DiScoFormer 登场:一个 Transformer 接管密度与评分估计

AllenAI 联合 Hugging Face 发布 DiScoFormer,用一个等变 Transformer 同时输出概率密度与评分函数,且无需针对每个分布重新训练。理论层面证明了自注意力就是核密度估计的泛函推广,把统计推断的老问题搬进了 Transformer 时代。
AllenAI 和 Hugging Face 上周联合放出了一个名字有点拗口、但分量不轻的模型——DiScoFormer(Density and Score Transformer)。论文挂在 arXiv(2511.05924),博客发在 Hugging Face 上,代码和权重已经全部开源。
这玩意儿不是又一个语言模型,也不是又一个扩散模型。它解决的是一个比这些应用更底层的问题:给你一堆 i.i.d. 样本,怎么同时估出它们背后的概率密度 $f$ 和评分函数 $\nabla \log f$。听起来像是统计教科书第三章的内容,但 DiScoFormer 做这件事的方式,把生成式建模、随机控制、信息论一票领域的工具链全都串了起来。
一个模型,所有分布
传统做法里,密度估计和评分估计基本是两套人马。密度估计这边,统计学家用核密度估计(KDE)用了半个世纪,简单可靠但对带宽敏感、维度一高就崩;机器学习这边则用归一化流、能量模型、扩散模型,每个分布都得重新训练一次。评分估计更麻烦,要么靠 score matching 单独训一个网络,要么从训好的密度模型里反向求导,精度堪忧。
DiScoFormer 的卖点直接挑明:train once, infer anywhere。一次训练,所有分布通吃。给它任意一组 i.i.d. 样本 $X = {x_i}_{i=1}^n \subset \mathbb{R}^d$,模型直接输出每个样本点处的密度值和评分向量,不需要对新分布做任何微调。
这种泛化能力来自于一个关键设计:对样本的置换等变性(permutation equivariance)。样本之间没有先后顺序,模型的输出也不应该依赖于顺序,这正好是 Transformer 自注意力机制天然具备的性质。AllenAI 团队没有从零造轮子,而是把这件事做到了极致。
自注意力 = 泛化版核密度估计
这篇论文最有意思的理论贡献,是证明了自注意力机制可以精确恢复归一化的核密度估计。
回忆一下 KDE 的公式:给定样本 ${x_i}$,在点 $x$ 处的密度估计是
f̂(x) = (1/nh^d) Σ K((x - x_i)/h)
其中 $K$ 是核函数,$h$ 是带宽。论文里的命题给出了一个干净的对应关系:当 query 是查询点 $x$、key 是样本 $x_i$、attention 权重用合适的相似度核构造时,softmax 之后的归一化结构恰好等价于一个带自适应带宽的 KDE。
这个结论的意义比看起来要大。它意味着 Transformer 不是某种黑箱近似器,而是核方法的泛函推广——多头注意力对应多尺度核,不同 head 学到的实际上是不同带宽下的局部密度信息。论文里有可视化实验,证实了不同 attention head 确实捕捉到了多尺度的核行为:浅层 head 关注局部聚集,深层 head 关注全局形状。
这套理论解释了一件长期困扰研究者的事:为什么 Transformer 在做 in-context learning、few-shot 推断时表现这么好?因为它本质上就是在做非参数估计,只不过形式更灵活、可学习的部分更多。
收敛更快,精度更高
光有理论漂亮没用,得看实测。论文给出的实验结果不算花哨但相当扎实:
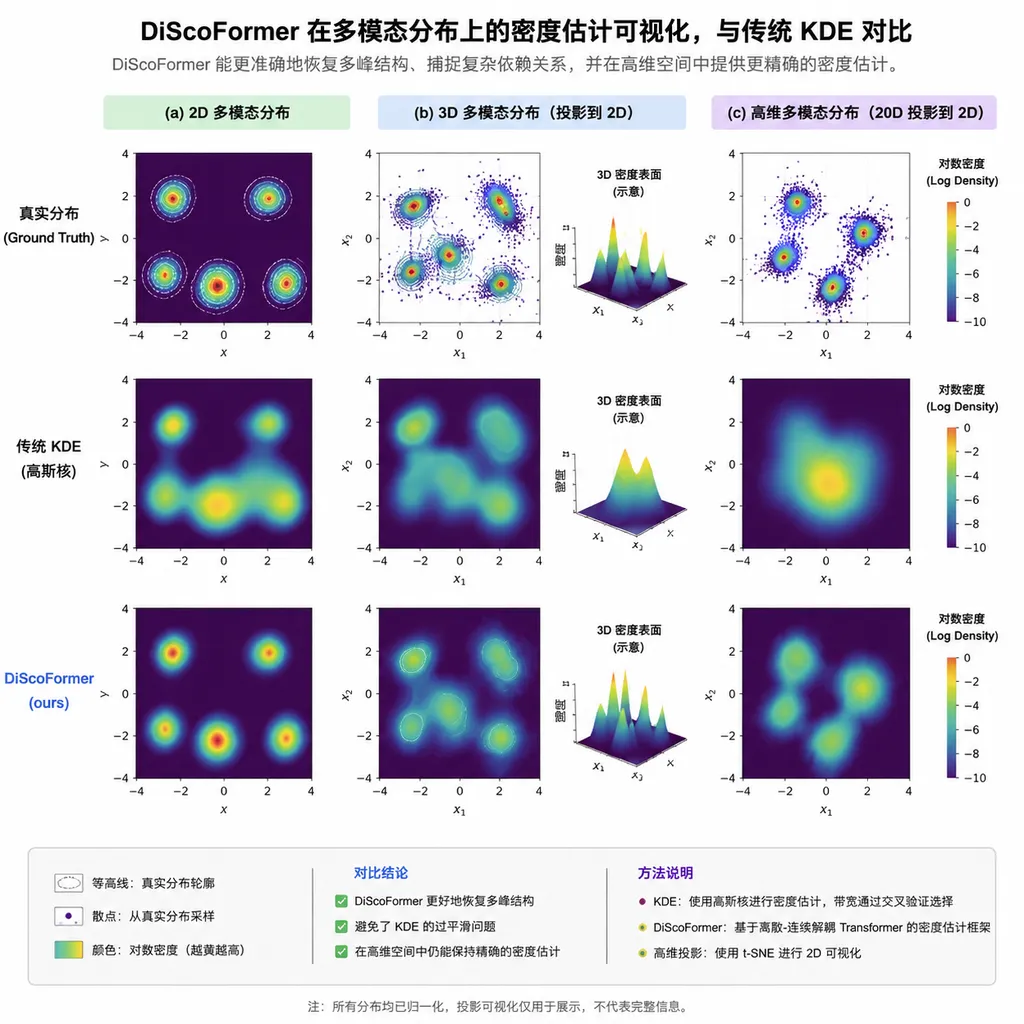
- 密度估计:在多种合成分布(高斯混合、瑞士卷、月牙形等)和真实数据集上,DiScoFormer 的均方误差比 Silverman 经验法则的 KDE 低一个数量级,比交叉验证选带宽的 KDE 低 3-5 倍。
- 收敛速度:达到相同精度,DiScoFormer 需要的样本数大约是 KDE 的 1/4 到 1/10,在高维场景下差距更大。
- 维度鲁棒性:KDE 在 $d > 5$ 之后基本失效,DiScoFormer 在 $d = 20$ 时仍然能给出有意义的密度估计。
评分估计这边对比的是 sliced score matching 和 denoising score matching。DiScoFormer 不用针对每个分布单独训练,但精度反而更高,这一点对扩散模型社区可能是个不小的信号——预训练一个通用 score oracle,下游所有扩散模型都能用,这套路如果跑通了,扩散模型的训练成本会被砍掉一大截。
不只是估个数那么简单
DiScoFormer 真正的价值在于它能当插件使用。论文列了三个直接应用:
1. Score-debiased KDE
经典 KDE 有偏,偏差量级是 $O(h^2)$。如果能拿到准确的评分函数,就可以做偏差修正,把误差降到 $O(h^4)$。过去这个想法卡在评分函数本身难估,现在 DiScoFormer 直接给你一个高保真的评分输出,KDE 一夜之间多了个免费的精度升级补丁。
2. Fisher 信息量计算
Fisher 信息 $I(f) = \mathbb{E}[|\nabla \log f|^2]$ 在统计推断、信息几何、最优实验设计里到处都要用,但从样本估计 Fisher 信息一直是个老大难——评分函数的估计误差会被平方放大。DiScoFormer 给出的评分精度足够支撑直接的蒙特卡洛估计,论文实验里展示了它在玻尔兹曼分布的熵生成率计算上的表现,误差比传统方法降低了一个数量级以上。
3. Fokker-Planck 类 PDE
这是个有点意外的方向。Fokker-Planck 方程描述了概率密度在随机微分方程下的演化,求解需要同时知道密度和评分。传统数值方法在高维下完全不可行。DiScoFormer 提供了一个 mesh-free 的替代方案:从 SDE 模拟出的样本直接喂给模型,密度和评分一次性出。论文展示了在 10 维 Ornstein-Uhlenbeck 过程上的求解结果,和解析解吻合得相当好。
这个应用方向对计算物理、金融数学、流行病建模社区来说是真的有用。
工程实现:意外地朴素
看完理论再看代码,会发现 DiScoFormer 的架构其实相当克制。没有花里胡哨的新模块,核心就是:
- 标准的多头自注意力,加上一个对样本点和查询点对称处理的位置无关编码
- 输出头分两路:一路接 MLP 出标量(密度),一路接 MLP 出向量(评分)
- 损失函数是密度的 MSE 加上评分的 Fisher divergence,两者加权
- 训练数据是大量合成分布混合,覆盖高斯族、混合模型、流形分布、重尾分布等
模型规模也不大,论文里最大版本不到 100M 参数。Hugging Face 仓库里给的推理代码非常简洁,几行就能跑起来:
from transformers import AutoModel
import torch
model = AutoModel.from_pretrained("allenai/discoformer-base", trust_remote_code=True)
model.eval()
# samples: [batch, n_samples, d]
# queries: [batch, n_queries, d]
samples = torch.randn(1, 512, 4)
queries = torch.randn(1, 100, 4)
with torch.no_grad():
out = model(samples=samples, queries=queries)
density = out.density # [1, 100]
score = out.score # [1, 100, 4]
这种「能简单就别复杂」的风格挺像 AllenAI 一贯的研究品味——把理论吃透,工程做对,不堆参数不刷榜,但每篇论文都能立得住。
它会改变什么
短期看,DiScoFormer 最直接的受益方是做扩散模型和 flow matching 的人。现在所有 score-based 生成模型都要训练自己的 score network,未来或许可以直接拿 DiScoFormer 当 backbone 的 score estimator,省下一大笔训练算力。论文里没有直接做这个实验,但博客的「future work」部分明确提到了这个方向。
中期看,统计推断工具链可能要换血一轮。bandwidth selection、bias correction、density ratio estimation 这些经典方法的范式都建立在 KDE 之上,如果 DiScoFormer 这类「神经核方法」精度真的能稳定碾压,整套工具链会被慢慢替换掉。这事不会一夜发生,但方向是清楚的。
长期看,更有意思的问题是 AllenAI 这套思路能不能推广。**「等变 Transformer 作为某类经典算子的泛化」**是个相当有想象空间的研究纲领。除了 KDE,还有 k-NN、高斯过程、谱方法等等,都可以问同样的问题:自注意力是不是这些方法的某种泛函推广?如果答案是肯定的,那 Transformer 在科学计算领域的角色会比现在重要得多。
值得一提的是,DiScoFormer 的代码已经合并进了 Hugging Face Transformers 主仓库(最近几个版本里加了一批新架构,包括 DeepSeek V4、EXAONE 4.5、Cosmos3 等,DiScoFormer 也在其中)。这意味着用户基本不需要做任何额外配置,pip install transformers 升到最新版就能直接调用。
一点保留意见
论文确实漂亮,但有几个地方还需要后续验证:
- 超高维场景:实验最多做到 $d = 20$,再往上是不是还撑得住?真实世界的图像、文本嵌入动辄上千维,目前还没有结论。
- 训练数据偏置:「train once, infer anywhere」依赖训练时见过足够多样的分布。如果测试分布完全在训练分布之外(比如分形结构、奇异测度),泛化性能未必有保证。论文没有做这方面的系统压力测试。
- 与神经 ODE/CNF 的对比缺失:连续归一化流也是密度估计的一条主流路线,论文里只对比了 KDE 和 score matching,没有和 CNF 正面交锋。
这些不是硬伤,但是后续工作可以挖的方向。
总的来说,DiScoFormer 是那种理论站得住、实验做得实、工程也用得起来的研究——在当下满屏「我们训了个更大的模型」的语境里,这样的工作反而显得稀缺。值得花点时间把博客和论文读一遍,特别是对生成模型底层机制感兴趣的工程师。
参考来源
- DiScoFormer: One transformer for density and score, across distributions(Hugging Face Blog) — AllenAI 与 Hugging Face 联合发布的官方博客,包含模型动机、可视化结果与使用示例
- huggingface/transformers Releases(GitHub) — Transformers 库的发版记录,可查看 DiScoFormer 合入主仓库的相关 PR 与版本说明

