华为开源盘古2.0:920亿参数Flash版今日上线

华为今日正式开源 openPangu-2.0-Flash,总参数 920 亿、激活 60 亿的稀疏 MoE 模型,配 512K 上下文,专为昇腾算力深度调优。Pro 版本 505B 参数将于 7 月跟进。
今天(6 月 30 日),华为按月初 HDC 2026 上的承诺,把开源盘古 2.0 系列的第一块拼图放了出来——openPangu-2.0-Flash 正式开源上线,模型权重、基础推理代码、训推算子一并打包,挂在 GitCode 的 ascend-tribe 仓库下。
这是华为大模型业务自去年国庆余承东重新接手以来,最重要的一次开源动作。Flash 是先头部队,505B 的旗舰版 Pro 紧跟着 7 月上线,剩下的预训练代码、后训练代码等组件会在下半年陆续放出。整套 openPangu 2.0 一共要开源 7 大组件,比业界惯例的"权重+推理代码+技术报告"四件套多了三样硬货。

一个轻量版,但参数一点不轻
先把规格摆出来:
- 总参数量:92B(920 亿)
- 激活参数量:6B(60 亿)
- 上下文窗口:512K
- 架构:稀疏 MoE
- 目标硬件:昇腾原生优化
华为把它叫"Flash"、定位"轻量化部署",但 920 亿的总参数在开源 MoE 里已经不算小了。关键看激活参数——6B 的激活规模,意味着实际推理时算力开销接近一个 6B 稠密模型的水平,但能力上限按 92B 的总容量来兜底。这套思路和 DeepSeek-V2、Qwen3-MoE 的路子是一脉相承的:用稀疏激活换取"大模型的脑子、小模型的开销"。
Flash 版本特意把稀疏配比调低了。稀疏配比简单说就是每次 forward 激活多少专家、用掉多大比例的参数。比例越低,单 token 推理的实际算力消耗越小,但对路由准确度和专家训练充分度的要求越高。华为这次的取舍很明显——Flash 是为单卡、低时延、端侧或边缘场景准备的,跑得快比跑得满更重要。
512K 上下文 + Agent 优化,瞄准的是鸿蒙
两个版本都标配 512K 上下文,这个长度在开源阵营里属于第一梯队,和 Gemini、Claude 拉到了同一个量级。但华为开 512K 的真实动机,看一下鸿蒙就明白了。
openPangu 2.0 在官方叙述里被反复定位为"鸿蒙生态的智能底座"。鸿蒙的 Agent 体系需要跨应用调度、长任务记忆、复杂工具调用,这些场景对上下文长度的胃口是无底的。512K 不是为了刷 benchmark,是为了让 Agent 在手机和 PC 上能装下完整的会话历史、文档上下文和工具状态。华为在发布会上也明说了,Flash 在鸿蒙体系里对 Agent 任务做了专项优化——执行速度、精准度、资源占用三个指标一起调。
这一点其实挺值得开发者关注。大多数开源模型的"长上下文"是训练目标,不是部署目标——给你 128K,但你跑起来 KV Cache 直接把显存吃光。Flash 把 6B 激活和 512K 上下文捏在一起,意图就是让长上下文真的能在端侧跑起来。
昇腾原生:这才是开源动作背后的真正信号
华为这次开源最值得拆开看的,不是参数,是它的硬件叙事。
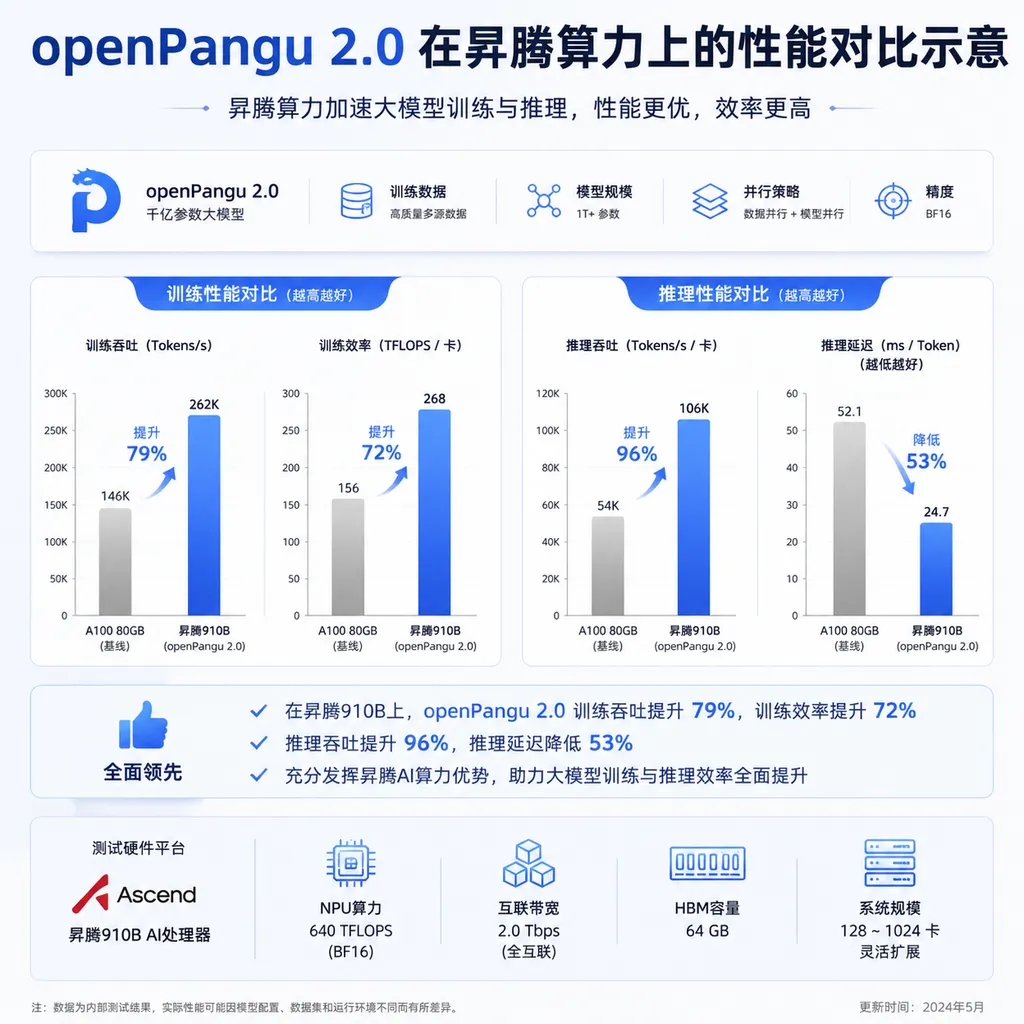
官方反复强调"昇腾原生训练与推理"。openPangu 2.0 在昇腾算力上的单卡推理吞吐率,按华为自己的数据,"可达业界主流开源模型的 2 倍"。这个数字怎么来的没细说,但思路是清楚的——模型架构、算子实现、推理调度,全栈针对昇腾做了优化。
开源出来的"训推算子"是关键组件。算子层面的开源在业界并不常见,多数厂商只放权重和推理框架壳子。华为这次把算子也甩出来,等于告诉所有跑昇腾的开发者:拿走,改,调,全是给你看的样板。结合 MindSpore 框架、昇腾芯片、鸿蒙系统这一整套"端到端自主可控"的叙事,盘古 2.0 的开源更像是给国产 AI 栈做的一次完整的开发者教程。
余承东在 HDC 2026 上有一句话挺有意思——他坦言华为留给自己的算力规模有限,大量算力要去支持国内其他企业的需求。这句话翻译一下:盘古的开源不是因为它过剩,而是因为华为算力本来就紧张,必须用开源换生态,用生态摊薄成本。
和谁比?开源 MoE 的赛道已经很挤了
把 Flash 放到 2026 年中这个时间点的开源 MoE 阵营里看:
- DeepSeek 系列:已经把开源 MoE 的性价比天花板推到了一个相当高的位置
- Qwen3-MoE:阿里同样在 MoE 上压重注,生态成熟度强
- Mixtral 后继:欧洲那边节奏放缓,但仍在更新
- GLM、MiniMax 等国内开源:路线各异,竞争激烈
92B 总参 / 6B 激活这个配比,对标的更像是 DeepSeek-V2-Lite 那一档的定位——不是要在通用 benchmark 上一鸣惊人,而是要在特定硬件、特定场景下做到能用、好用、跑得动。
说句实在的:openPangu 2.0 Flash 在通用能力上能不能打过同等规模的 DeepSeek 或 Qwen,得等社区跑分出来。但如果你用的是昇腾、做的是鸿蒙生态、或者关注国产化栈,这就是一个绕不开的选项。
开源得到底有多干净
华为这次开源的口径,比上一代盘古要诚意得多。盘古 1.0 时代被诟病过开源不够彻底,这次七大组件分批开放:
- 模型结构
- 模型权重
- 技术报告
- 推理代码
- 预训练代码(新增)
- 后训练代码(新增)
- 训推算子(新增)
后三项是这次开源的差异化卖点。预训练代码意味着你可以从头复现训练流程,后训练代码覆盖了 SFT、RLHF 这类对齐环节,训推算子让你能在昇腾上自己调优。理论上,一个团队拿到这套东西,可以在自己的数据上重新训一个盘古风格的模型出来——前提是你有匹配的算力。
仓库地址在 GitCode 上:gitcode.com/ascend-tribe。Flash 的权重、推理代码、算子今天就能拉到本地。
开发者怎么上手
如果你手上有昇腾设备,路径最直接:拉权重、装 MindSpore(或者 PyTorch + 昇腾后端)、用官方推理代码跑起来。算子是优化过的,单卡吞吐应该能立刻看出区别。
如果你用的是 NVIDIA 卡,情况复杂一些——权重是开源的没问题,但官方算子是针对昇腾写的,在 CUDA 上跑需要自己适配,或者等社区贡献。MoE 架构在主流推理框架(vLLM、SGLang)上的支持比一年前成熟很多,预计很快会有人接进去。
云端调用方面,目前 openPangu 2.0 还在开源平台铺开阶段,主流 API 聚合服务暂时还没接入,可以观望一下后续社区跟进的节奏。
一个判断
华为这次开源的姿态,比模型本身更值得关注。
Flash 920 亿参数、512K 上下文、昇腾原生、Agent 优化——这些标签拼出来的画像很清晰:这不是一个想冲榜单的模型,而是一个想做国产 AI 栈样板间的模型。它的目标用户是用昇腾、做鸿蒙、关心自主可控的开发者和企业,不是 Hugging Face 上刷榜的研究者。
7 月 Pro 版本上线后,整个 openPangu 2.0 系列才算完整。到那时候再回头看 Flash,它的定位会更清楚——前哨站,不是主力舰。但作为前哨站,它的诚意、规格、硬件协同度都到位了。
剩下的,就看社区愿不愿意接住这一棒。
参考来源
- 华为 openPangu-2.0-Flash 模型正式开源上线(IT之家) — 详细的开源信息和 7 大组件开放节奏
- 华为发布 openPangu 2.0 讨论(linux.do) — 社区对模型规格和开源策略的讨论
- Huawei released openPangu 2.0(Reddit r/LocalLLaMA) — 海外开发者社区对盘古 2.0 吞吐率与架构的讨论

