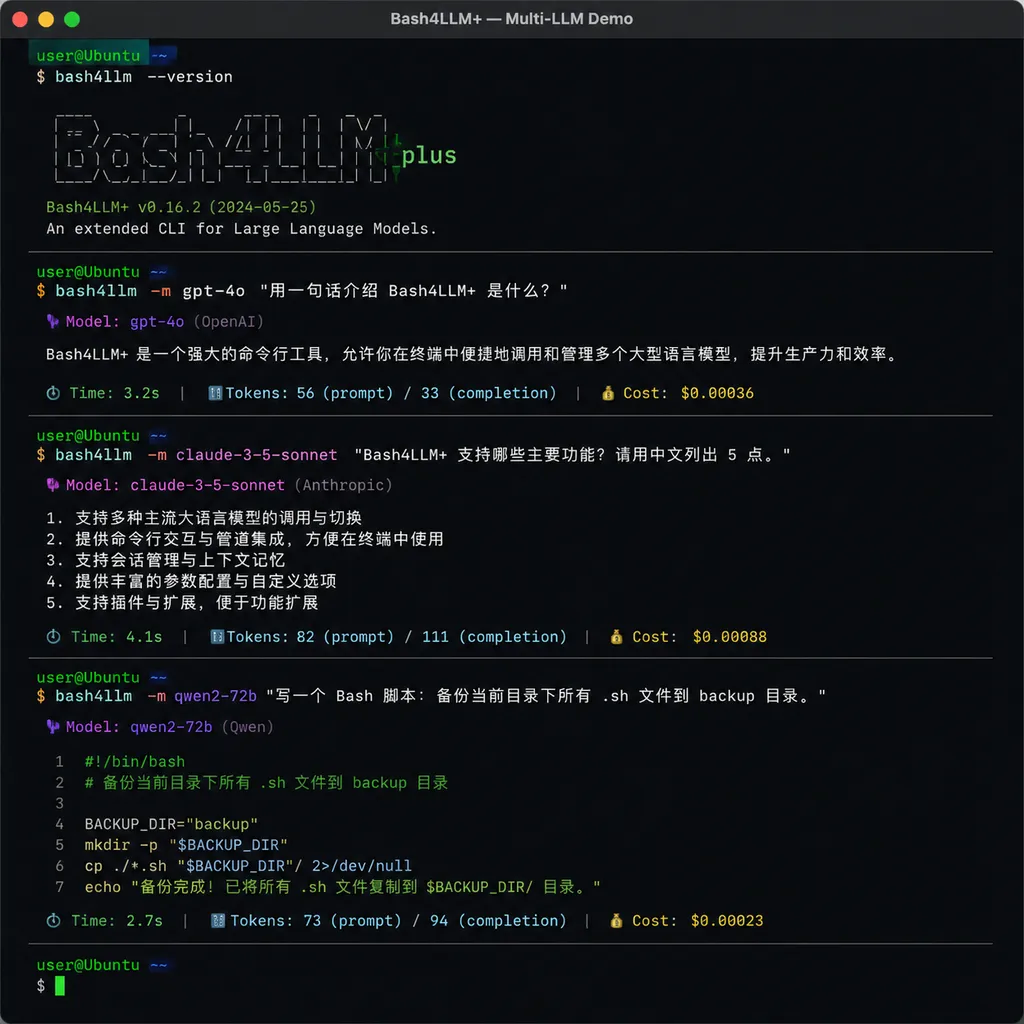
Bash4LLM+:500 行 Bash 把所有 LLM API 串起来

一个零依赖的纯 Bash 脚本,用 curl 和 jq 就能调通 OpenAI、Claude、Gemini、DeepSeek 等主流 LLM API,适合服务器、容器和受限环境下的轻量级 AI 工作流。
当所有人都在写 Python SDK 时,有人用 Bash 把活干了
Hacker News 上最近冒出来一个项目叫 Bash4LLM+,作者 kamaludu 把它定义为「a lightweight, dependency-free Bash wrapper for LLM APIs」。一句话总结:你不需要装 Python,不需要 pip install 一堆东西,甚至不需要 Node.js,只要系统里有 bash、curl 和 jq,就能在终端里调 GPT、Claude、Gemini、DeepSeek、Qwen 这些主流模型。
这听起来有点反潮流。现在大家做 LLM 工具链恨不得把 LangChain、LlamaIndex、各种 Agent 框架全堆上去,动辄几百兆的依赖树。而 Bash4LLM+ 反其道而行之——整个项目核心就是几个 Shell 脚本,加起来不到一千行代码。
但仔细想想,这个定位其实非常聪明。Shell 是 Unix 系统的最大公约数,无论你是 SSH 到一台只装了 BusyBox 的边缘设备、在 Docker 容器里跑个 init 脚本、还是想给 CI/CD pipeline 加点 AI 能力,Bash 都是最不可能掉链子的那一层。
它到底解决了什么问题
做过运维或者写过自动化脚本的人都遇到过这种场景:想在某个 Shell 脚本里加一句「让大模型帮我判断一下这个日志是不是异常」,结果发现要么得起个 Python 子进程,要么得用 curl 手撸一长串 JSON,处理流式响应、错误重试、不同厂商的鉴权头还各不一样。
Bash4LLM+ 把这些苦活脏活全包圆了。它的设计思路非常直接——抽象出一个统一的命令行接口,背后通过适配器对接不同厂商的 API。你在脚本里写:
bash4llm chat --provider openai --model gpt-5.2 "分析这段日志的异常原因"
bash4llm chat --provider anthropic --model claude-sonnet-4.5 "同样的问题"
bash4llm chat --provider deepseek --model deepseek-v3.2 "再问一遍"
切换模型只需要改 --provider 和 --model 两个参数,鉴权、请求体格式、响应解析全部由脚本内部完成。
这种「跨厂商抽象」其实不新鲜,LiteLLM、OpenRouter 这些项目早就在做。但 Bash4LLM+ 的差异化在于——它不引入运行时。LiteLLM 是 Python 库,你得有 Python 环境;OpenRouter 是托管服务,你得走它的代理。而 Bash4LLM+ 就是几个 .sh 文件,clone 下来 chmod +x 就能用,连配置文件都是简单的 KV 格式。
技术实现:用 jq 把 JSON 处理玩明白了
翻了一下源码,作者的实现思路有几个值得说道的点。
第一是请求构造。 不同厂商的 API 格式差异其实挺大:OpenAI 用 messages 数组、role/content 结构;Anthropic 早期版本要 system 单独传、messages 里不能有 system;Gemini 又是另一套 contents/parts 的嵌套结构。Bash4LLM+ 的做法是把用户输入的 prompt 统一标准化后,针对每个 provider 用 jq 模板拼出对应的 payload。
类似这样的逻辑(简化版):
build_openai_payload() {
jq -n \
--arg model "$MODEL" \
--arg prompt "$PROMPT" \
'{
model: $model,
messages: [{role: "user", content: $prompt}],
stream: true
}'
}
jq 在这里承担了「JSON 模板引擎」的角色,比手撸字符串拼接安全得多——不用担心 prompt 里有引号、换行、Unicode 字符把 JSON 搞坏。
第二是流式响应处理。 SSE(Server-Sent Events)格式本质上就是一行行 data: {...},Bash4LLM+ 用 curl --no-buffer 配合 while read line 逐行读取,每读到一行就用 jq -r 抽出 delta.content 字段直接 echo 出来。这种写法在 Shell 里出奇地优雅,比 Python 里要起 async loop 写 generator 简洁得多。
第三是配置管理。 项目用 ~/.bash4llm/config 存 API key 和默认参数,格式就是简单的 KEY=VALUE,通过 source 命令加载。没有 YAML,没有 TOML,没有 JSON schema——但够用。
它适合谁,不适合谁
说说我的判断。
适合的场景:
- 服务器侧自动化。比如你想给 Nagios 或 Prometheus 告警加个 AI 总结层,或者在 cron 任务里让模型分析昨天的访问日志。这种场景下你不想为了一个 API 调用就背一整个 Python 虚拟环境的包袱。
- 容器初始化脚本。Dockerfile 里
RUN一句话调 LLM 生成配置,比起pip install openai要快几个数量级。 - CI/CD 集成。GitHub Actions、GitLab CI 的 runner 默认都有 bash 和 curl,加这么个脚本基本零成本。
- 嵌入式/边缘设备。OpenWrt 路由器、树莓派这种地方,Python 都嫌重。
- 学习用途。想搞清楚各家 LLM API 协议到底长啥样,读这个项目的源码比读 SDK 文档直接得多。
不适合的场景:
- 复杂的 Agent 工作流。涉及到工具调用、状态管理、多步推理的场景,Bash 的表达能力还是太弱,老老实实用 Python 或者 TypeScript。
- 需要严格类型安全的生产系统。Shell 脚本的错误处理是出了名的脆弱,
set -euo pipefail也救不了所有场景。 - 多模态。图片、音频的 base64 编码和上传在 Bash 里写起来非常痛苦,虽然不是做不到。
和同类项目的对比
这两年 Shell + LLM 这个赛道其实挺热闹。有几个值得对比的项目:
- Simon Willison 的 llm CLI:功能丰富,插件生态好,但本质是 Python 工具,要装。
- shell_gpt (sgpt):定位是「终端里的 ChatGPT」,更偏交互式使用,也是 Python。
- mods (charmbracelet):Go 写的,单二进制,体验很好,但要下载对应平台的二进制。
Bash4LLM+ 在这堆里属于「最极端的轻量派」。它的胜负手就是零依赖——只要你能 SSH 进一台机器、能跑 curl,你就能用。
一个实战例子:日志异常检测
举个具体场景。假设你有一台服务器,想每小时让 LLM 扫一眼 nginx 错误日志,发现异常就发企微通知。
用 Bash4LLM+ 大概是这样:
#!/bin/bash
set -euo pipefail
LOG_FILE="/var/log/nginx/error.log"
RECENT_LOGS=$(tail -n 200 "$LOG_FILE")
ANALYSIS=$(bash4llm chat \
--provider deepseek \
--model deepseek-v3.2 \
--system "你是一个运维专家,分析以下 nginx 错误日志,只在发现真正的异常时输出'ALERT:'开头的简短描述,否则只输出'OK'。" \
"$RECENT_LOGS")
if [[ "$ANALYSIS" == ALERT:* ]]; then
curl -X POST "$WECOM_WEBHOOK" \
-H "Content-Type: application/json" \
-d "$(jq -n --arg msg "$ANALYSIS" '{msgtype:"text", text:{content:$msg}}')"
fi
整个脚本不到 20 行,丢到 crontab 里就能跑。如果用 Python,光是处理 venv 和依赖就够你折腾一会儿。
一些值得注意的坑
虽然项目设计精巧,但 Bash 终归是 Bash,有些先天问题绕不开:
- 错误处理脆弱。如果 API 返回 4xx/5xx,脚本默认会把错误 JSON 打到 stdout,需要使用者自己判断返回内容。生产环境用的话建议自己包一层。
- 并发能力弱。Bash 没有原生的并发模型,想批量调用得用
xargs -P或者&+wait,调度不够灵活。 - 跨平台兼容性。macOS 自带的是 bash 3.2(古董版本),有些语法(关联数组、
mapfile)用不了。作者声明支持 bash 4+,Mac 用户最好用 brew 装新版。 - API key 安全。配置文件明文存 key,没有 keychain 集成。在共享服务器上要注意权限。
一个更大的趋势
Bash4LLM+ 这种项目的出现,其实反映了一个趋势:LLM 正在从「应用层 API」下沉为「基础设施原语」。
过去两年大家做 LLM 集成,思路都是「在应用里加 AI 能力」——SDK、框架、Agent。但当模型推理变得足够便宜、API 变得足够稳定之后,下一步就是让它像 grep、sed、awk 一样,成为 Shell 工具链的一部分。你应该能在管道里随手用:
cat error.log | llm "找出最严重的 3 个问题" | mail -s "日报" admin@example.com
这种「Unix 哲学 + LLM」的组合,可能比任何花哨的 Agent 框架都更长寿。Bash4LLM+ 算是这个方向上一个非常干净的实现。
顺便一提,如果你想用一个 Key 同时接 OpenAI、Anthropic、Google、DeepSeek 这些模型,又不想分别去各家申请账号、处理国内访问问题,OpenAI Hub 这类聚合平台和 Bash4LLM+ 配合起来挺顺手——把 base URL 指过去就行,Bash4LLM+ 的 provider 配置改两行就能跑。
总结
Bash4LLM+ 不是要取代任何现有的 LLM 工具。它的价值在于填补了「轻量级 Shell 集成」这个生态位——当你只需要让一段 Shell 脚本能调一下大模型,又不想引入任何额外运行时的时候,它是目前最干净的选择之一。
推荐运维、SRE、以及任何写自动化脚本时常常想「这里要是能调一下 AI 就好了」的开发者去看看。即使最终不用,读一遍源码也能学到不少 Shell + curl + jq 处理 LLM API 的实战技巧。
参考来源
- Bash4LLM+ GitHub 仓库 — 项目主页,包含完整源码、安装说明和使用示例
- awesome-LLM-resources — LLM 相关工具和资源的综合索引,可以找到更多类似的轻量级工具


