Open Memory Protocol 出炉:一份记忆,喂饱所有大模型

开源项目 Open Memory Protocol 试图给 Claude、ChatGPT、Cursor 等模型搭一个共享记忆层,让你在 A 工具里告诉 AI 的事,到了 B 工具不用重说一遍。这件事的难点从来不在存储,而在协议。
一份记忆,跨四个聊天框
开发者圈最近在 GitHub 上盯上了一个新仓库——Open Memory Protocol(OMP)。这个项目的目标听起来很朴素:让 Claude、ChatGPT、Cursor 这些你每天来回切的工具,共用同一份长期记忆。你在 Cursor 里告诉 AI 你的代码风格偏好,切到 Claude 写设计文档时,它不该再问一遍「你倾向用什么语言」。
这事说出来谁都觉得该这样,但过去两年没人真做成。原因不在技术——向量数据库满地都是——而在每家厂商都把记忆藏在自己的围墙里。OpenAI 在 2024 年 2 月给 ChatGPT 加了记忆功能,存在自家服务器;Anthropic 直到 2025 年 10 月才给 Claude 付费用户开放记忆导入工具,2026 年 3 月才下放给免费用户,而且坦率讲,Claude 的记忆机制比 ChatGPT 简单不少,更像是「按需检索旧对话」而不是真正的用户画像;Gemini 走 ChatGPT 的路子,加了用户手动录入。三家各自一套,互不相通。
OMP 的解法是绕开厂商,自己定义一层协议。
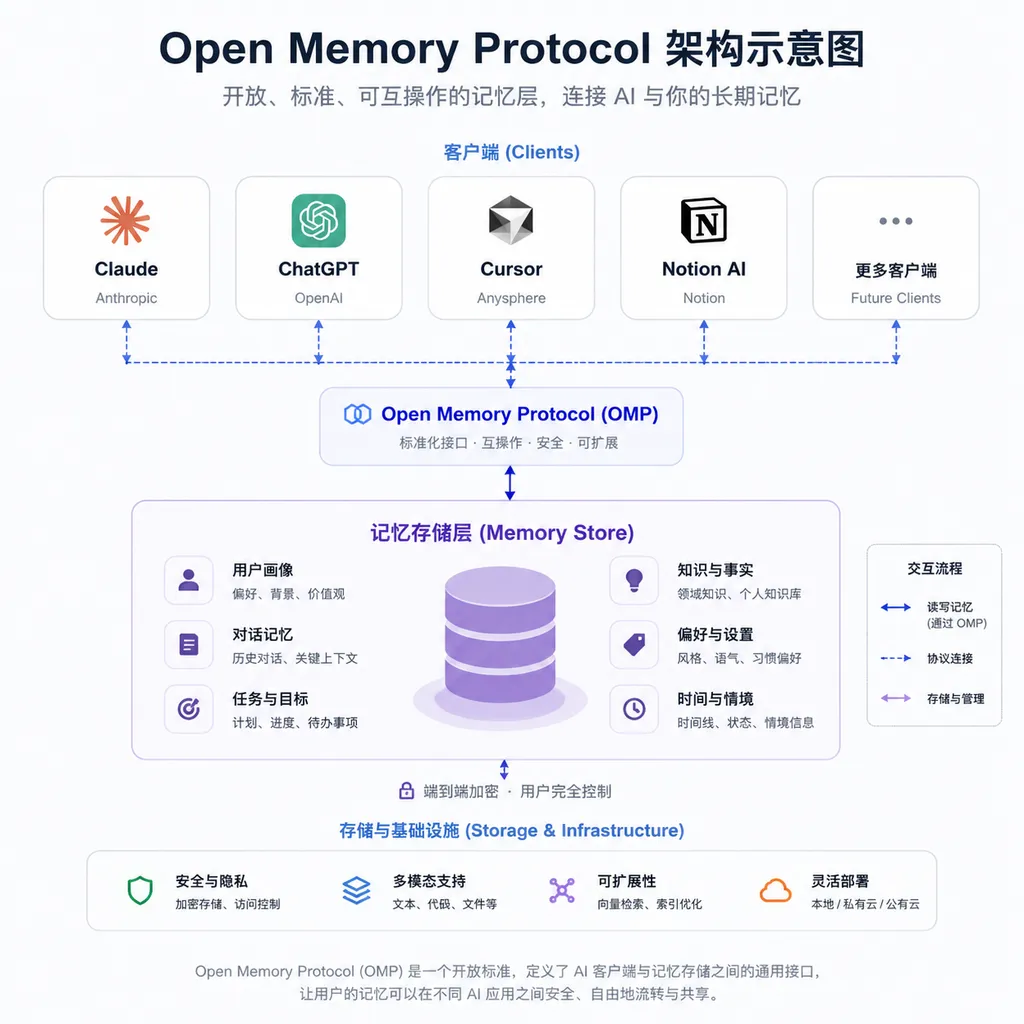
它到底是什么
严格说,Open Memory Protocol 不是一个产品,是一份规范加一套参考实现。规范定义了记忆条目的数据结构、读写接口、权限模型;参考实现给了一个本地跑的服务端,加上对接 Claude Desktop、ChatGPT 桌面端、Cursor 的客户端适配器。
核心数据模型挺克制,每条记忆是这么几个字段:
id:UUID,全局唯一content:记忆本体,自然语言文本category:分类标签,比如preference、project、factsource:这条记忆是从哪个客户端写入的created_at/updated_at:时间戳embedding:可选的向量表示,用于语义检索metadata:自由扩展字段
读写走 HTTP,端口默认 8765,本地运行。客户端用 MCP(Model Context Protocol)协议接进来——这点很关键,意味着 OMP 没有重新发明轮子,而是站在 Anthropic 去年推的 MCP 上做扩展。Claude Desktop 原生支持 MCP,Cursor 也跟进了,ChatGPT 桌面端目前是通过一个中间层适配。
检索逻辑分两条路径:精确匹配走传统关键词,语义召回走向量相似度。默认用本地的 sentence-transformers 模型生成 embedding,不依赖云端,这点对担心隐私的开发者算是友好。
为什么现在才出现
要理解 OMP 的意义,得看看 LLM 记忆这条赛道这两年挤成什么样。
2024 年到 2025 年,光是学术圈就涌出来一堆方案。MemGPT 把操作系统的分页机制搬到了大模型上,做了一个分层内存系统;北邮的 MemoryOS 进一步把段页式存储和人脑分层记忆机制揉在一起;MIRIX 拆出六种记忆组件各司其职;字节联合浙大、上交搞了个 M3-Agent,把记忆能力扩展到视频和音频。商业产品这边,Letta(前身就是 MemGPT 那帮人)、Mem0、Zep、记忆张量的 MemOS 一字排开。
但这些方案有个共同的局限:它们都在解决「单个 Agent 怎么记得更多」,没解决「多个 Agent 怎么共享记忆」。Mem0 之前出过一个浏览器插件,能在 ChatGPT 和 Claude 网页端之间同步记忆,但那更像一个 hack——通过油猴脚本读取 DOM、注入 prompt,本质上是在用户界面层做拼接,不是协议级的互通。
OMP 的位置不一样。它把自己定义在协议层,类似于 LSP(语言服务器协议)之于编辑器,或者 OpenAI Chat Completions API 之于推理服务。一旦协议被广泛接受,谁来实现客户端、谁来实现服务端,是市场的事。
这也解释了为什么开源社区会盯上它。MCP 推出大半年下来,已经成了事实标准之一,连 OpenAI 都在去年底跟进支持。在 MCP 上长记忆层,时机刚好。
跟既有方案比,差在哪、强在哪

摆事实讲,OMP 当前版本(v0.3)还很早期。它没有 Mem0 那种成熟的图记忆能力,没有 MemoryOS 的段页式调度,更没有 MIRIX 那样精细的多模态记忆组件。技术深度上,跟学术派的方案差着一两个身位。
但它有两点确实抓到了痛点:
第一是「协议优先」的姿态。OMP 没花精力做花哨的记忆算法,而是先把数据格式、接口契约、权限模型这些「无聊但关键」的东西定下来。这种打法在工程领域屡试不爽——Docker 不是最早的容器,Kubernetes 不是最强的编排,但它们都赢在协议和生态。
第二是「本地优先」的部署模型。所有记忆默认存在本地 SQLite + 向量索引里,不强制上云。这对企业用户和注重隐私的个人开发者是关键卖点。Anthropic 的记忆导入工具虽然今年 3 月开放给免费用户了,但记忆本身还是存在 Anthropic 服务器;ChatGPT 同理。OMP 把数据主权还给用户。
短板也很明显:
- 缺乏遗忘机制。在那篇被引用上千次的《Survey of Memory in AI》综述里,Forgetting 被列为六大原子操作之一,OMP 目前只有简单的过期删除,没有语义级的遗忘策略。
- 没有冲突处理。当 ChatGPT 写入一条「用户喜欢 Vim」而 Cursor 写入「用户用 VSCode」时,OMP 不会主动检测矛盾,只会两条都留着。
- 多模态支持薄弱。目前只处理文本,图片、代码片段还得手动序列化成字符串。
它会被采纳吗
这是个值得展开聊的问题。
开源项目能不能成,从来不只看代码质量。MCP 能起来,靠的是 Anthropic 自己用、Claude Desktop 内置、再推给社区——一个有重量级背书的协议自然滚得动。OMP 现在没有这种背书,是社区自发的项目,作者 SMJAI 此前没什么知名作品。
但它有一个隐性优势:不需要厂商许可。因为协议跑在客户端侧,通过 MCP 接入,理论上只要 Claude Desktop、Cursor 这些工具继续支持 MCP,OMP 就能工作。它不需要 Anthropic 同意,也不需要 OpenAI 配合,只要用户愿意装一个本地服务就行。
这种「绕过厂商」的设计很像早年的 RSS——你不需要 Twitter 同意,就能用 RSS 阅读器订阅它(在 Twitter 关掉 RSS 之前)。代价是,一旦厂商收紧 MCP 兼容性,整个生态就会受影响。
短期看,OMP 最有可能先在开发者群体里扩散。这群人本来就习惯多工具切换,对「记忆碎片化」感受最深。Cursor 写代码、Claude 写文档、ChatGPT 做头脑风暴,每天在三四个 AI 之间来回跳的开发者,太需要一个统一的记忆层了。
中长期,如果有一两家工具厂商主动适配 OMP,或者它和某个主流的 AI 客户端框架(比如 Open WebUI、LibreChat)深度集成,势能会起来得很快。
给开发者的几个观察
如果你打算上手试试,几个值得注意的点:
- MCP 兼容性是前提。先确认你的客户端支持 MCP,Claude Desktop 和 Cursor 都开箱可用,ChatGPT 桌面端需要走 OMP 提供的代理适配器。
- 默认 embedding 模型偏小。用的是
all-MiniLM-L6-v2,384 维,速度快但语义精度一般。如果你的记忆量大,建议换成bge-large或者直接接 OpenAI 的 embedding API。 - 权限模型还很粗。当前版本只有「全开放」和「只读」两种模式,没法按客户端做细粒度授权。生产场景慎用。
- 备份要自己做。SQLite 数据库放在
~/.omp/memory.db,没有内建的同步或备份机制。
对于需要在多模型之间切换的团队,OMP 这种统一记忆层的思路值得跟一跟。OpenAI Hub 那边目前用一个 Key 就能调 GPT、Claude、Gemini、DeepSeek 等主流模型,本身就解决了「调用入口统一」的问题,再叠加 OMP 这类记忆层方案,理论上能做到调用和上下文都不分家。当然这是后话,OMP 自己也才 v0.3,离生产可用还有距离。
记忆是 AI 的下一道分水岭
再往大里看一层。
过去三年,大模型的竞争主线在两个地方:模型能力本身,和上下文窗口长度。前者卷参数、卷 RLHF、卷推理;后者从 4K 卷到 200K,再卷到 100 万 token。但越来越多的从业者意识到,把所有东西塞进上下文不是长久之计——成本高、延迟大、注意力还会被稀释。
记忆是另一条路径。它把「让模型记得更多」这件事从推理时拆到了存储时,从一次性的 prompt 工程拆成了持久化的状态管理。这种范式更接近真实软件系统的设计——数据库和应用层本来就该分开。
香港中文大学、爱丁堡那批人去年发的综述里,把 AI 记忆归纳成参数化记忆和上下文记忆两大类,再拆出巩固、更新、索引、遗忘、检索、压缩六种原子操作。这套理论框架挺漂亮,但工程界缺的是把它落地的标准。
OMP 不一定是那个标准,但它代表了一个方向:记忆不该是某家厂商的私有功能,而该是基础设施。就像文件系统、数据库、消息队列那样,由开放协议定义,由不同实现竞争,最终用户用脚投票。
这条路要走通还很远。但开了头,总比一直把记忆锁在各家黑箱里好。
参考来源
- Open Memory Protocol – GitHub 仓库:项目代码、协议规范和参考实现,issue 区有不少社区讨论值得翻翻
- 深度解析 ChatGPT 和 Claude 的记忆机制 - 知乎:对两家主流 AI 记忆设计的详细技术拆解
- Anthropic 免费提供记忆汇入工具 向 ChatGPT 用户招手 - iThome:今年 3 月 Anthropic 把记忆导入工具下放免费用户的报道,可以看到厂商在记忆功能上的攻防节奏


