Gemini 能直接生成3D模型了,大模型卷进可视化战场

Google 为 Gemini 推出交互式 3D 模型与物理模拟生成功能,用户可在对话中直接获得可旋转、可调参的三维可视化场景,大模型厂商在「可视化回答」赛道的竞争全面升级。
Google 这次没搞预告,直接把功能上线了——Gemini 现在可以在对话中生成可交互的 3D 模型和物理模拟场景。不是静态图片,不是 Markdown 表格,是真正能拖动旋转、缩放细节、用滑块调参数的三维可视化。
说直白点:你问它「月球怎么绕地球转」,它不再只是甩你一段文字,而是直接渲染出一个三维轨道模型,你可以拽着月球看、拉滑块改公转速度、开关轨迹线显示,甚至暂停整个动画逐帧观察。
这件事值得认真聊聊。
它到底能做什么
根据 Google 的介绍和实际体验反馈,这次升级的核心能力可以拆成三层:
第一层是 3D 模型生成。Gemini 能根据自然语言描述,直接输出一个三维模型。不是调用外部建模工具的 API,而是在对话界面内原生渲染。模型支持标准的三维交互——旋转、缩放、平移,和你在任何 3D 查看器里的操作体验一致。
第二层是物理模拟。这才是真正有意思的部分。Gemini 不只是画一个静态的 3D 物体,它能生成带时间轴的动态模拟。双摆系统的混沌运动、多普勒效应的波形变化、行星轨道的周期运动——这些涉及物理过程的场景,它都能跑起来。
第三层是参数交互。生成的可视化不是「只能看」的动画,而是带控制面板的。滑块调速度、输入框改数值、开关切显示元素,用户可以实时修改参数并观察结果变化。这本质上已经不是「回答」了,更像是一个按需生成的微型仿真应用。
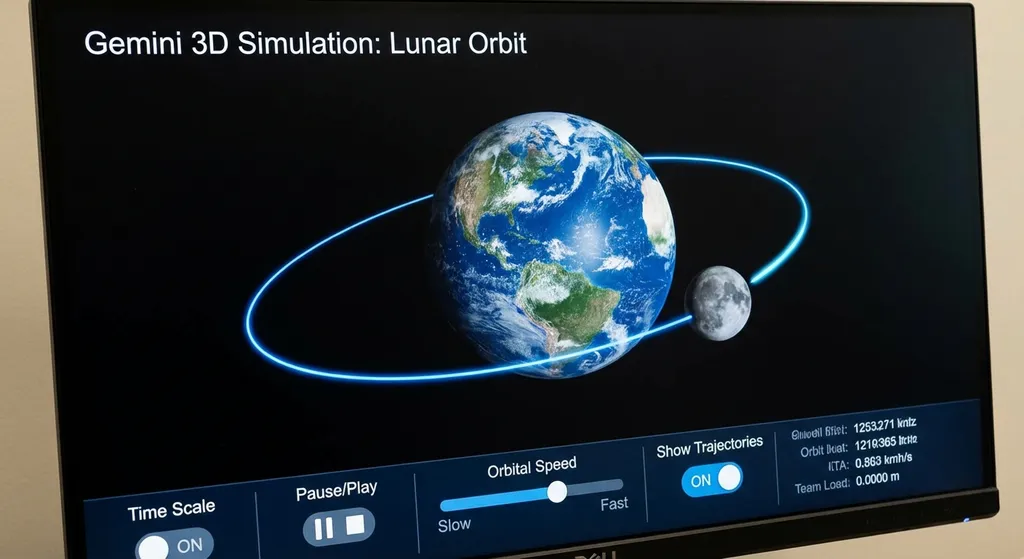
怎么用
操作路径不复杂,但有个前提——你需要在 Gemini 应用中把模型切换到 Pro。
具体流程:
- 打开 Gemini 应用,将模型切换为 Pro
- 用自然语言提出可视化请求,比如「展示一个双摆系统」「帮我可视化多普勒效应」「生成一个月球绕地球公转的模拟」
- Gemini 先返回文字说明
- 界面下方出现「Show me the visualization」按钮
- 点击后生成对应的 3D 模型或模拟场景
注意第 4 步——它不是自动生成 3D 的,而是先给文字答案,再由用户主动触发可视化。这个设计挺聪明:不是所有问题都需要 3D,让用户自己决定要不要「看见」答案,避免了不必要的渲染开销和等待时间。
目前这个功能对所有 Gemini 应用用户开放,不需要额外付费,选 Pro 模型就行。
从 2D 到 3D,Gemini 的可视化路径
这次升级不是凭空冒出来的。往回看,Gemini 的可视化能力一直在迭代:
最早,Gemini 和其他大模型一样,回答就是纯文本。后来加入了代码执行能力,可以跑 Python 画 Matplotlib 图表——但那本质上还是「生成代码然后执行」,不是原生的可视化能力。
再后来,Gemini 支持了根据用户提示生成可交互的平面图像。你可以点击、拖动,但交互维度局限在 2D 平面上。
现在这一步,直接跳到了 3D 模型和动态物理模拟。维度升了,交互深度也升了。从「看图」变成了「玩模型」。
如果把这条路径画出来,大概是:
纯文本 → 代码生成图表 → 可交互 2D 图像 → 可交互 3D 模型 + 物理模拟
每一步的跨度都不小。尤其最后这一步,从 2D 到 3D 不只是多了一个维度,背后涉及的渲染管线、物理引擎集成、实时交互框架都是完全不同的技术栈。
技术上怎么实现的?
Google 没有公开完整的技术细节,但从已有信息和实际表现可以做一些合理推断。
Gemini 大概率不是在服务端跑一个完整的 3D 渲染引擎然后把画面串流给客户端——那样延迟和带宽成本都不现实。更可能的方案是:模型生成一段描述 3D 场景的结构化数据(类似 glTF、USD 或者某种内部 DSL),然后由客户端的 WebGL/WebGPU 渲染器负责实时渲染和交互。
物理模拟部分也类似。Gemini 不太可能在推理时实时计算每一帧的物理状态,更合理的做法是生成物理模拟的参数和规则定义,然后交给客户端的物理引擎(比如基于 cannon.js 或 ammo.js 的轻量方案)去跑。
换句话说,Gemini 的角色更像是一个「场景编排者」——它理解你的需求,生成场景描述和交互逻辑,然后把渲染和模拟的脏活交给客户端。这和传统的「AI 生成代码 → 用户自己跑」的模式有本质区别:用户不需要看到任何代码,整个过程是无缝的。
从补充资料来看,Google 还在探索将这套能力延伸到 XR 领域。配合三星 Galaxy XR 头显和 Gemini 3 Pro,用户可以用自然语言生成沉浸式 3D 交互体验,甚至支持手势追踪操控。这说明 Google 对这条路径的投入不是浅尝辄止,而是有一个从屏幕到空间计算的完整规划。
大模型的「可视化回答」军备竞赛
把视角拉远一点看,Gemini 这次更新不是孤立事件,而是大模型厂商在「可视化回答」赛道上集体加速的一个缩影。
Anthropic 不久前给 Claude 加了自动生成图表、示意图和交互式可视化内容的能力。你问 Claude 一个数据分析问题,它可以直接给你画出交互式图表,而不是让你自己拿数据去 Excel 里折腾。
OpenAI 也没闲着,ChatGPT 已经上线了针对数学和科学概念的可视化工具。函数图像、几何关系、物理过程,都可以在对话中直接呈现。
三家的路径各有侧重:
- OpenAI 偏向数学和科学教育场景,可视化更像是「智能黑板」
- Anthropic 偏向数据分析和商业场景,可视化更像是「智能仪表盘」
- Google 这次直接上了 3D 和物理模拟,野心最大,场景也最广
但本质上,大家在做同一件事:让大模型的输出从「纯文本」进化到「多模态富交互」。文字是信息密度最高的表达方式,但不是所有信息都适合用文字传递。一个双摆系统的混沌运动,你用文字描述一万字不如让人亲手拨一下。
这背后有一个更深层的趋势:大模型正在从「回答问题的工具」变成「构建体验的平台」。它不只是告诉你答案,而是帮你创造一个理解答案的环境。
对开发者意味着什么
如果你是做教育、科研可视化、数据展示相关产品的开发者,这个功能值得重点关注。
首先是能力边界的变化。以前要做一个交互式 3D 物理模拟,你需要 Three.js + 物理引擎 + 一堆前端工程化的活儿,一个有经验的前端可能要搞一两天。现在 Gemini 用一句话就能生成一个可用的版本。当然,生成的质量和定制化程度肯定比不上手写,但作为快速原型或教学演示,已经够用了。
其次是交互范式的变化。当用户习惯了「问一句话就能得到一个可交互的 3D 场景」之后,他们对你产品中静态图表和文字说明的容忍度会急剧下降。这不是危言耸听——想想 ChatGPT 出来之后,用户对传统搜索引擎的耐心下降了多少。
对于通过 API 调用 Gemini 的开发者来说,目前这个 3D 可视化功能还局限在 Gemini 应用端,API 层面暂时没有直接暴露对应的能力。但 Gemini 的文本生成、多模态理解等核心能力,通过 API 已经可以充分利用。
如果你在项目中需要调用 Gemini 或其他主流模型的 API,可以通过 OpenAI Hub 用统一的 OpenAI 兼容格式接入,省去对接多家 API 的麻烦。比如调用 Gemini 模型生成内容:
import openai
client = openai.OpenAI(
api_key="your-openai-hub-key",
base_url="https://api.openai-hub.com/v1"
)
response = client.chat.completions.create(
model="gemini-pro",
messages=[
{"role": "user", "content": "解释双摆系统的混沌运动原理,并给出关键参数的数学表达"}
]
)
print(response.choices[0].message.content)
// Node.js 示例
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'your-openai-hub-key',
baseURL: 'https://api.openai-hub.com/v1',
});
const response = await client.chat.completions.create({
model: 'gemini-pro',
messages: [
{ role: 'user', content: '描述多普勒效应的物理过程,给出频率变化的公式推导' }
],
});
console.log(response.choices[0].message.content);
同样的代码结构,把 model 换成 gpt-4o、claude-sonnet-4 或 deepseek-chat 就能切换到其他模型,接口格式完全一致。在做模型效果对比或者多模型 fallback 的时候,这种统一接入的方式能省不少事。
冷静看几个问题
功能是好功能,但有几个点需要保持清醒。
第一,生成质量的上限在哪?月球绕地球转、双摆系统这些经典物理场景,模型训练数据里有大量参考,生成效果自然不错。但如果你问一个非标准的、需要领域知识的模拟——比如「模拟一个特定晶体结构的声子色散关系」——它还能不能搞定?大概率会打折扣。
第二,交互的深度够不够?从目前的演示来看,交互主要是旋转、缩放、滑块调参这些基础操作。如果用户想做更复杂的交互——比如在模拟中添加新的物体、修改物理规则、导出模型数据——目前看起来还不支持。它更像是一个「只读 + 调参」的可视化,而不是一个完整的建模工具。
第三,性能和兼容性。3D 渲染对客户端硬件有要求,在低端设备或老旧浏览器上的体验可能会大打折扣。Google 在这方面的优化做得怎么样,还需要更多用户的实际反馈。
第四,也是最根本的——这个功能的使用频率会有多高?对于学生和教育工作者,交互式 3D 模拟确实是刚需。但对于大多数普通用户,日常对话中需要 3D 可视化的场景其实不多。这个功能更可能是一个「低频但高价值」的能力,而不是一个改变日常使用习惯的功能。
往前看
抛开具体功能不谈,这次更新释放了一个清晰的信号:大模型的输出形态正在快速多元化。
从纯文本到图片,从图片到代码执行,从代码执行到交互式 2D,再到现在的交互式 3D 和物理模拟。下一步是什么?结合 Google 在 XR 方向的布局,空间计算和沉浸式交互几乎是确定的方向。
对开发者来说,这意味着「AI 能帮你做什么」的边界还在快速扩张。今天它能生成一个 3D 物理模拟,明天可能就能生成一个完整的交互式应用原型。保持关注,保持手感,在这些能力真正成熟并开放 API 的时候,第一时间把它们集成到自己的产品里——这大概是当下最务实的策略。
参考来源:
- Google Gemini 推出可生成交互式3D模型和模拟的新功能 - Linux.do — 功能发布详情与实际体验报告
