美团 LongCat-2.0 开源:万亿参数死磕 Agentic Coding
美团今日正式发布并开源 LongCat-2.0,1.6T 总参数 MoE 模型,平均激活 48B,原生 1M 上下文,全程跑在 5 万张国产算力卡上。从 4 月的内测预览到今天的彻底开源,美团把这张牌打成了国产万亿模型工程能力的样板。
美团今天把 LongCat-2.0 正式发布并开源了。距离今年 4 月那次悄无声息的 Preview 内测,过去了刚好两个月。
这是一个 1.6 万亿总参数、平均激活约 480 亿、动态范围在 33B 到 56B 之间的 MoE 模型,原生支持 1M 上下文。但这些数字不是今天最值得说的事情——值得说的是两件:第一,它是业界首个从预训练到推理全流程跑在五万卡国产算力集群上的万亿模型;第二,它从架构设计开始,就把目标钉死在了 Agentic Coding 上。
一家外卖公司,把万亿模型开源了
这事得倒回去看。
去年 9 月美团开源 LongCat-Flash 的时候,外界的反应基本是:哦,一个 560B 参数的 MoE,零计算专家机制挺有意思,但放在 DeepSeek、Qwen 的对照组里,并不算特别扎眼。当时大家更关心的是:王兴说要把美团 App 升级成 AI-Powered App,到底是认真的还是讲故事。
四个月后答案出来了。今年 4 月 20 日,longcat.ai 的更新日志里悄悄出现了 LongCat-2.0-Preview 这一项,没有公告、没有技术报告,只挂了三行说明:面向 Agent 开发、擅长代码生成与自动化工作流、已经深度集成 Claude Code、OpenClaw、OpenCode、Kilo Code。每天送 1000 万 token 免费额度,靠邀请制内测。
媒体的爆料几天后才跟上:参数破万亿、MoE、1M 上下文、5 到 6 万张国产卡、英伟达占比为零。
再到今天,模型权重正式开源、技术报告同步释出。从 Flash 到 2.0,美团用九个月时间把参数量从 560B 抬到了 1.6T,并且彻底脱离了英伟达供应链。这个节奏在国内大模型阵营里并不常见——通常你看到这种参数跃迁,背后都伴随着大量 H100 集群的采购故事。
1.6T 不是堆出来的,是“适配”出来的
要理解 LongCat-2.0 的工程价值,得先承认一个尴尬现实:国产加速卡单卡 HBM 容量大约 60GB,英伟达 H800/H100 是 80GB;带宽差距更大;CUDA 生态二十年的护城河更不是一两年能补齐的。
在这种硬件条件下硬训万亿模型,等同于让你用经济舱的腿部空间装下商务舱的人——只能在系统设计上动刀。LongCat-2.0 团队的几个关键决策值得拎出来:
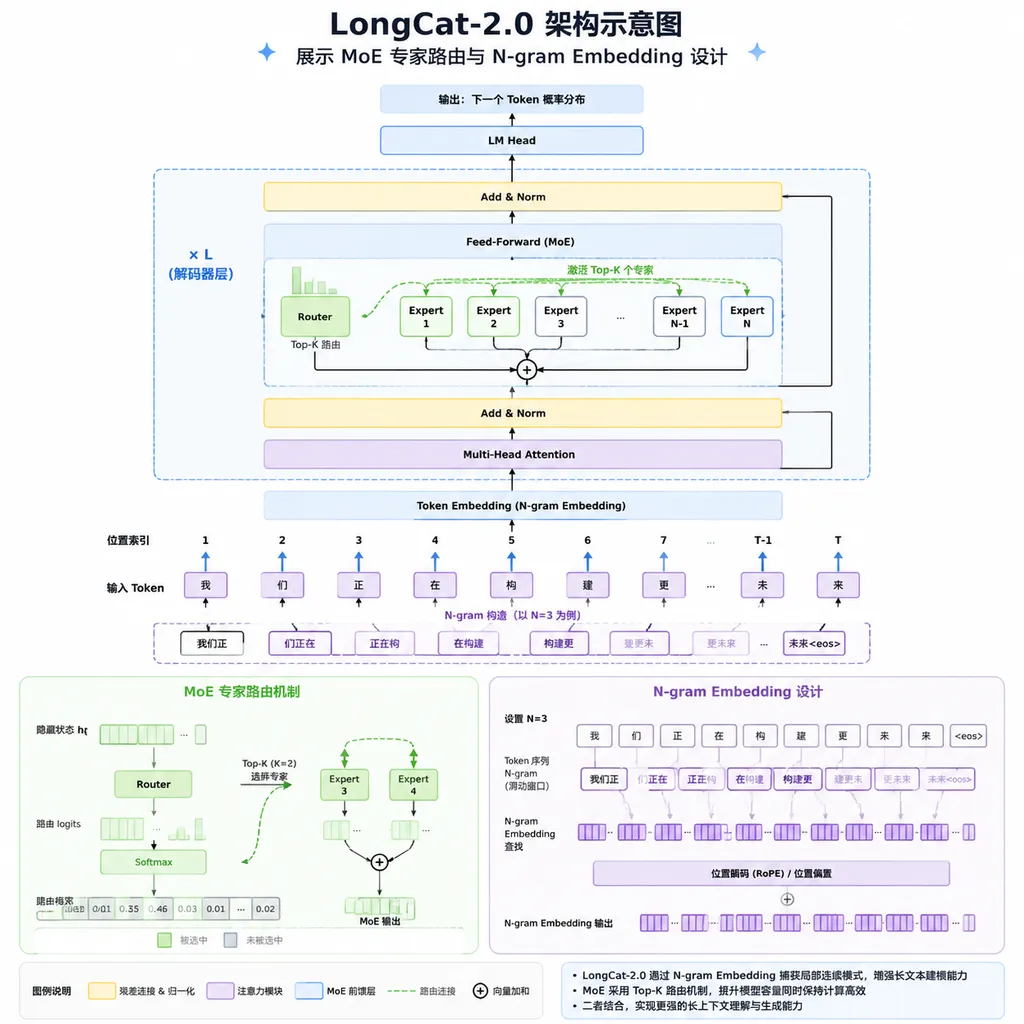
N-gram Embedding。把一部分 FFN 专家层的参数前移到 embedding 层,引入词组级建模。高频语言模式直接命中,不必走完整 MoE 路由。这个设计的实际意义不是“更聪明”,而是减少跨节点通信开销——万亿参数模型最贵的从来不是算力,是数万张卡之间的 all-to-all 通信。HBM 带宽不够,那就让该走带宽的东西尽量别走。
轻量稀疏注意力 + 跨层流感知索引。原生 1M 上下文如果走全量 attention,显存直接爆掉。团队的做法是稀疏化加跨层复用,避免重复计算。这条路线和 DeepSeek 的 NSA、Kimi 的 MoBA 思路上同源,但在万亿尺度上能稳定跑通,工程难度高一个量级。
确定性 FAG 算子 + Scatter 算子重写。性能损失控制在 5% 以内,Scatter 类算子提速数十倍。这是纯粹的脏活累活,没有 CUDA kernel 抄,只能自己写。
容错与恢复。链路感知、自动重调度、多层异常检测。数万张卡跑几个月不掉链子,这件事在英伟达集群上都不容易,在国产卡上要做到,等同于把 PyTorch + NCCL + 调度器整条栈重写一遍。
把这些拼起来,LongCat-2.0 真正卖的不是参数,而是一份国产算力训万亿模型的工程手册。从这个角度看,它跟 DeepSeek V3/V4 算是互补:DeepSeek 在算法效率上把模型推向极限,美团在硬件适配上把工程极限往前推了一格。
真正的赌注:Agentic Coding
参数和算力的故事讲完,得回到模型本身的定位。
LongCat-2.0 不是一个通用 Chat 模型,它的架构选型从第一天起就为 Agentic Coding 服务。这是 2026 年最拥挤也最关键的赛道——Claude 4.5、GPT-5.5、Gemini 3 都在抢的市场。
美团选这条路的逻辑挺直白:
- 1M 上下文是 Agent 任务的硬通货。你要让模型读一整个 monorepo、跟踪几十个工具调用记录、维持一个跨小时的任务状态,没有百万级上下文就是空谈。
- MoE 的动态激活适合 Agent 的非均匀负载。同一个 Agent 流水线里,规划阶段、写代码阶段、调试阶段对模型能力的要求完全不同,48B 平均激活、33B 到 56B 动态调整,比稠密模型经济得多。
- 深度集成 Claude Code、OpenClaw、OpenCode、Kilo Code。这一步比技术报告更说明态度——美团没打算让你用 LongCat 替代 ChatGPT 聊天,而是直接钉死在“给你的 Coding Agent 换个国产大脑”。
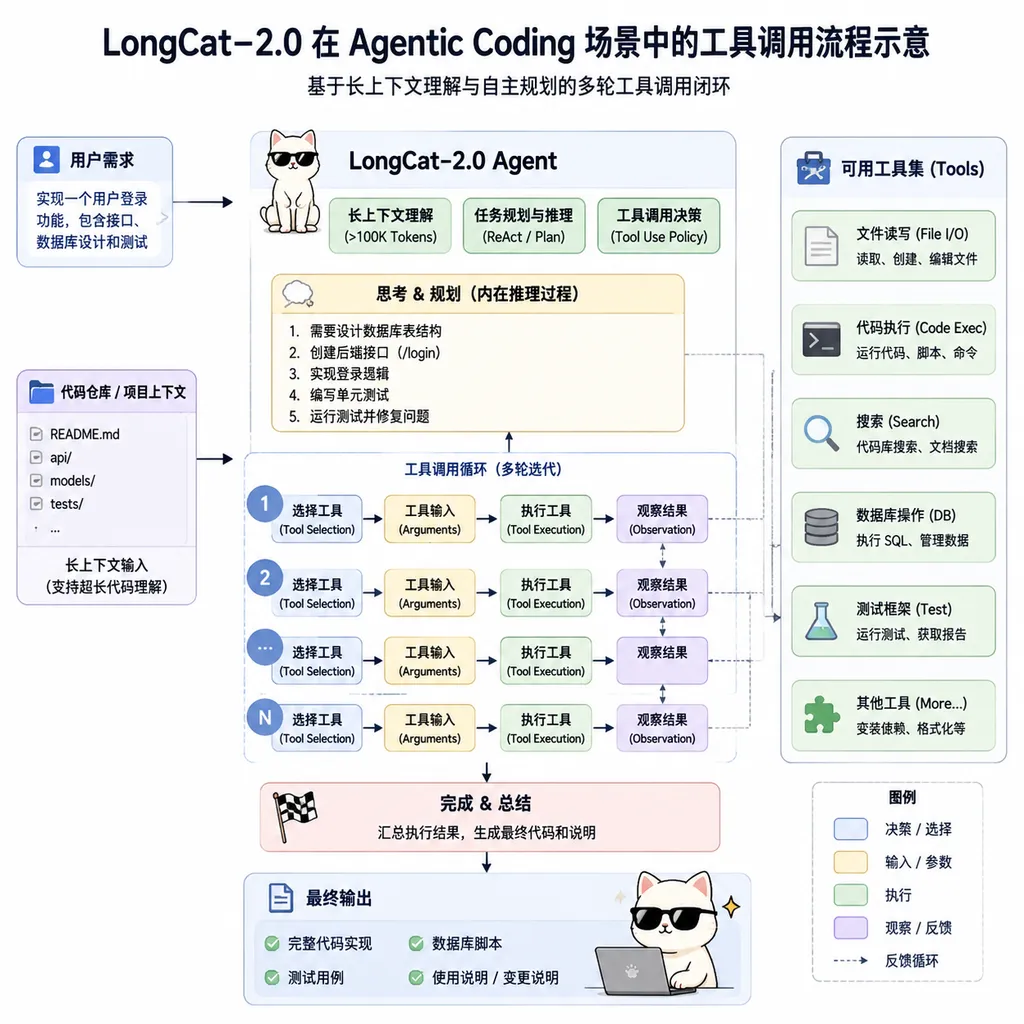
按官方披露的能力图谱,LongCat-2.0 在工具调用、多步推理、复杂指令执行上做了原生优化。这套优化的真实价值得跑 SWE-bench Verified、Terminal-Bench、TAU-bench 这类 Agent 基准才能验证,目前技术报告里给了一组对比数据,相对前代 Flash 在代码任务上提升明显,但跟 Claude Sonnet 4.5、GPT-5.5 在 Agentic 场景的正面 PK,还得等社区第三方评测。
开源策略:这次是真开源
4 月那次只放了 API 没放权重,被吐槽“悄悄发布、没有公告、没有开源”。这次美团把欠的全还了:
- 模型权重完整开源,许可证按官方公告允许商用
- 技术报告同步释出,覆盖训练框架、算子、容错系统等工程细节
- longcat.ai 平台继续提供免费 API 额度,方便不想自己部署的开发者直接接入
- Hugging Face 同步上线,方便社区做 fine-tune 和量化
这套打法跟 DeepSeek、Qwen 的玩法在 2026 年已经形成了某种默契:先把权重和报告砸出来,让社区帮你做生态。对开发者来说,1.6T 模型自己部署门槛极高,但 4-bit 量化版、蒸馏版、各种 LoRA 很快会在社区涌现。
如果你不想折腾本地部署,OpenAI Hub 这边也接入了 LongCat-2.0,跟 GPT-5.5、Claude 4.5、DeepSeek V4 一样走 OpenAI 兼容格式,一个 Key 切换调用,国内直连。
几点判断
聊几句态度。
第一,LongCat-2.0 的真正分量在工程,不在 SOTA。如果你只看 benchmark 跑分,它大概率不会让你眼前一亮——Claude 4.5 和 GPT-5.5 在 Agentic Coding 上的领先地位短期不会被撼动。但如果你关心的是“万亿模型在国产芯片上能不能跑、怎么跑”,这份开源材料的价值高得多。
第二,美团这步棋是产业棋,不是学术棋。1.6T、五万卡、国产算力,每一个数字背后都是资本开支。王兴 2024 年说要投入数十亿美元保障算力,现在结果摆在桌面上:美团不是在做大模型副业,是真的在把基础设施层面的能力建起来。考虑到外卖、本地生活、酒旅业务里堆着海量需要 Agent 化的实际场景,这事的商业逻辑是闭环的。
第三,国产算力的故事到了一个新拐点。过去几年“国产替代”更多是一种姿态,2026 年上半年——DeepSeek 的算法突破加上美团的工程突破——开始让这件事变成可执行的工程路径。这不意味着英伟达没用了,而是意味着如果出口管制再升级,国内头部公司有了 Plan B。
第四,开发者该不该用? 如果你正在做 Coding Agent 工具链,LongCat-2.0 值得拉下来跑一遍——尤其是它跟 Claude Code、OpenCode 这类工具的原生集成已经做好,迁移成本可控。如果你只是写日常聊天应用,那它的价值排序会落在 GPT-5.5、Claude 4.5 之后。模型选型从来不是看参数,看场景。
万亿参数的开源浪潮在 2026 年继续往前推。LongCat-2.0 不会是终点,但它把“国产算力跑万亿模型”这件事,从 PPT 推到了 GitHub。
参考来源
- IT之家:美团万亿级大模型 LongCat-2.0-Preview 开放测试 - 4 月内测期的早期报道,含算力规模披露
- Hugging Face: LongCat 模型仓库 - 美团官方模型权重与技术文档发布地
- GitHub: LongCat 项目主页 - 推理代码、部署脚本与社区 Issue 跟踪
- 掘金:LongCat-Flash 技术解读 - 前代 LongCat-Flash 的国产算力训练经验总结
- 知乎:万亿 MoE 模型工程实践讨论 - 社区对 N-gram Embedding 与稀疏注意力的技术分析


