美团 LongCat-2.0 开测:9.9 元 5000 万 token

美团万亿参数大模型 LongCat-2.0-Preview 正式开放付费计划,新用户 9.9 元买 5000 万 token,399 元 10 亿 token,缓存命中免费。这是目前唯一全程基于国产算力训练的万亿参数模型。
美团把价格牌摆出来了。
LongCat-2.0-Preview 在 4 月底悄悄开放邀请测试两个月之后,美团这周正式上线了它的付费计划:新用户实名认证送 1000 万 token,9.9 元 5000 万 token 的尝鲜包,399 元 10 亿 token 的 Token Plan,外加按量付费 API。缓存命中部分不计费。
这个定价在国内一线模型里属于明牌掀桌——单看 399 元买 10 亿 token,平均下来每百万 token 不到 0.4 元,已经下探到了 DeepSeek V4 Flash 的价格腰部区间。考虑到 LongCat-2.0 是万亿参数 MoE、支持 1M 上下文、还专门面向 Agent 场景做了工具调用优化,这套定价更像是在替国产算力集群打广告:能跑出来,跑得动,还便宜。
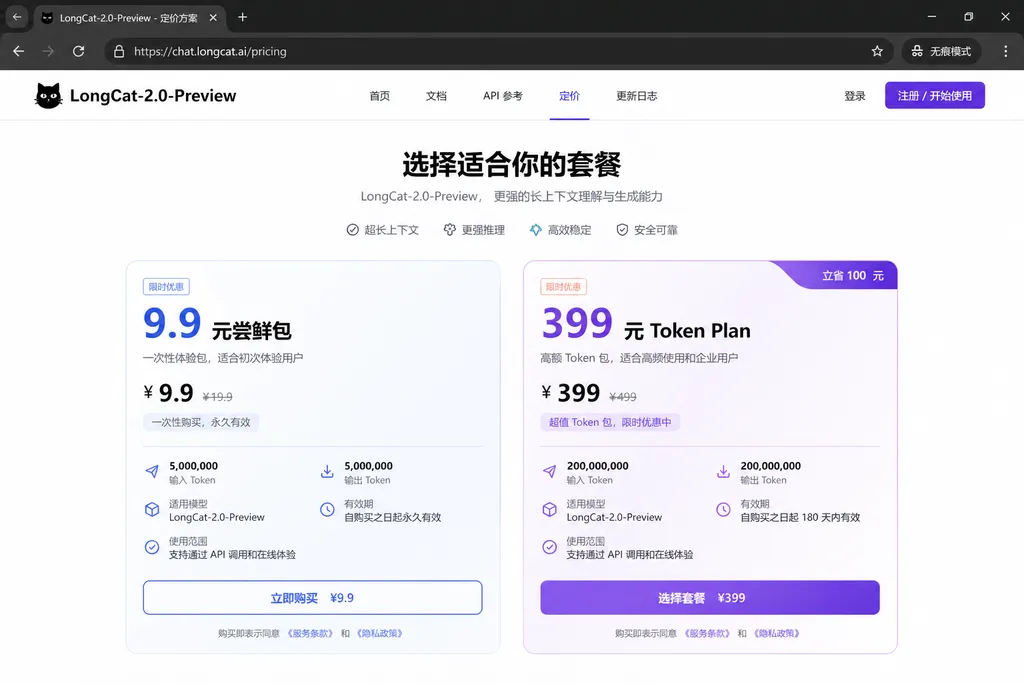
先把价格说清楚
美团这次的付费结构分四层,对开发者来说不算复杂:
- 新用户福利:实名认证后赠送 1000 万 token,够你在 Agent 项目里跑几百轮工具调用循环。
- 9.9 元尝鲜包:5000 万 token,折合每百万 token 约 0.2 元。这个价格基本只够覆盖电费,目的就是把人拉进来。
- Token Plan(399 元):10 亿 token,每百万 token 约 0.399 元。适合中小团队当主力 API 用。
- 按量付费 API:标准计费档,缓存命中部分免费。
缓存免费这一条值得单独拎出来说。Agent 应用最大的成本黑洞是什么?是反复传同一份系统提示词、同一段长上下文、同一个工具描述列表。LongCat 把缓存命中那一刀直接抹掉,等于告诉做 AI 编程助手、做 RAG 系统、做长会话客服的团队:你们最烧钱的那块,我不收钱。
这套定价逻辑跟 DeepSeek 早期那种「把推理成本打到地板上」的打法是一个路子,区别是美团这次还多了一个故事——它是用国产卡跑出来的。
万亿参数,但训练用的全是国产卡
LongCat-2.0-Preview 的技术底子,业内已经基本对齐到了同期发布的 DeepSeek V4 那个量级:
- 总参数突破万亿,MoE 架构,每 token 激活参数约 48B
- 支持 1M 上下文窗口,单次推理可处理数百万字输入
- 训练推理全程依托国产算力集群完成,使用 5 万至 6 万张国产 AI 加速卡
第三条是真正的爆点。
在此之前,国内的万亿参数模型基本都是英伟达 H100/A100 集群上的产物,就算后期做了国产卡适配,训练阶段也大多是混合方案。LongCat-2.0 是目前唯一公开确认全程在国产算力上完成万亿参数预训练的大模型,5 到 6 万张国产卡的训练规模也创下了国内纪录。
这是什么概念?万卡级集群本身就是工程地狱——任何一张卡的数值精度偏差、任何一次通信延迟,在并行运算里都会被指数级放大,最后整个训练任务崩掉、模型不收敛。把规模拉到 5 万卡还要稳定跑完万亿参数 MoE 的训练,意味着团队必须在并行策略、通信拓扑、混合精度、容错机制上全部自己啃下来。CUDA 那套用了 20 年的工具链、算子库、调试器,在这里基本派不上用场。
美团没有开源 LongCat-2.0,也没发技术报告,这点让人有点意外——前面几代 Flash-Chat、Flash-Thinking、Omni 全都老老实实挂在 Hugging Face 和 GitHub 上。这次跨代版本反而闷声不响,只发了几行更新日志、开了个邀请测试。猜测一下,可能是因为这次的训练栈跟国产芯片厂商的深度绑定太强,开源出来对外部开发者没太大复现价值,反而会暴露一堆芯片侧的工程细节。
这玩意儿到底好不好用
LongCat-2.0 的官方更新日志只列了三件事:原生支持工具调用与多步推理、擅长代码生成与自动化工作流、深度集成 Claude Code、OpenClaw、OpenCode 和 Kilo Code。
翻译一下:这是个奔着 Agent 去的模型。
从 Linux.do 社区的早期内测反馈来看,LongCat-2.0-Preview 的体感「有点像 MiMo-V2.5-Pro」——响应速度还行,长上下文里的指令跟随比上一代提升明显,工具调用的稳定性可以直接接入 Claude Code 这种重度 Agent 框架而不掉链子。1M 上下文这个参数在实际使用中确实顶得住,丢一份几十万字的代码仓库进去做全局重构,模型不会在中段就开始幻觉。
但也不是没有短板。从社区反馈看,纯推理任务(数学、逻辑题)上 LongCat-2.0 还跟 DeepSeek V4、GPT-5.5 有差距;中文创作和文风模仿是强项,但代码生成的细节质量比起 Claude 4.5 Sonnet 这种专门优化过的模型还差一截。换句话说,它是个偏向「工程实用型」的模型,不是炫技型。
这跟美团做这个东西的初衷有关。王兴在最近的财报电话会上说过,要「把美团 App 率先升级成 AI-Powered App」。LongCat 真正的训练养料,是美团全国 2800 多个市县的即时配送网络、550 万单无人车配送数据、78 万笔无人机商业订单。这些场景对模型的要求很具体:能听懂复杂指令、能调用工具、能在长流程里不忘事。
炫榜单和写代码相比,美团显然更在意第一种能力。
跟 DeepSeek V4 怎么比
两个模型同一天放出来,参数量级相近,定价区间相近,难免被放在一起比。
大致拆一下:
| 维度 | LongCat-2.0-Preview | DeepSeek V4 | |---|---|---| | 架构 | 万亿参数 MoE,激活 ~48B | 万亿参数 MoE | | 上下文 | 1M | 1M | | 训练算力 | 全程国产卡(5-6 万张)| 英伟达起步,全栈迁移至昇腾 950PR | | 开源 | 否 | 是 | | 定价 | 缓存免费,399 元/10 亿 token | V4 Flash 缓存命中 0.02 元/百万 token | | 主打场景 | Agent / 工具调用 / 长流程 | 通用基础模型 |
DeepSeek 走的是「开源 + 极致低价 + 通用能力」的路子,目标是替代 GPT 和 Claude 在全球开发者心里的位置。LongCat 走的是「原生国产训练 + 闭源 + 场景闭环」的路子,目标是给美团自己的业务做底座,顺便对外卖 API。
两条路子谁更对,现在下结论太早。但有一点是清楚的:国产算力替代这件事,从「能用」走到「能跑万亿参数模型」这一步,时间比大多数人预期的要快得多。一年前业内还在讨论昇腾能不能稳定跑大模型推理,今年就已经有人在 5 万卡国产集群上完成预训练了。
接入路径
开发者目前接入 LongCat-2.0-Preview 有两条路:
- 去 longcat.ai 申请邀请测试,每日 1000 万免费 token 额度,适合先试用看效果
- 直接走付费计划,9.9 元 5000 万 token 的尝鲜包基本没有门槛
API 兼容 OpenAI 格式,模型名通常配置为 longcat-2.0-preview。如果你已经在用 OpenAI Hub 这类聚合平台,一个 Key 调所有主流模型,那 LongCat 也已经在支持列表里,可以直接切过去做对比测试,不用单独申请 key。
这件事的真正信号
回到一开始那个价格。
9.9 元 5000 万 token、缓存命中免费、Agent 场景优化——这套组合拳放在一年前是不可想象的。它能成立的前提,是国产算力从「能用」变成了「能用得起」。当训练成本不再被海外芯片的出货节奏卡脖子,国产模型厂商才有底气把价格压到这个水平。
美团这次低调发布反倒说明了它的自信:不靠 PR 造势,靠 API 调用量说话。对开发者来说,多了一个万亿参数、长上下文、工具调用稳定、价格便宜的国产选项,至少在做 Agent 产品的时候,可选项又厚了一层。
至于它能不能在长期对决里跑赢 DeepSeek,跑赢 Qwen,跑赢更后面的玩家——这就要看接下来几个月的迭代速度了。预览版只是开场。
参考来源
- 美团 LongCat-2.0-Preview 正式上线 新用户9.9元5000万tokens - linux.do:付费计划上线首日的社区讨论,包含价格细节与新用户福利说明
- 美团的大模型LongCat-2.0正式发布了 9.9元5000万/399元10亿 - linux.do:开发者实测反馈,含内测期使用体感与缓存策略讨论


