Sakana AI 发布 Fugu:不卷参数,卷调度

日本 AI 独角兽 Sakana AI 发布多智能体编排模型 Fugu,用一个 API 调度多个模型协作完成任务,在多项基准测试中超越 Opus 4.8 和 GPT-5.5,价格却只有前者的三分之一。
Sakana AI 发布 Fugu:不卷参数,卷调度
日本 AI 初创公司 Sakana AI 于 6 月 22 日发布了一款名为 Fugu(河豚)的新产品。它不是又一个「更大更强」的单体模型,而是一个专门被训练来「指挥其他模型」的编排系统。
简单说,你调用一个 API,背后是一整套会自己选模型、分派任务、验证结果、最后把答案整合起来的系统。对开发者来说,复杂度被封装掉了;对最终效果来说,组合拳往往比单打独斗更能打。
什么是「编排模型」?
过去几年,大模型军备竞赛的主旋律是「卷参数」——谁家模型更大、训练数据更多、跑分更高,谁就站在食物链顶端。但这条路正在遇到瓶颈:模型越大,训练成本越高,推理延迟越长,而不同模型在不同任务上的表现差异却在缩小。
Sakana AI 选了一条不同的路:与其造一个全能的神,不如建一个懂得调兵遣将的指挥官。
Fugu 本身是一个大语言模型,但它的任务不是直接回答你的问题,而是决定「让谁来回答」。当一个请求进来,Fugu 会动态判断:
- 调用哪个模型最合适?
- 任务要分几步完成?
- 中间结果要不要验证?
- 要不要递归调用自己来处理子任务?
这套能力来自两篇 ICLR 2026 的论文。TRINITY 用一个轻量协调器,把「思考者」「执行者」「验证者」三种角色动态分派给不同模型;Conductor 则用强化学习,让系统自己学出一套用自然语言协调 Agent 的策略。
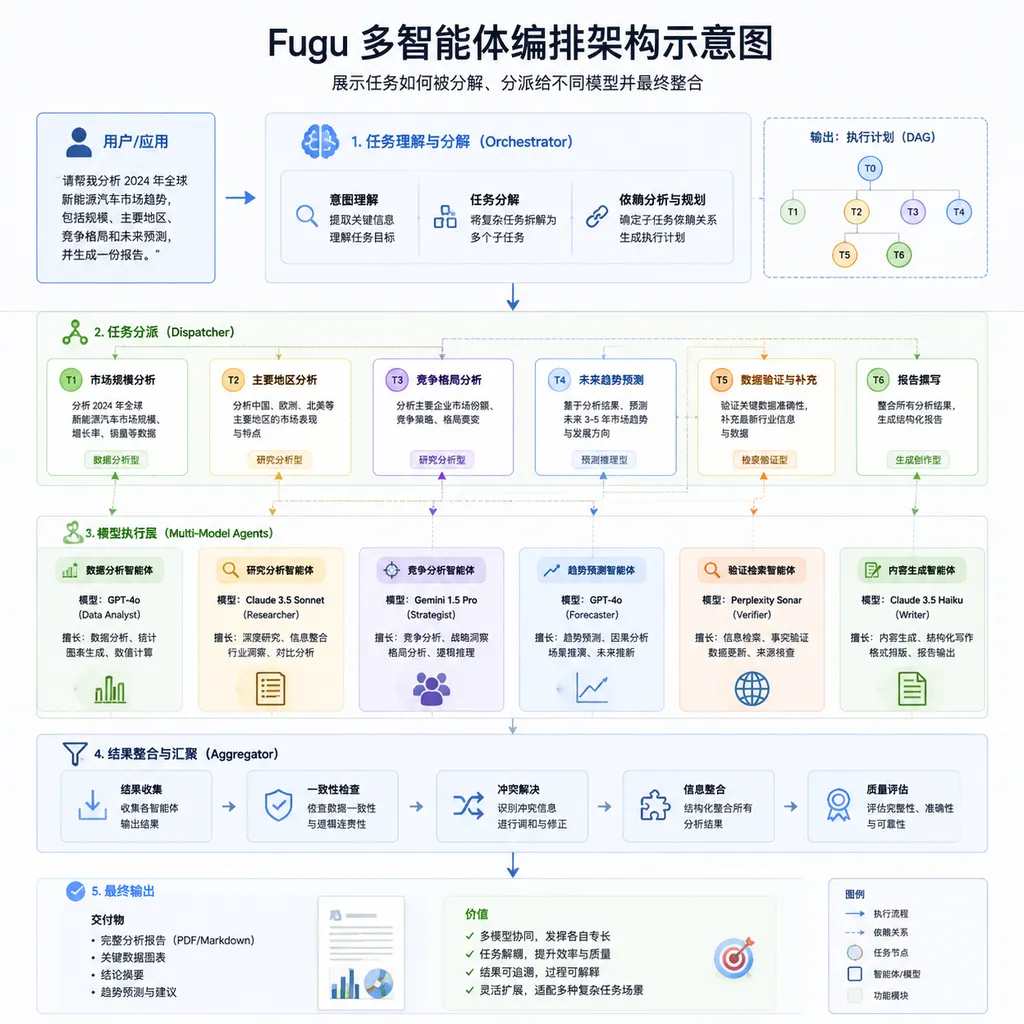
打个比方:传统的模型调用像是找一个全科医生看所有病,Fugu 更像是一个会诊系统——你挂一个号,系统自动帮你约心内科、神经科、影像科的专家,各自出报告,最后给你一个综合诊断。
两个版本,两种定位
Fugu 分两个版本:
标准版 Fugu
走效能与低延迟的平衡路线,适合日常场景:
- 聊天机器人
- 代码辅助和审查
- 日常业务自动化
Fugu Ultra
主打最高准确度,锁定那些「一般模型搞不定」的硬任务:
- Kaggle 竞赛级别的数据科学问题
- 论文复现和学术研究
- 网络安全分析
- 专利检索和法律文档处理
两者都提供 OpenAI 兼容的 API 端点,迁移成本几乎为零。
跑分:和顶尖模型打得有来有回
Sakana AI 给出了一系列基准测试数据,Fugu Ultra 在多个硬核测试中直接对标当前的前沿模型:
| 测试项目 | Fugu Ultra | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro | |---------|------------|----------|---------|----------------| | SWE Bench Pro(编程) | 73.7 | 69.2 | 58.6 | - | | LiveCodeBench Pro | 90.8 | - | 88.4 | - | | GPQA-D(研究生级科学推理) | 95.5 | - | - | 94.3 | | Humanity's Last Exam | 50.0 | - | - | - |
几个值得注意的点:
SWE Bench Pro 73.7 分,这是行业公认的硬核编程测试,要求模型在真实的 GitHub 仓库里定位 bug 并提交修复。Fugu Ultra 直接超过了 Opus 4.8 的 69.2。
GPQA-D 95.5 分,这个测试考的是研究生级别的科学推理能力,是目前公开可用模型中的最高分。
LiveCodeBench Pro 90.8 分,压过 GPT-5.5 的 88.4。
更关键的是,Sakana AI 强调这些成绩是在模型池中不包含 Claude Fable 5 和 Mythos Preview 的情况下取得的——换句话说,Fugu 没有「作弊」靠调用最强模型来刷分,而是靠编排中等水平的模型组合出了前沿级表现。
实际场景:不只是刷榜
跑分好看是一回事,实际场景能不能用是另一回事。Sakana AI 给出了几个有意思的案例:
自动化 ML 研究
在 AutoResearch 任务中,Fugu Ultra 自主运行了 123 次实验,拿到了最优的 BPB 得分(0.9774 ± 0.0019)。这意味着它能像一个初级研究员一样,自己设计实验、跑数据、调参数、迭代优化。
日文古籍识别
处理日本历史文献的阅读顺序恢复时,Fugu 达到 NED 0.80,而其他模型只有 0.24 或直接失败。这不奇怪——Sakana AI 本身就是针对日文和日本文化做过专门优化的。
CAD 机械设计
在设计虹膜机构的任务中,Fugu 产出了一个可工作的设计,其他模型的方案则存在间隙或不完整。
金融预测
在 50 周的股票交易回测中,Fugu 实现了 +19.43% 的平均回报,其他模型均低于 15%。当然,回测和实盘是两回事,但至少说明在多步骤决策任务上,编排系统的优势是明显的。
定价:Opus 的三分之一
按量付费模式下,Fugu Ultra 的价格是:
- 输入:$5 / 百万 tokens(超过 27.2 万 tokens 后为 $10)
- 输出:$30 / 百万 tokens(超过 27.2 万 tokens 后为 $45)
作为对比,Opus 4.8 的价格是输入 $15、输出 $75。Fugu Ultra 的输入价格只有 Opus 的三分之一,输出价格不到一半。
计费逻辑也比较友好:只看当下启用的最高阶模型收费,不会每个被调用的模型都叠加计费。这解决了很多开发者对「多模型调用会不会贵死」的担忧。
时间点的玄机
这个发布时间点值得玩味。
6 月 12 日,Anthropic 因应美国出口管制要求,撤回了 Claude Fable 5 和 Mythos Preview 的公开 API 使用权限。对于很多非美国地区的开发者来说,一觉醒来发现自己用的模型没了。
Sakana AI CEO David Ha(前 Google Brain 研究员)在发布会上直接说:「我们的 Fugu Ultra 达到了 Fable 和 Mythos 的性能水平,而且不受美国出口管制影响。」
这话是说给谁听的,不言自明。
当 AI 供应链的地缘政治风险越来越高,「不依赖单一供应商」从一个技术选型问题变成了一个业务连续性问题。Fugu 的编排架构天然具备这个优势——个别模型无法访问,系统会自动切换到其他可用模型,不会对业务造成严重影响。
Sakana AI 是谁?
如果你没听说过 Sakana AI,值得花点时间了解一下。
这家公司 2023 年在东京成立,三位创始人来头都不小:
- Llion Jones:2017 年 Transformer 论文《Attention Is All You Need》的共同作者,现代大语言模型的奠基者之一
- David Ha:前 Google Brain 研究员,以「世界模型」(World Models)研究闻名,后来当过 Stability AI 的研究主管
- Ren Ito:负责运营和商务
公司走仿生路线,名字 Sakana 在日文中就是「鱼」,理念取自鱼群、演化这种集体智慧。这次的 Fugu(河豚)也延续同一套命名。
在日本,Sakana 几乎是国家队级别的存在。2025 年 11 月的 B 轮融资募到 1.35 亿美元,估值达到 26.5 亿美元,是日本最有价值的 AI 初创公司。投资人名单里有日本最大金融集团三菱日联(MUFG),还有美国中情局的创投部门 In-Q-Tel,加上 Khosla、NEA、Lux 等硅谷基金。
被外界称为「日本版 OpenAI」,但 Sakana 选的路和 OpenAI 完全不同——不是继续把单一模型练大,而是研究怎么让一群模型协作得更好。
和 OpenRouter Fusion 有什么区别?
今年 3 月,OpenRouter 推出了 Fusion,也是「一个 API 背后藏一堆模型」的思路。很多人会问:这两个东西有什么区别?
简单说:
- Fusion 偏向「投票制」——把同一个问题丢给多个模型并行作答,再由一个评审模型融合出最终答案
- Fugu 偏向「分工制」——训练出一个会拆解任务、分派角色、来回验收的指挥型模型
前者更适合「答案有标准」的场景,比如数学题、代码 bug;后者更适合「需要多步骤协作」的复杂任务,比如研究、设计、分析。
模型编排正在从一种工具,变成产品本身。
对开发者意味着什么?
几个实际的影响:
1. 模型选型的心智负担降低了
以前你得研究「哪个模型擅长什么」「这个任务该用 Claude 还是 GPT」,现在可以把这个决策交给编排系统。当然,你也失去了一部分控制权。
2. 成本结构可能更友好
对于复杂任务,与其一直调用最贵的模型,不如让编排系统帮你把简单的子任务分派给便宜的模型。Fugu 的计费方式也鼓励这种用法。
3. 供应链风险分散了
如果你之前 all in 某一家的 API,现在可能要重新考虑架构了。编排系统天然具备 fallback 能力。
4. 调试可能更麻烦
当结果不符合预期时,你得搞清楚是编排逻辑的问题还是底层模型的问题。黑盒程度更高了。
写在最后
当前沿模型之间的差距越缩越小,「把一群模型指挥得更好」可能比「再练一个更大的模型」更有优势。
Sakana AI 选了一条绕开算力军备竞赛的路,把重心放在怎么编排模型,而非继续堆参数。这个方向对不对,市场会给出答案。
但至少,当你的 Claude API 因为出口管制突然挂掉的时候,你会开始认真考虑:也许不该把鸡蛋放在一个篮子里。
参考来源
(注:以下仅保留国内可访问的来源)
- 暂无符合条件的国内可访问参考链接


