马斯克放话:SpaceX每月一款全新LLM,Grok 4.5对标Opus

马斯克宣布SpaceX今年每月都会发布从零训练的新模型,首发Grok 4.5基于1.5T参数V9基础模型,私测中性能接近Claude Opus。但在预训练团队大规模出走、Colossus 1算力被卖给Anthropic的背景下,这个节奏更像是一场背水一战。
一个月一个新模型,这话从马斯克嘴里说出来
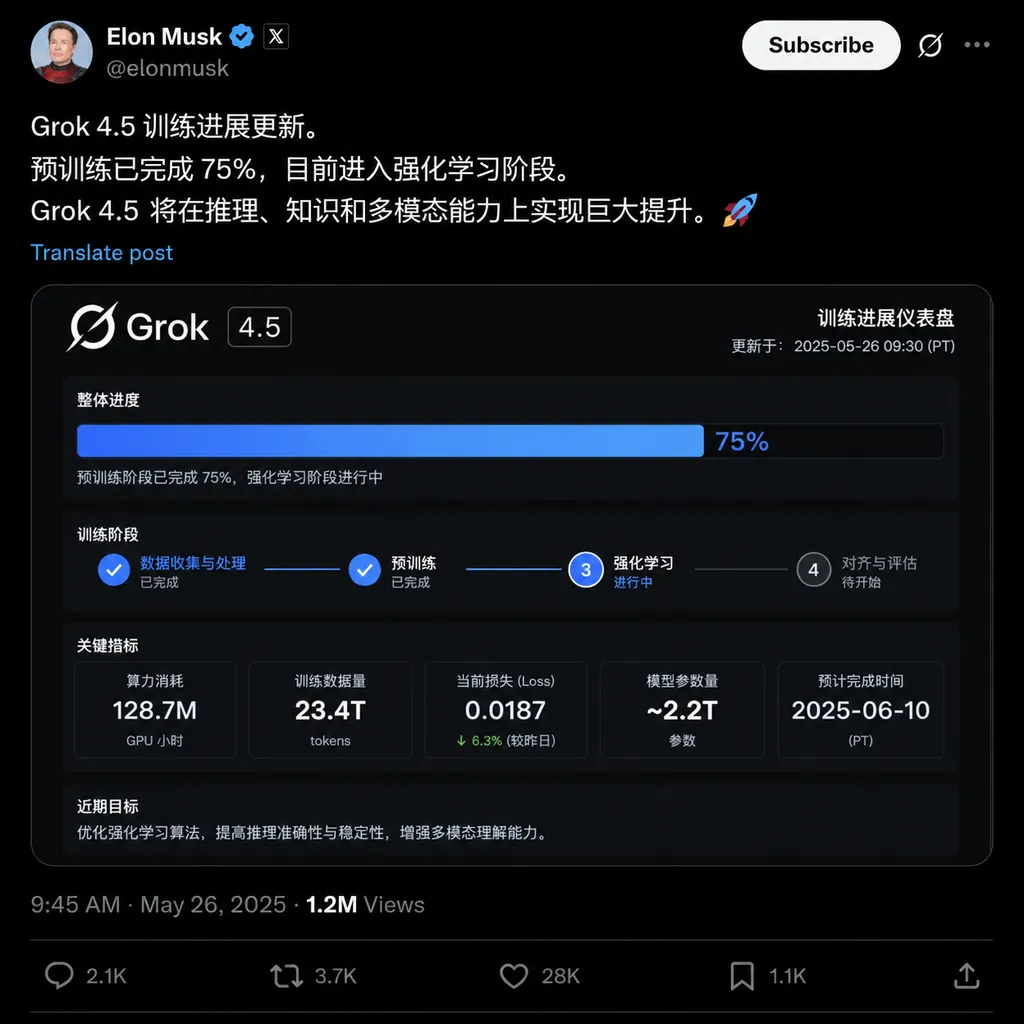
6月底,马斯克在 X 上扔下一句话:今年 SpaceX 每个月都会发布一款从零训练的新 LLM。配套放出的还有 Grok 4.5 的早期信息——基于 1.5T 参数的 V9 基础模型,补充训练阶段塞进了 Cursor 的数据,目前在 SpaceX 和特斯拉内部私测,早期评估"性能接近、甚至可能超过 Opus"。
听上去很猛。但任何熟悉过去两个月这家公司动态的人,听到这句话的第一反应大概率是:你这节奏,撑得住吗?
先把背景捋一遍
要看懂"每月一款新模型"这句话的分量,得回到 5 月。
5 月 6 日,xAI 正式并入 SpaceX,更名 SpaceXAI。一家成立不到三年、估值一度冲到 2000 亿美元的 AI 独角兽,就这么消失在了组织架构图上。
5 月 7 日,Anthropic 和 SpaceX 联合发公告,Colossus 1 整套算力——孟菲斯数据中心、22 万张 GPU、300+ 兆瓦——全部租给 Anthropic,用来训练 Claude Opus 4.7。这事当时在社区炸了锅,因为 Colossus 1 是 xAI 过去两年砸钱堆出来的命根子。
5 月 8 日,马斯克发推反驳"Grok 已死"的论调,强调 Colossus 2 正在同时训练多款新 Grok,并且"Built harness 开发顺利"。注意他强调的是 Colossus 2,不是 1——因为 1 已经不归他用了。
5 月中旬,更扎心的消息出来:超过 50 名 xAI 研发人员在并购后离职,其中包括预训练团队的核心成员。这个团队是干什么的不用多解释,它直接决定一个 LLM 的底层能力上限。一家 AI 公司可以丢销售、丢市场、甚至丢推理优化团队,但预训练团队走人,相当于发动机被卸了。
所以现在这条"每月发布一款从零训练新模型"的承诺,是在以下条件下做出的:
- 预训练核心团队大规模出走
- Colossus 1 算力让出去了
- Colossus 2 的 Blackwell 集群还在爬坡部署
- 内部 MFU(模型算力利用率)此前被爆有人为造数据的问题
这个时间点放这种话,要么是真的有底,要么是必须这么说。
Grok 4.5:1.5T 参数、V9 基座、Cursor 数据
抛开背景看模型本身,Grok 4.5 的几个细节值得拆一下。
1.5T 参数的 V9 基础模型。这个规模放在 2026 年其实不算特别夸张——GPT-5.5、Gemini 3.1 Pro、Opus 4.7 都在万亿参数量级。但 V9 这个编号意味着 xAI/SpaceXAI 的预训练流水线确实没停。从 Grok 1 到 Grok 4,外界能看到的版本号是 1-4,但内部基础模型已经迭代到 V9,说明基座层面一直在跑,只是大部分没对外发布。
补充训练用了 Cursor 数据。这一条特别值得说。Cursor 是当下开发者最常用的 AI 编程工具之一,背后大量调用 Claude 和 GPT 系列。把 Cursor 的使用数据放进 post-training,目的非常明确——冲编程能力。
过去 Grok 系列最大的短板就是开发者市场。Claude Opus 在 SWE-bench Verified 上拿到 80.8%,驱动着 Cursor、Windsurf、Claude Code 这一整条工具链;Gemini 3.1 Pro 在 GPQA 上是 94.3%。Grok 一直在追,但始终没能在企业和开发者场景里站住脚。这次拿 Cursor 数据做补训,是直接奔着 Opus 的腹地去的。
"接近、甚至可能超过 Opus"。这种说法在马斯克的话术体系里需要打折看。但即便打个七折,能在私测阶段把 Opus 放进对标参照系,至少说明内部跑出来的 benchmark 不算难看。
"每月一款"在工程上意味着什么
这才是最值得讨论的部分。
一款 1.5T 参数级别的模型,从零开始预训练,行业内普遍的时间窗口是 2-4 个月,这还是建立在数据管线、训练框架、调度系统都成熟的前提下。GPT-4 训练用了大约 3 个月,Claude Opus 4 系列据传超过 4 个月。
要做到"每月一款从零训练",只有几种可能:
- 大幅缩小参数规模。比如把基座做到 300-500B 级别,配合高质量数据和 MoE 架构,一个月内确实能跑完一轮。
- 并行多条训练管线。同一时间在 Colossus 2 上跑多个模型,按月轮流发布。这种做法对调度系统要求极高。
- "从零训练"的定义被放宽。比如重置 checkpoint 但复用部分数据预处理结果,或者从一个 base 模型分叉做大规模 continue pretraining。
以马斯克过去的风格来看,三种可能都存在。但更现实的判断是第二种——Colossus 2 部署到一定规模后,把它当作多模型流水线来用。
这里有个绕不开的问题:MFU。
之前媒体报道过 xAI 内部研究员故意重复跑同一个训练实验来拉高 MFU 数字。如果 Colossus 2 实际运行效率仍然只在 11-15% 这个区间,那么再多 GPU 也救不了。一个利用率 45% 的 10 万卡集群,等效产能可能比一个利用率 12% 的 30 万卡集群还高。
这道坎不是硬件能解决的。要解决,需要的是网络协议、调度系统、训练框架层面的工程能力,而这恰恰是预训练团队走掉之后最难补的部分。

同行在做什么
横向看一眼竞品,能更清楚 Grok 4.5 这个时间点的尴尬。
- Claude Opus 4.7:刚拿下 Colossus 1 的算力做训练,6 月已经在 Cursor 上铺开。
- GPT-5.5:OpenAI 的训练算力已经全面切到 Blackwell,按 OpenAI 一贯的节奏,下半年会有大动作。
- Gemini 3.1 Pro:在 GPQA 上拿到 94.3%,Google 内部的 TPU v6 集群效率持续优化。
- DeepSeek、Qwen 系列:开源阵营继续高频迭代,国内开发者生态已经成型。
Grok 在这种格局下要靠"月更"突围,逻辑上能成立的路径只有一条——用发布频率来制造存在感,然后用某一两个版本真正打穿一个细分场景(比如代码或者实时信息)。这跟 SpaceX 早期"快速迭代、容忍失败"的火箭研发哲学一脉相承。
但问题在于,火箭炸了可以再造一发,模型发了砸了在开发者圈里的口碑回不来。Grok 1 到 Grok 4 一路走下来,benchmark 上有追赶,但企业和开发者市场没拿下,根本原因不是模型不够多,而是没有一款真正让人觉得"非用不可"。
几个值得继续观察的信号
如果"每月一款"真的执行起来,接下来这几个信号最值得盯:
- 首月发布的 Grok 4.5 上下文窗口和工具调用能力。如果只是 benchmark 数字好看,但 agent 场景表现一般,意味着补训数据只是"刷题"。
- Cursor 是否会正式接入 Grok。这是检验 Grok 4.5 编程能力是否真过关的硬指标。Cursor 自己在用什么模型,开发者用脚投票。
- 第二个月、第三个月的模型有没有差异化。如果连续几款都是同一基座的微调变种,"从零训练"这个说法就站不住。
- MFU 数据是否公开。这一条最关键,关系到 SpaceXAI 的工程底子。
- 预训练团队的补员速度。50 多人离职后,谁来接手 V10、V11 基座的研发。
写在最后
马斯克的承诺总是要打折听,这是过去十几年市场达成的共识。但"每月一款从零训练的 LLM"这种话即便打到三折,也意味着 SpaceXAI 在算力分配、训练管线、数据流转上的投入会是行业前列。
更重要的是,这反映出一个事实:即便在并购、人员震荡、算力出让之后,马斯克并没有打算退出 LLM 这场牌桌。Colossus 1 折现给了 Anthropic,那是为了把账面亏损消化掉;Colossus 2 押在 Blackwell 上,是真金白银地继续下注。
对开发者来说,这件事的实际影响要等几个月才能看出来。如果 Grok 4.5 真能在某些场景里追平 Opus,那对整个 API 调用市场都是好消息——多一个高水位选项,议价空间就多一分。
OpenAI Hub 这边会持续跟进 Grok 4.5 的公开发布节点。等模型正式开放 API,会第一时间接入聚合调用,到时候你可以在同一个 Key 下直接对比 Grok 4.5、Opus 4.7、GPT-5.5 在自己业务场景里的真实表现,这比看任何 benchmark 都靠谱。
模型多了不是坏事,关键是看谁能把"多"变成"好"。
参考来源
- 马斯克称今年 Space X 每个月都会发布从头训练的新模型 - linux.do - 马斯克原帖讨论及 Grok 4.5 早期信息


