Claude Monitor工具发布:Agent按需唤醒时代来了

Anthropic为Claude新增Monitor工具,Agent不再依赖低效轮询,而是按需唤醒执行任务,Token消耗大幅降低。这对重度API调用者来说是一次实质性的成本优化。
Anthropic 这次没搞什么大发布会,但丢出来的东西很实在——Claude 新增了 Monitor 工具,让 Agent 具备了「按需唤醒」的能力。
简单说:你的 Agent 不用再傻傻地每隔几秒轮询一次了。有事它醒,没事它睡。Token 账单直接瘦一圈。
先搞清楚问题出在哪
做过 Agent 开发的人都知道一个痛点——轮询(Polling)。
传统的 Agent 工作模式是这样的:你给它一个任务,比如「监控某个数据源,有变化就处理」。Agent 怎么干呢?它每隔一段时间就去问一次:变了没?变了没?变了没?
每问一次,就是一次 API 调用。每次调用,就要消耗 Token。哪怕数据源一整天都没变化,Agent 也在那儿勤勤恳恳地烧你的钱。
这不是某个框架的问题,这是整个 Agent 架构的通病。之前 Claude Code 源码泄露的时候,社区就扒出来过它的 ToolSearch 机制——当工具数量超过阈值,光是把所有工具描述塞进 Prompt,Token 成本就已经不可接受了。Anthropic 内部的方案是按需加载工具定义,据分析这一招就实现了 98.7% 的 Token 缩减。
但那只是工具定义层面的优化。真正的大头在运行时:Agent 在等待外部事件的过程中,到底要不要一直「活着」?
Monitor 工具解决的就是这个问题。
Monitor 工具到底怎么工作
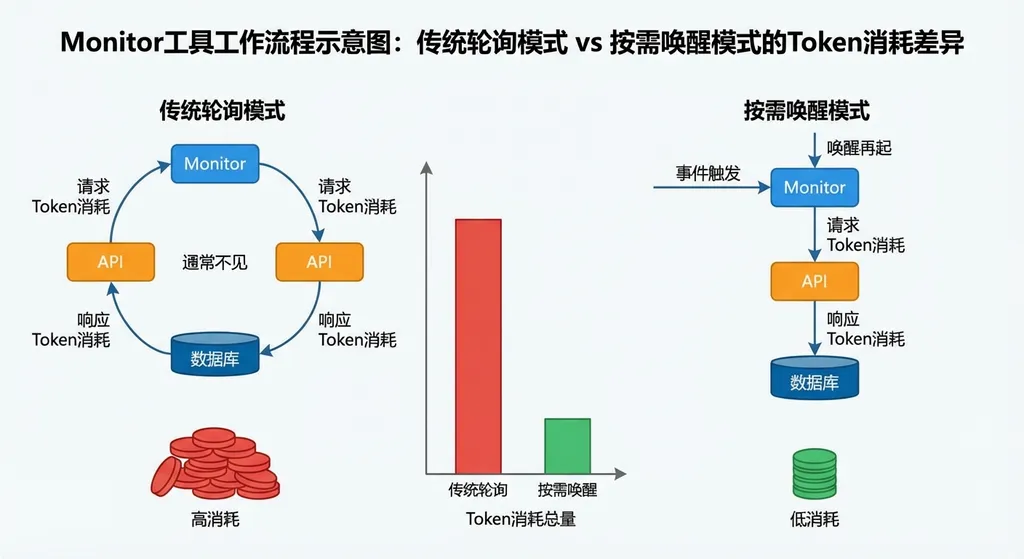
核心思路其实不复杂:把 Agent 从「主动轮询」变成「被动唤醒」。
传统模式下,Agent 的生命周期是连续的。它启动之后就一直运行,不断地调用模型来判断下一步该干什么。即使当前没有任何需要处理的事件,Agent 也在消耗计算资源和 Token。
Monitor 模式下,Agent 可以注册一个监控条件,然后进入休眠状态。当条件被触发时,Agent 才会被唤醒,继续执行后续逻辑。休眠期间,不调用模型,不消耗 Token。
这跟操作系统里的中断机制是一个思路。CPU 不会一直去检查键盘有没有被按下,而是键盘按下时发一个中断信号,CPU 再去处理。Monitor 工具就是给 Agent 加了一套中断机制。
从开发者社区的反馈来看,这个功能属于 Anthropic 的 Proactive 模式体系的一部分。这套体系包括焦点感知、定时唤醒、Skill Discovery 和 Token Budget 管理,目标是让 Agent 从被动的「工具」进化成主动的「同事」。Monitor 是其中最基础也最实用的一块拼图。
实际场景:省多少?
来算一笔账。
假设你有一个 Agent 负责监控 GitHub 仓库的 Issue,有新 Issue 就自动分类打标签。
用轮询模式,每 30 秒检查一次,一天就是 2880 次调用。每次调用哪怕只消耗 500 Token(包括系统提示、上下文、工具描述),一天就是 144 万 Token。一个月 4320 万 Token。如果你用的是 Claude Sonnet,这笔钱不算小数目。
关键是,大部分仓库一天可能就几个新 Issue。也就是说,99% 以上的轮询调用都是无效的。
换成 Monitor 模式,Agent 注册一个 Webhook 监听,有新 Issue 时才唤醒。一天 5 个 Issue,就 5 次调用。Token 消耗从 144 万降到几千。
这不是优化 10%、20% 的问题,这是数量级的差距。
再举一个更贴近日常开发的例子:CI/CD 流水线监控。你让 Agent 盯着构建状态,失败了就分析日志、给出修复建议。轮询模式下,Agent 每分钟问一次「构建完了没」,一次构建 20 分钟,就白烧 20 次调用。Monitor 模式下,构建完成时触发一次,Agent 醒来干活,干完继续睡。
对开发者意味着什么
这个功能的意义不只是省钱,虽然省钱确实是最直接的好处。
更深层的变化是:Agent 的架构范式在转变。
之前做 Agent,你得自己处理一大堆基础设施问题——轮询间隔设多少?怎么避免重复处理?怎么控制并发?怎么在 Agent 空闲时释放资源?这些跟业务逻辑无关的脏活累活,占了开发工作量的一大半。
有了 Monitor 工具,这些问题被下沉到了平台层。开发者只需要关心:什么条件下唤醒?唤醒后干什么?
这跟 Serverless 的思路如出一辙。Lambda 函数不需要关心服务器什么时候启动、什么时候关闭,有请求来了就执行,没请求就不花钱。Monitor 工具让 Agent 也具备了这种弹性。
社区里已经有人在讨论基于这个能力构建多 Agent 协作系统。比如一个 Agent 负责监控,发现异常后 Fork 出一个子 Agent 去处理,处理完自动销毁。主 Agent 继续睡。这种模式下,Token 成本几乎完全跟实际工作量成正比,没有任何浪费。
跟竞品比一下
OpenAI 的 Assistants API 目前还是基于 Run 的模式——你创建一个 Run,它执行完返回结果。要实现持续监控,还是得自己写轮询逻辑。虽然可以用 Streaming 来优化响应延迟,但本质上没解决空闲时的 Token 浪费问题。
Google 的 Gemini 在 Agent 方面的布局更偏向 Vertex AI 平台层面,通过 Cloud Functions 和 Eventarc 来实现事件驱动。思路是对的,但这要求开发者深度绑定 GCP 生态。
Anthropic 的做法更优雅一些——把事件驱动的能力直接内置到模型的工具层,开发者不需要额外的云基础设施就能用。当然,这也意味着你得在 Anthropic 的框架内工作。
目前来看,Anthropic 在 Agent 基础设施这块确实走在前面。从 Tool Use 到 Computer Use,再到现在的 Monitor,每一步都在降低 Agent 开发的门槛和成本。
怎么用
如果你已经在用 Claude API 做 Agent 开发,接入 Monitor 工具的方式跟其他 Tool Use 一样,在 tools 参数里声明就行。
一个简化的调用示例:
import requests
# 通过 OpenAI Hub 调用,兼容 OpenAI 格式,国内直连
response = requests.post(
"https://openai-hub.com/v1/messages",
headers={
"Authorization": "Bearer YOUR_OPENAI_HUB_KEY",
"Content-Type": "application/json"
},
json={
"model": "claude-sonnet-4-20250514",
"max_tokens": 1024,
"tools": [
{
"type": "monitor",
"name": "issue_monitor",
"description": "监控 GitHub 仓库新 Issue",
"trigger": {
"type": "webhook",
"source": "github",
"event": "issues.opened"
}
}
],
"messages": [
{
"role": "user",
"content": "监控 my-org/my-repo 仓库,有新 Issue 时自动分类并打标签。"
}
]
}
)
print(response.json())
如果你同时在用多家模型的 API,OpenAI Hub 这类聚合平台会方便一些——一个 Key 调 Claude、GPT、Gemini、DeepSeek,不用每家单独管理密钥和计费,对于需要在不同模型间切换测试的场景尤其省事。
一些注意事项
社区里已经有开发者在踩坑了。Linux.do 上有人提到「刚打了 1 小时缓存补丁,这又要升级才能用了」——说明 Monitor 工具可能需要较新版本的 SDK 或 API 端点才能支持。如果你在用旧版本的 Claude API 客户端,建议先升级。
另外,Monitor 工具的触发机制目前还在演进中。从已有信息来看,它支持 Webhook 触发和定时触发两种模式,但具体的触发源和事件类型还在扩展。如果你的场景比较特殊,可能需要等后续更新。
还有一点值得关注:Token Budget 管理。Monitor 模式下,Agent 的唤醒频率取决于外部事件,这意味着 Token 消耗变得不可预测。建议配合使用 claude-monitor 这类社区工具来监控实际用量,避免某个异常事件源疯狂触发导致账单爆炸。GitHub 上已经有比较成熟的实践指南,支持实时 Token 用量显示、会话窗口管理和消耗速率预估。
往大了看
这次更新放在更大的背景下看,Anthropic 的意图很清晰:让 Claude 成为 Agent 开发的首选基座模型。
模型能力本身,各家已经卷到了一个相对接近的水平。真正拉开差距的,是围绕模型的工具生态和开发体验。Anthropic 从 Tool Use 开始,一步步把 Agent 开发中最痛的点都用原生能力解决掉——文件操作有 Computer Use,代码执行有 Code Execution,现在事件驱动有 Monitor。
这条路线的终点,是让开发者用最少的胶水代码就能构建出生产级的 Agent 系统。
对于已经在做 Agent 产品的团队来说,Monitor 工具值得尽快评估。不是因为它多酷炫,而是因为它解决的是一个实实在在的成本问题。在 Agent 大规模部署的场景下,轮询模式的 Token 成本会随着 Agent 数量线性增长,而 Monitor 模式的成本只跟实际事件量相关。
规模越大,差距越明显。
参考来源:
- Claude新增Monitor工具讨论 - Linux.do 社区关于 Monitor 工具的技术讨论
- claude-monitor 用量监控工具实践指南 - GitHub 上的 Claude Code 用量监控实践
- Agent 智能体原理讨论 - 知乎关于 Agent 效率与 Token 优化的技术分析
