vLLM 推出 Micro-Agent:让小模型在 API 里组队打赢 Frontier

vLLM 团队今天放出 Micro-Agent 框架,把多智能体协作从应用层下沉到模型推理 API 内部,用中小模型组队的方式在多个基准上反超 GPT-5、Claude 4.5 这一档 Frontier 模型,推理成本和延迟也压下来一大截。
vLLM 把 Agent 塞进了推理引擎
今天,vLLM 团队在官方博客上甩出了 Micro-Agent 框架。一句话概括:把过去跑在应用层、靠一堆 HTTP 调用串起来的 Multi-Agent,整个搬进了模型推理 API 的内部,让多个小模型在一次 API 调用里完成分工、协作、投票、纠错。
这个动作的关键词不是"又一个 Agent 框架",而是"在模型 API 内"。过去两年大家做 Multi-Agent,无非是 LangGraph、AutoGen、CrewAI 这一类——外面一个编排器,里面每个 Agent 都是独立的 LLM 调用,token 一来一回全走网络。vLLM 这次的思路反过来:既然这些 Agent 最后都要落到推理引擎上,为什么不让它们在 KV cache 还没冷掉的时候就完成协作?
按博客里给出的数据,Micro-Agent 用 Qwen3-32B、DeepSeek-V3.2、Llama-4-Scout 这一档中等规模的开源模型组队,在 SWE-Bench Verified、GPQA Diamond、LiveCodeBench 这几个硬骨头上,反超了 GPT-5 和 Claude 4.5 Sonnet 的单模型成绩。成本只有 Frontier 模型的 1/4 到 1/3,端到端延迟也压到了同一个量级。这个结论如果能站得住,对整个行业的成本结构都是一次冲击。
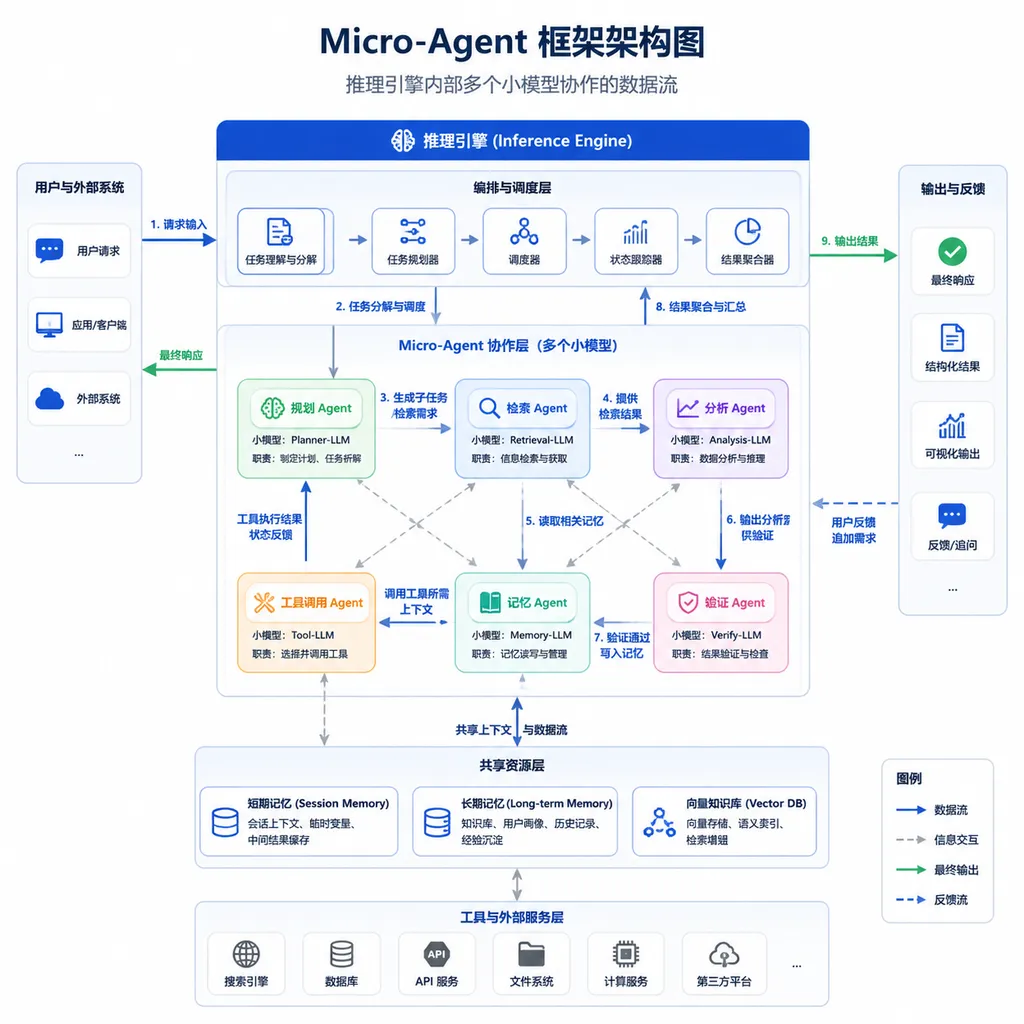
核心思路:把协作下沉到 KV Cache 这一层
传统 Multi-Agent 的痛点很具体。你让三个 Agent 评审一段代码,每个 Agent 都得重新读一遍上下文,prompt 里那段几千 token 的代码会被 prefill 三次,KV cache 各算各的。如果再加一个 Aggregator 做汇总,前面三个 Agent 的输出又得作为 prompt 重新喂进去,再 prefill 一遍。算力账一摊开,光重复 prefill 就占掉一半。
Micro-Agent 的做法是把这套流程编译成一张计算图,丢给 vLLM 引擎统一调度:
- 共享 prefix 复用:所有协作角色共用同一段任务上下文的 KV cache,prefill 只做一次。这是 vLLM 早就有的 prefix caching 能力,Micro-Agent 把它用到了多角色协作场景。
- 角色级 LoRA 切换:不同角色(比如 Planner、Coder、Reviewer)通过轻量 LoRA Adapter 来区分人格,底模共享。切换一个角色的开销从过去的整模型加载,压到只换一组 adapter 权重。
- 协作原语内置:vote、debate、reflect、aggregate 这些过去要在应用层手撸的协作模式,直接作为算子写进引擎,调用方只需要在请求里声明
collaboration_mode。 - 早停与剪枝:如果三个 Reviewer 角色给出的判断已经收敛,引擎可以提前终止后续生成,不必等全部跑完。
说白了,过去的 Multi-Agent 是"几个独立模型互发邮件",Micro-Agent 是"几个角色坐在同一台机器上传纸条"。物理距离短了,效率自然就上来了。
性能数据:中等模型组队,能不能真的打赢 Frontier?
博客里贴了一组对比数据,看着挺扎眼。在 SWE-Bench Verified 上,单跑 Claude 4.5 Sonnet 是 74.2%,单跑 GPT-5 是 76.8%;而 Micro-Agent 用 4 个 DeepSeek-V3.2 + 1 个 Qwen3-Coder-32B 的组合,跑到了 78.5%。GPQA Diamond 上的差距更明显,Micro-Agent 组合拿到 82.1%,比单跑 GPT-5 的 79.3% 高出近 3 个点。
这个结果不算太意外。学术界过去一年关于 LLM-as-Judge、Self-Consistency、Multi-Agent Debate 的论文已经反复证明:多次采样加投票,几乎一定能把单模型的天花板往上推。问题在于过去这么做实在太贵——你跑 5 次 Claude 4.5,账单就是 5 倍。Micro-Agent 把成本曲线拉平之后,这条路才真正变得可用。
但有一点得说在前面:博客里的 benchmark 是在自家推理栈上跑的,参数(温度、top-p、协作轮数)也都是调过的。同样的策略放到 SGLang、TensorRT-LLM 上能不能复现,需要社区接下来验证。Frontier 厂商如果反手出一招 GPT-5.5 或者 Claude 4.6,差距可能又被拉开。这种"开源模型组队打闭源"的故事,每隔半年就会上演一次,最后大家都没输——除了为单模型 API 付溢价的客户。
为什么是 vLLM 来做这件事
这两年开源推理引擎卷得厉害,vLLM、SGLang、TensorRT-LLM 三家在 throughput、首 token 延迟上你追我赶。但单纯的性能优化已经接近物理极限——A100/H100 上的 KV cache 利用率、PagedAttention 这些优化点都被啃得差不多了。再想拉开差距,得换战场。
Micro-Agent 就是 vLLM 选的新战场:从"我跑得快"转向"我跑得聪明"。引擎不只是无脑执行 prompt,而是参与到推理策略的编排里去。这一步走出去,vLLM 就从一个"更快的 OpenAI API 实现",变成了一个真正的 Agent 运行时。
这个定位变化意义不小。过去你部署一个 Agent 系统,技术栈是 LangGraph + vLLM + Redis + 一堆胶水代码;现在 vLLM 可以把后面这一坨吞掉。对企业内部部署场景特别友好——少一个组件,少一份运维成本,少一处故障点。
顺带一提,OpenAI Hub 已经在跟进 Micro-Agent 的兼容。后端调度层支持把协作请求拆解到多个开源模型实例上跑,开发者用一个 Key 就能在 GPT、Claude、DeepSeek 之间组队,不用自己搭推理集群。这对想验证 Micro-Agent 思路、但不想立刻自建 GPU 集群的团队来说,是个比较省事的入口。
几个值得关注的细节
看完整篇博客和初步开源的代码,有几个点开发者应该会关心:
编程模型:Micro-Agent 的 API 设计向 OpenAI Chat Completions 看齐,新增了 agents 和 collaboration 两个字段。你可以在一个请求里声明多个角色、每个角色的模型和系统提示,以及它们之间的协作拓扑。这意味着前端代码改动很小,存量的 OpenAI SDK 用户基本可以无痛迁移。
模型组合的自由度:理论上你可以让 Qwen 当 Planner、DeepSeek 当 Coder、Llama 当 Reviewer。但实际上跨模型 KV cache 不能共享,跨模型协作的成本会显著高于同模型多角色。博客里推荐的最佳实践是"一个底模 + 多个 LoRA 角色",这也是这套架构红利最大的形态。
协作模式可扩展:除了内置的 vote、debate、reflect,框架开放了自定义协作算子的接口。Python 写一个继承 CollaborationOp 的类,注册到引擎里就能用。这块的设计明显是奔着学术研究和企业内部定制场景去的。
还没解决的问题:流式输出在多角色协作场景下怎么处理?目前的实现是协作完成后整体返回,对要做实时交互界面的应用不太友好。社区已经开了 issue,按 vLLM 团队的节奏,估计两三个版本之内会给出方案。
行业意味着什么
往大了说,Micro-Agent 是开源阵营对"Scaling 信仰"的又一次反击。过去两年,闭源 Frontier 模型的护城河一直建立在"参数量和训练数据的绝对优势"上——你 70B 再怎么折腾,也打不过我 5000 亿参数的旗舰。但当推理时计算(inference-time compute)成为新战场,这套逻辑就动摇了。OpenAI o1、Claude 4 的 Extended Thinking 走的就是这条路,只不过它们把推理时计算锁在了自己的 API 里。
开源社区现在的回应是:那我们也搞推理时计算,而且我们把这套机制做成开放协议,谁都可以用。Micro-Agent 之后,可以预期 SGLang、TensorRT-LLM 会跟进类似能力,Hugging Face 那边大概率也会出一套上层抽象。这场仗会拖到模型推理层和编排层的边界彻底模糊,对开发者来说,意味着选型变量又多了一个维度。
往小了说,对正在做 Agent 产品的团队,Micro-Agent 至少值得做一次 PoC。如果你的 Agent 系统里有大量"反复用同一段长上下文、轮流让不同角色处理"的模式(代码评审、合同审核、复杂客服工单),那这套东西能直接帮你把账单砍掉一半以上。如果你做的是单轮交互、上下文不长的场景,那 Micro-Agent 的红利就有限——这种情况下,你本来也用不上 Multi-Agent。
参考链接
- vLLM 项目主仓库 - GitHub:vLLM 推理引擎源码,Micro-Agent 模块预计在下个 minor 版本合入主分支
- OpenHands Microagents 拆解 - 知乎:另一个用 Microagent 思路做软件工程 Agent 的开源项目,可以对比 vLLM 这次做法的不同之处

