DeepSeek V4 定档 7 月中旬,API 开始分时计价

DeepSeek V4 正式版将于 7 月中旬上线,同步引入峰谷定价机制:工作日 9-12 点、14-18 点 API 价格翻倍,平时价格维持不变。这是国产大模型首次明确在公开 API 上启用分时定价。
6 月 29 日,多位 DeepSeek API 开发者陆续晒出收到的官方升级邮件:DeepSeek V4 正式版定档 7 月中旬上线,与之同步落地的还有一项过去在公有云 LLM API 上几乎没见过的东西——峰谷定价。
规则很直白。每天上午 9 点到 12 点、下午 2 点到 6 点这两个时段,V4-Pro 和 V4-Flash 的 API 价格按平时的 2 倍计费;剩余时间维持现行价格不变。北京时间为准,工作日休息日一视同仁。
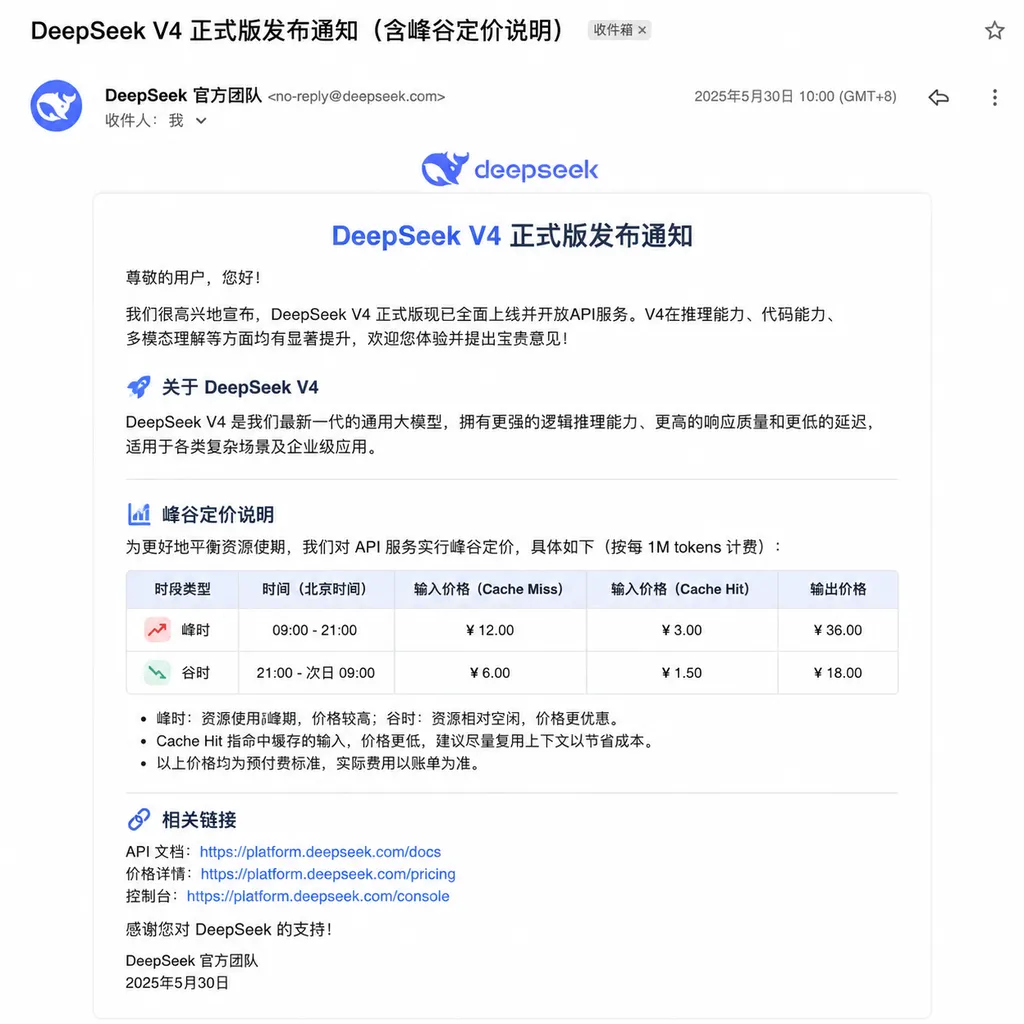
价格表:高峰期就是直接 ×2
邮件附带的完整价格表如下,单位均为人民币元 / 百万 tokens:
deepseek-v4-pro
| 计费项 | 平时价格 | 高峰时段价格 | | --- | --- | --- | | 输入(缓存命中) | 0.025 | 0.05 | | 输入(缓存未命中) | 3 | 6 | | 输出 | 6 | 12 |
deepseek-v4-flash
| 计费项 | 平时价格 | 高峰时段价格 | | --- | --- | --- | | 输入(缓存命中) | 0.02 | 0.04 | | 输入(缓存未命中) | 1 | 2 | | 输出 | 2 | 4 |
高峰时段定义:每日 9:00–12:00、14:00–18:00(北京时间)。
换算下来,一个全天候跑在 V4-Pro 上的应用,如果调用流量平均分布,单日成本会比现在涨大约 29%——因为一天 24 小时里有 7 小时按 2 倍收费。如果调用集中在白天工作时段,账单的实际涨幅会接近翻倍。这是个不算小的变化。
这不是涨价,是把高峰挤出去
要把这次调整看成纯粹涨价,会错过 DeepSeek 真正想做的事。
过去半年,DeepSeek API 在工作日白天经常出现限流、排队、首 token 延迟拉长的情况,社区里讨论得最多的就是「凌晨跑批稳如老狗,白天就得重试三次」。原因不复杂:V3 时代 DeepSeek 已经用过夜间半价的方式做需求引导,但单向折扣的力度不足以让大用户主动把流量挪走——白天该跑还得跑。
这次的逻辑反过来了。不是给夜里打折,而是给白天加价,而且是直接 2 倍。对成本敏感的批处理任务、离线评估、数据合成、文档解析、爬虫管线这类典型「可调度负载」,价格信号会强得多。能搬走的,自然搬走;非要在白天跑的实时业务,等于在为高峰资源付溢价。这套机制电网用了几十年,云服务里现货实例(Spot)也是类似思路。LLM API 第一次把它做成了官方标价,DeepSeek 是第一家。
判断这件事好不好,要分两边看。
对那些做 to C 实时应用的开发者,账单一定会变难看。一个聊天产品的流量曲线天然就是白天高、晚上低,没办法把用户挪去凌晨。这部分用户实际上是在补贴整个系统的削峰填谷。
对做 Agent、做数据管线、做企业内部知识库的团队,影响其实可控甚至有利——只要肯写个调度器,把非实时任务挂在 18 点之后、9 点之前跑,成本不变,还能享受到白天腾出来的容量带来的更稳定的 SLA。
V4 正式版手里有什么牌
价格调整之所以敢这么明牌,前提是产品力跟得上。
V4 预览版 4 月 24 日就已经开源上线,社区跑了两个多月,基本盘是清楚的:
- V4-Pro:总参数 1.6 万亿,激活参数 49B,预训练数据量 33T tokens,原生支持 1M 上下文,网页端走「专家模式」;
- V4-Flash:总参数 284B,激活参数 13B,预训练数据 32T tokens,同样支持 1M 上下文,网页端对应「快速模式」。
两个版本都是 MoE 架构,激活比都压得很低(Pro 大约 3%,Flash 大约 4.6%),这也是 DeepSeek 一贯的成本控制思路——参数管够,每次只点亮一小撮。
7 月中旬的正式版,官方口径是「带来更多功能优化和性能提升」,没有给出具体的 benchmark 数字。从预览版到正式版这两个月里,DeepSeek 主要做了两件外部能看到的事:一是 6 月底完成了 500 亿元规模的新一轮融资,二是 6 月 27 日跟北大联合发布了推理加速框架 DSpark。
DSpark:把推测解码做到工程级
DSpark 这件事值得单独说。它不是新模型,而是套在 V4 现有模型上的推理加速层,已经全量部署到线上服务。论文署名里有创始人梁文锋本人,配套的全栈推测解码工具链 DeepSpec 同步开源。
实测数据:V4-Flash 单用户生成速度提升 60%–85%,V4-Pro 提升 57%–78%。
推测解码(speculative decoding)本身不是新概念——用一个小模型快速出草稿,大模型并行验证,接受连续正确的前缀。问题在于工程落地很难,主要卡两个点:草稿模型并行生成后段会越错越离谱(后缀衰减),以及全量验证浪费算力。
DSpark 的两个改动正好针对这两个痛点:
- 半自回归生成架构。不再纯并行出草稿,而是「并行主干 + 轻量串行头」。主干保速度,串行头补相邻 token 的依赖。论文里的数据有点反直觉——2 层的 DSpark 有效接受长度居然超过了 5 层的纯并行方案 DFlash。
- 置信度调度验证。给草稿 token 加置信度评分,再用「顺序温度缩放」把评分误差从 3%–8% 压到 1% 左右。系统根据实时负载动态调整验证长度,闲时拉满,忙时主动砍掉低价值 token。
第二条尤其有意思。它意味着 DSpark 不光是「让单请求更快」,而是「让系统在高并发下不掉速」——这跟峰谷定价的目标是耦合的:峰谷价格把一部分需求挤走,DSpark 让留下的需求消耗更少的算力。一软一硬,配合起来调度白天的资源压力。
开发者应该改什么
从工程角度,应对这次调价基本就是三件事:
第一,审查调用是否真的需要白天跑。把流量按业务分类,能延迟的延迟。一个简单的做法是在任务队列上加一个 peak_aware 标志,命中峰段就推到 18:00 之后的窗口。对大多数批处理类任务,这是几十行代码的事。
第二,把缓存利用率拉满。V4-Pro 的缓存命中价格是 0.025 元 / 百万 tokens,缓存未命中是 3 元——差 120 倍。高峰时段这两个数字翻倍,但相对差距还是 120 倍。Prompt 设计上把稳定前缀(system prompt、few-shot 示例、知识库片段)放在前面,让缓存能真正发挥作用,比纠结峰谷重要得多。
第三,把 V4-Pro 和 V4-Flash 的路由做细。Flash 的输出价格是 Pro 的三分之一,高峰时段绝对成本差距进一步放大。对于不需要复杂推理的环节——意图识别、轻量摘要、格式化输出——直接走 Flash,把 Pro 留给真正需要长链路推理的任务。
第四,如果业务有跨厂商需求,用聚合层屏蔽掉单一供应商的定价波动。OpenAI Hub 这类聚合平台支持 DeepSeek V4 系列以及 GPT、Claude、Gemini 等主流模型,一个 Key 调全部,OpenAI 兼容格式直接接入,国内直连免去网络层的麻烦。在这次峰谷机制落地之后,做 A/B 路由或者高峰自动降级的成本会比单接 DeepSeek 官方 API 低一些。
一个大模型公司开始像云厂商一样思考
这次调价最值得琢磨的不是数字,是信号。
LLM API 行业过去两年一直在打价格战,谁都不敢轻举妄动。DeepSeek 是把价格做到地板价的那一家,但它现在站出来说「白天用要加钱」,意味着它认为自己的市场地位足够稳,可以开始考虑利润而不只是份额;也意味着它把自己当成一家需要管理资源调度的基础设施公司,而不是一个跑 benchmark 的模型团队。
参数规模、推理速度、定价机制、调度策略——这四件事开始被同一家公司放在一起优化。这是 AWS 在 2010 年代干过的事情,是云厂商成熟期的标志动作。国产大模型这一波,DeepSeek 是第一个走到这一步的。
后面会不会有阿里通义、智谱、Moonshot 跟进峰谷定价,值得观察。但底层的逻辑回不去了:算力是有边界的、流量是有周期的、价格是可以拿来当调度信号的。这一页翻过去以后,「API 价格」就不再是一个固定数字,而是一个时间函数。
7 月中旬,正式版上线那天就是新规生效之时。建议手头跑着 DeepSeek 的同学这两周把账单结构盘一遍——哪些调用挪得动、哪些挪不动、哪些可以下沉到 Flash——比正式版上线后再补救从容得多。
参考来源
- DeepSeek V4 正式版发布计划及计费调整说明(linux.do):社区第一时间整理的完整价格表与官方邮件原文。
- DeepSeek V4 正式版定档 7 月中(linux.do):附官网 UI 改版截图的开发者讨论帖。
- deepseek 调价了(linux.do):多位开发者收到调价邮件后的第一手反馈与讨论。
- deepseek 要涨价了啊(linux.do):API 用户收到通知后的早期讨论。
- DeepSeek V4 正式版官宣 7 月中旬上线,引入峰谷定价机制(知乎):包含官方价格表截图与社区分析。

