/.trellis/spec"
# ... 加载 spec 文件
return "\n\n".join(context_parts)
session_context = build_session_context("./my-project", package="cli")
response = client.chat.completions.create(
model="claude-sonnet-4-20250514", # 通过 OpenAI Hub 调用 Claude
messages=[
{"role": "system", "content": session_context},
{"role": "user", "content": "重构 cli 包的命令解析模块,使用 clap v4 的 derive API"}
]
)
print(response.choices[0].message.content)
核心思路就是把 Trellis 的 Hook 逻辑抽出来,作为 API 调用的前置步骤。这样不管你用哪个模型,都能享受到自动上下文注入的好处。
写在最后
AI 编程工具正在从「补全代码」走向「理解项目」。Trellis 的 Hook + Sub-Agent 是这个趋势里一个有意义的尝试,它试图在 AI 和项目之间建立一个持久的、结构化的连接层。
但框架的价值最终取决于它的开销是否可控。40K-80K token 的上下文占用,对于一个「辅助层」来说偏重了。期待 Trellis 团队在后续版本中给出优化方案——比如按需加载 spec、压缩 workflow 描述、或者把部分上下文移到 retrieval 层而不是全部塞进 prompt。
这个方向没问题,执行还需要打磨。
参考来源:
- Trellis changelog:支持 Codex 的 Hook + Sub-Agent — 社区讨论帖,包含开发者对上下文占用问题的反馈
- Trellis 教程 — 博客园 — 详细的 Trellis 初始化与配置教程
- Trellis GitHub 仓库 — 源码与更新日志
