DeepSeek识图模式终于转正:从内测走向全量

DeepSeek 多模态研究员 Xiaokang Chen 宣布识图模式正式登陆网页和 App 端,与快速模式、专家模式并列。背后是其 4 月公开的'以视觉原语思考'技术框架。
DeepSeek 识图模式终于转正:从内测走向全量
6 月 18 日,DeepSeek 多模态研究员 Xiaokang Chen 在社交平台上扔出一句话:识图模式正式上线网页端和 App 端。没有发布会,没有预告片,甚至连一篇像样的官方博客都没有——这很 DeepSeek。
这事看着小,但拖了不短时间。从去年下半年陆陆续续有用户在 App 里看到'图片理解功能内测中'的灰度入口,到现在算是磨了大半年才正式推开。IT之家实测发现,App 端目前依然挂着'图片理解功能内测中'的提示,网页端则已经把这块尾巴去掉了——意思是网页端先转正,移动端的灰度还没完全收口。
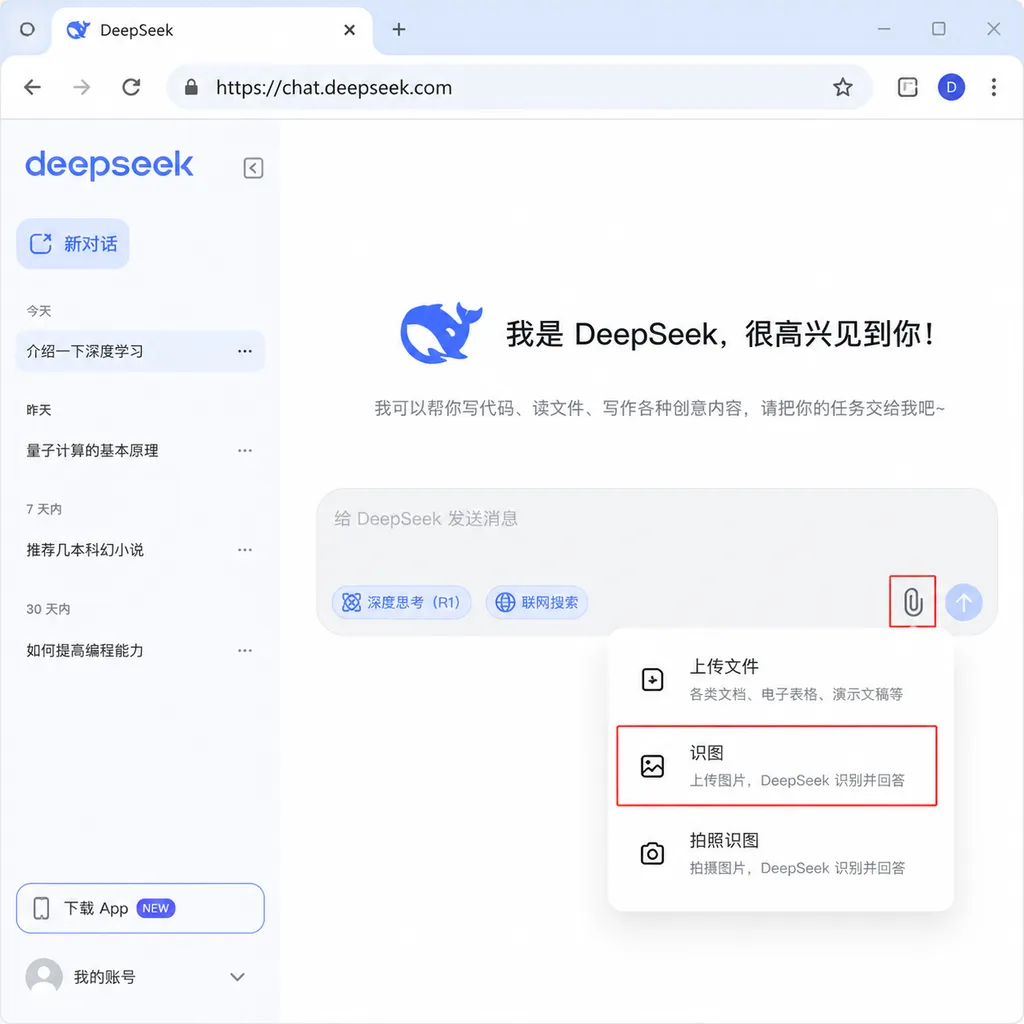
三种模式并列的产品逻辑
现在 DeepSeek 的对话框里,'识图模式'和此前已有的'快速模式''专家模式'并列摆着。这套三选一的设计其实挺有意思,跟主流厂商把多模态揉进单一对话框的做法不一样。
- 快速模式:默认的轻量对话,主打响应速度
- 专家模式:调用深度推理能力,对应的是 R1 那条线
- 识图模式:单独入口,开启后才能上传图片走多模态链路
为什么要单拆一个模式出来?OpenAI 的 GPT-4o、Anthropic 的 Claude、Google 的 Gemini 早就把视觉能力做成默认开启了,用户拖个图就能问。DeepSeek 这套显式切换的设计,多少有点反潮流。
我的猜测是两个原因。一是算力成本——视觉编码器跑起来贵,让用户主动开启可以筛掉一大批根本不需要图像理解的请求;二是模型路由,识图模式背后跑的可能根本不是同一个模型权重,而是专门的多模态版本,所以入口必须显式区分。这种做法工程上更干净,但用户教育成本会高一些。
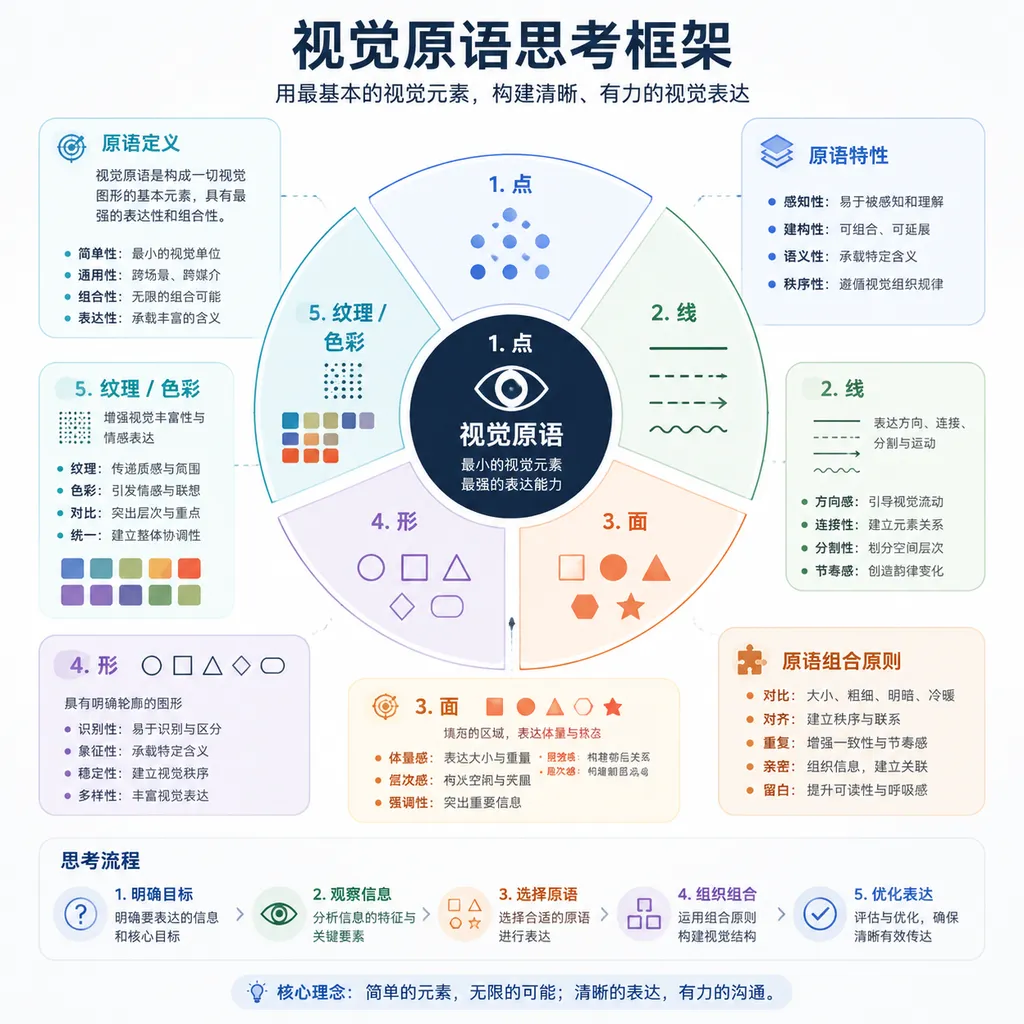
不只是 OCR:'以视觉原语思考'是什么
配合这次上线,值得回头看一眼 DeepSeek 在今年 4 月公开的技术细节。他们提出了一个叫做 Thinking with Visual Primitives(以视觉原语思考) 的核心框架。
这个名字听起来玄乎,拆开来其实是在解决一件具体的事:现有的视觉语言模型大多是'看完图、转成文字描述、然后基于文字推理'。这个流程的问题是,图像里的空间关系、几何结构、像素级细节在转译过程中会丢掉一大半。模型看着图,但'思考'用的是被压缩过的文字摘要。
视觉原语的思路是让推理过程直接在视觉表征上进行——把图像拆解成更基础的视觉单元(点、线、区域、几何关系),让模型在这些原语上做组合和推理,而不是先翻译成自然语言。简单理解,就像让人类做几何题时直接在脑子里旋转图形,而不是把图形先用文字描述一遍再思考。
这个方向其实跟 OpenAI o3 在视觉推理上做的'图像缩放、旋转、裁剪后再思考'有点异曲同工,但 DeepSeek 走得更底层一些,是从表征层面动刀。
实测一下:能做什么不能做什么
我拿几个常见场景跑了一下网页端:
手写笔记识别:一页字迹潦草的会议笔记,OCR 出来的准确率比预期高,连箭头表示的逻辑关系都识别出来了,而不是简单地把字符堆在一起。
图表理解:丢了一张折线图问数据走势,能正确读出转折点和大致数值,但具体到坐标轴刻度的精确读数会有偏差。这是当前所有视觉模型的通病。
截图调试:把一段报错的 IDE 截图丢进去,连同代码上下文一起分析,能定位到具体行和大致原因。对开发者来说这个场景实用。
复杂场景推理:上传一张物理题的电路图,让它分析电流走向。这块表现明显比纯 OCR 强一档,能结合图中元件关系给出推理路径——这大概就是'视觉原语'框架的价值。
短板也有。一是延迟,识图模式开启后首字延迟明显高于纯文本对话;二是图像生成完全不支持,DeepSeek 这次只做了理解侧,没碰生成;三是多图对比推理还比较弱,丢两张图让它找不同,效果一般。
在国内多模态战场的位置
横向比一下国内同行的进度:
- 通义千问 Qwen-VL 系列已经迭代到第三代,开源权重也放出来了,是目前国内多模态的标杆
- 智谱 GLM-4V 在 OCR 和图表理解上深耕,企业侧用得多
- Kimi 的视觉能力主打长文档+图像混合理解
- 豆包 走的是 C 端全场景
DeepSeek 这次上线的识图模式,从能力上看并没有刷新行业上限。它的优势仍然是那套熟悉的组合拳——免费、开源(如果后续放权重的话)、技术框架够新。'以视觉原语思考'这个方向如果真能跑通,对开源多模态社区的影响会比这次产品上线本身大得多。
值得注意的是,DeepSeek 这次只更新了产品,对应的多模态模型权重还没开源。考虑到他们一贯的开源节奏,权重大概率会在后面某个时间点放出来——这才是开发者真正等的东西。
对开发者意味着什么
短期来看,C 端用户多了一个免费可用的视觉理解工具,能截图问问题、能拍照解题、能让 AI 看 UI 设计稿——常规多模态能用的场景它都能接。
但对开发者来说,更值得关注的是 API 层面什么时候跟进。目前 DeepSeek 开放平台的 API 还是纯文本,识图能力没有开放调用入口。如果后续按惯例放出 vision API,配合他们一贯激进的定价,对现在用 GPT-4o vision 或 Claude vision 的应用会形成实打实的成本压力。
OpenAI Hub 这边也在持续跟进 DeepSeek 系列的更新,等视觉 API 正式开放后会第一时间接入,届时一个 Key 就能在 GPT、Claude、Gemini、DeepSeek 之间切换多模态调用,省去到处申请 Key 的折腾。
一点延伸思考
DeepSeek 这次的节奏很'DeepSeek':研究员一句话、产品悄悄上线、技术细节早几个月就低调公布过。没有营销、没有 PPT、没有融资稿。这种工程师文化在当下的 AI 圈算是清流。
但反过来说,多模态这个赛道现在卷得已经不只是模型能力。GPT-4o 的实时语音视频、Gemini 2.0 的原生多模态生成、Claude 的 Computer Use——头部玩家在视觉这条线上已经开始做交互范式的创新。DeepSeek 还在补'能看图'这个基础能力,节奏上其实是慢的。
好消息是,他们补课的方式不是简单照抄,'视觉原语'这套技术叙事如果真能在 R2 或者下一代模型上跑出效果,可能会跳过中间几代的演进路径。开源社区现在最缺的就是这种敢于在底层框架上动刀的玩家。
所以这次的识图模式上线,与其说是一个产品里程碑,不如说是 DeepSeek 多模态故事的一个起点。真正的好戏,还在后面。
参考来源
- IT之家 - DeepSeek 识图模式正式上线 App 和网页端 - 首发报道,包含 Xiaokang Chen 的原始表态和实测细节


