Modal推Auto Endpoints:把推理优化塞进一行命令

Modal 上线 Auto Endpoints,开发者一行 CLI 即可部署经过生产级调优的开源模型推理服务,speculative decoding、引擎补丁、单副本指标全部开放,主打"你自己拥有的推理"。
一行命令,把别人调了几个月的推理参数拿来用
Modal 这两天甩出了一个叫 Auto Endpoints 的新东西。简单讲,就是把 vLLM / SGLang 那一套生产级推理调优,包括 speculative decoding、量化、引擎补丁、KV cache 配置,全部封装到一条 CLI 命令背后——你只管 modal endpoint create,剩下的活它替你干了。
看起来像是又一个"开箱即用推理服务",但仔细看会发现 Modal 这次的姿势和 Together、Fireworks、Replicate 那些托管 API 不太一样:它把这些通常被托管商藏在黑盒里的东西暴露给你,让你自己拥有整个推理栈。官方那句话挺有意思——"Inference you actually own"。在 2026 年这个节点,开源模型质量已经追平闭源、但自己部署依然劝退一大批团队的当下,这是个值得聊的产品定位。
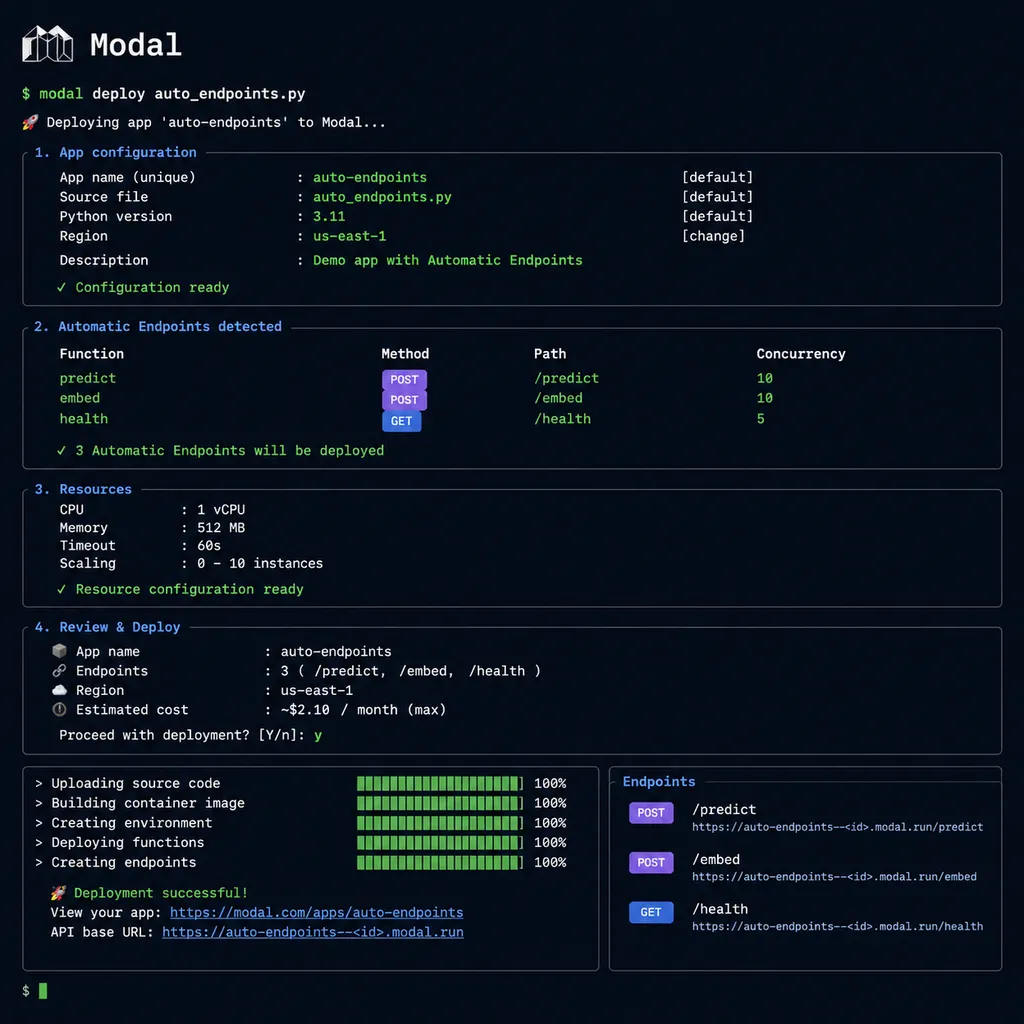
一条命令是怎么回事
用过 Modal 的人对它的 Python SDK 那套 decorator 不陌生。Auto Endpoints 把这层抽象再往上提了一级,直接做成 CLI 子命令:
# 部署 Kimi K2.6 的 NVFP4 量化版
modal endpoint create kimi-k2-6-nvfp4 \
--model nvidia/Kimi-K2.6-NVFP4
# 部署 Qwen3.6 35B A3B(MoE 激活 3B)
modal endpoint create qwen3-6-35b-a3b \
--model Qwen/Qwen3.6-35B-A3B
# 部署 Gemma 4 E4B IT
modal endpoint create gemma-4-e4b-it \
--model google/gemma-4-E4B-it
执行完,你拿到的是一个 OpenAI 兼容的 HTTPS 端点,背后是 Modal 调好的 vLLM 引擎、按你流量自动扩缩容的 H100/H200/B200 GPU 池、以及一份单副本级别的指标面板。
模型库覆盖目前主流的开源选手——NVIDIA Nemotron 3 Super 120B A12B NVFP4、GPT-OSS 120B、Qwen3.5 397B A17B FP8、Gemma 4 系列、Kimi K2.6 NVFP4,新模型上线后基本能在几天内进 catalog。当然,也可以从 Hugging Face 直接拉自己的权重,或者挂载 Modal Volume 里的私有权重。
真正值得说的是它"暴露"了什么
如果只是"一行命令部署开源模型",这赛道挤得不行。Auto Endpoints 真正不一样的地方在于:它把通常托管商不会让你碰的旋钮全部交出来了。
Speculative decoding 可配置
speculative decoding(推测解码)这两年是开源推理性能的一个大杀器——用一个小的 draft model 先猜几个 token,大模型只做验证,吞吐能拉到 1.5-3 倍。但它对模型对、temperature、acceptance rate 的敏感度极高,调不好反而更慢。
大多数托管 API 要么不开,要么默认开了你也不知道、不能换 draft model。Auto Endpoints 直接把 draft model 选择、verify 策略、回退逻辑暴露成端点配置,你可以针对自己的业务负载(比如代码补全 vs 长文生成)单独调一套出来。
引擎补丁不是黑盒
Modal 在 vLLM / SGLang 上有一堆自己打的补丁——这点他们一直没藏着,GitHub 上都是公开的。Auto Endpoints 的做法是:你可以选择跑官方版本,也可以跑带 Modal 补丁的版本,甚至可以叠自己的 patch。对那些已经在 vLLM 上做过深度定制的团队,这点很关键,因为换一个托管商通常意味着你那些 patch 要重写一遍。
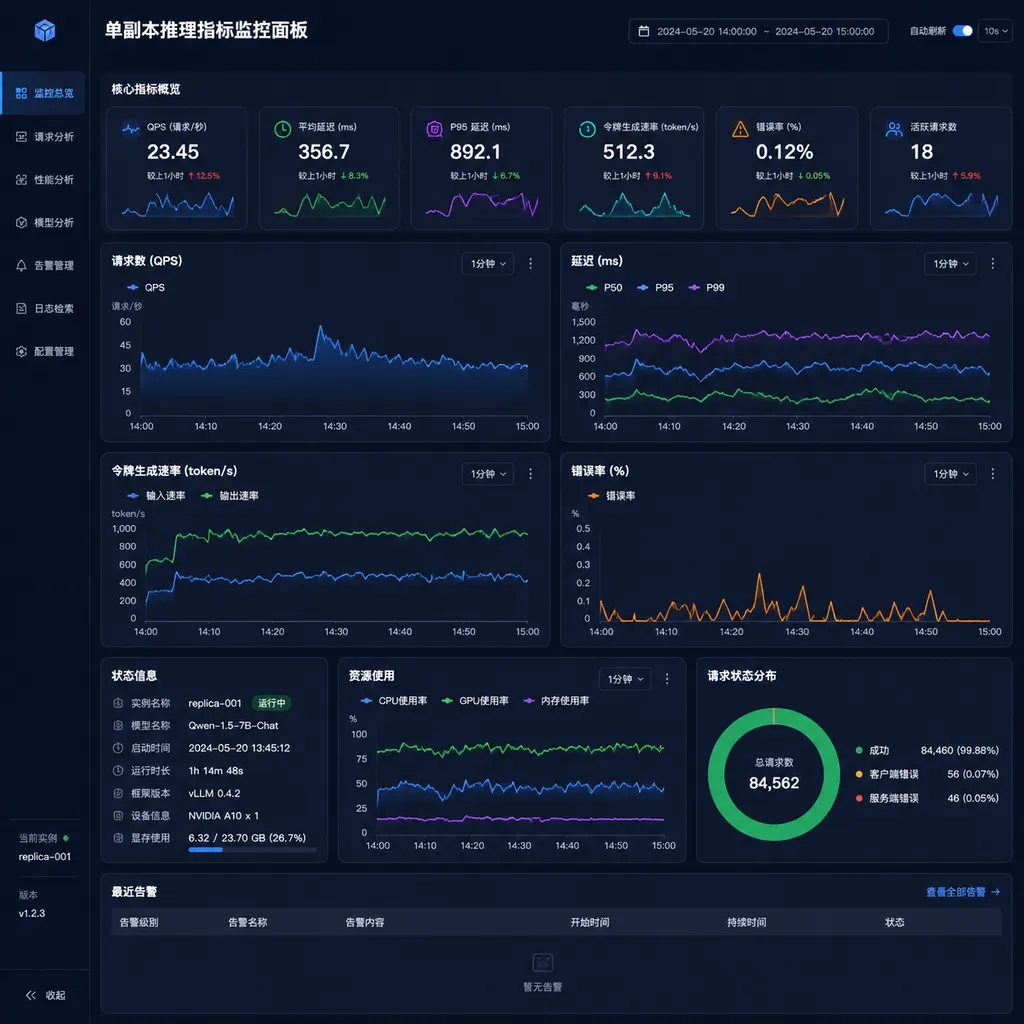
单副本指标
这条是给 SRE 看的。普通托管服务给你的指标是端点级别的 P50/P99——好看,但定位不了问题。Auto Endpoints 给的是每个 replica 各自的 TTFT、TPOT、batch size、KV cache 命中率、显存占用。当你发现长尾延迟抖动时,能直接看到是不是某个副本被一个超长上下文请求拖死了。
这种透明度,过去基本只有自己跑 Kubernetes + vLLM + Prometheus 才能做到。
和谁竞争,差异在哪
把 Auto Endpoints 放回行业地图里看,对手大致有三类:
第一类是纯托管 API——Together、Fireworks、Groq、DeepInfra。优势是便宜(按 token 计费)、零运维。但你拿不到副本指标、调不了 speculative decoding、模型上线节奏看厂商心情。Modal 这次的定位很明确:不抢这个市场,抢的是"我需要自己的推理栈、但不想自己搭 K8s"的那批人。
第二类是企业级 LLM 平台——红帽 AI Inference Server、阿里云 PAI-EAS、AWS SageMaker。这些产品强在合规、混合云、和现有企业 IT 栈集成。但 DevEx 一言难尽,从拉镜像到出端点经常需要好几天。Modal 的优势就是 serverless 的开发速度,秒级冷启动配上 CLI 体验,迭代节奏完全不一个量级。
第三类是自建——直接 vLLM + Ray Serve + 自己买卡或租 H100。性能上限最高,但要养一支懂推理优化的团队。Modal 想说服这批人的逻辑是:调优我们都封好了,但所有旋钮你都能拧,相当于雇了一个 24 小时在线的推理工程师。
一些值得注意的细节
- 冷启动:Modal 一直在卷冷启动时间,120B 量级模型的首次加载已经压到几十秒级别,靠的是权重分片预热和 GPU 池预留。Auto Endpoints 继承了这套机制,对于潮汐流量的应用比较友好——夜里没量真就缩到 0,不烧钱。
- NVFP4 / FP8 优先:catalog 里大量是 NVFP4 和 FP8 量化版本,这点和 NVIDIA 这一年在 Blackwell 上推 FP4 推理的节奏是对齐的。对于追求 cost-per-token 的团队,这是个明显的红利。
- OpenAI 兼容:所有 Auto Endpoint 出来的接口都是 OpenAI 格式,意味着你现有的 SDK、Agent 框架、评测 pipeline 不用动。
- 数据不出账户:这点对 ToB 客户很重要——推理跑在你自己的 Modal workspace 里,不像调 Together API 那样数据要过对方网关。
一个判断
2026 年的 LLM 推理市场已经分层得很清楚:
- 底层做芯片和引擎的(NVIDIA、vLLM、SGLang、TensorRT-LLM)
- 中间做调优和部署的(Modal、Anyscale、BentoML)
- 上层做 API 聚合的(OpenAI Hub 这类一个 Key 调所有模型的平台,把 GPT、Claude、Gemini、DeepSeek 这些主流模型用 OpenAI 兼容格式聚合起来,国内直连)
Auto Endpoints 是 Modal 在中间这层往上挪一格的动作——之前 Modal 是"给你 GPU 和 Python SDK,自己写推理逻辑",现在变成"给你一条命令出一个生产级端点"。这个动作的意义在于:它把开源模型自托管的门槛从"需要一个推理工程师"降到"需要一个会用 CLI 的后端"。
对于那种业务上必须自己掌控推理栈(合规、定制 patch、训练-推理一体化、RL rollout 这类场景)但又不想养基础设施团队的公司,这是个挺有杀伤力的产品。对于纯 API 调用的场景,老老实实用聚合平台依然更省心——这两条路径并不冲突,反而越来越像 Web 时代的"自建 vs SaaS"分工。
值得关注的下一步是 Modal 会不会把 Auto Endpoints 扩展到多模态推理(VLM、TTS、视频生成),他们 solutions 页面里已经提到了 VLM 文档解析延迟优化 3 倍的案例,这条线大概率会接着推。
参考来源
- Modal LLM Solutions 官方页面 - Auto Endpoints 模型 catalog 与 CLI 用法
- Red Hat AI Inference Server 技术深度解析 - 企业级 vLLM 部署方案对比参考


