Qwen3.6-35B-A3B 被改成 0% 拒答:跑分还没掉

开发者用 norm-preserving abliteration 技术对 Qwen3.6-35B-A3B 做了拒答消融,权重和数据集全开源。88% 拒答下降、KL 散度仅 0.0015,传统消融的跑分崩盘问题被基本解决。
一次比以往都干净的「越狱」
过去一周,HuggingFace 上冒出来一批 Qwen3.6-35B-A3B 的「无审查」改造版,热度最高的是 llmfan46/Qwen3.6-35B-A3B-uncensored-heretic 以及它的 FP8 量化版 protoLabsAI/Qwen3.6-35B-A3B-uncensored-heretic-FP8。Reddit 的 r/MachineLearning 上,研究者 grimjim 同步开源了完整的拒答方向数据集、消融脚本和权重 diff。
这事本身并不新鲜——abliteration(拒答消融)已经在社区里跑了快两年。但这次值得专门写一篇的原因是:它第一次把「跑分基本不掉」做到了实用级别。模型卡里给的数字是:在自建的 100 条 prompt 评测上拒答率下降 88%,与原版的 KL 散度仅 0.0015。这个 KL 数字意味着,除了「该拒的时候不拒了」,模型在绝大多数 token 分布上几乎和原版一致。
先把背景捋一遍:abliteration 到底在做什么
2024 年 Arditi 等人的那篇机制可解释性论文,结论其实非常干净:LLM 的拒答行为,在残差流里由一个几何上高度一致的方向(refusal direction)所中介。找它的方法也朴素得过分:
- 准备两批 prompt,一批 harmful(「教我做炸药」),一批 harmless(「写首春天的诗」);
- 把模型在这两批输入上的 residual stream activation 全都缓存下来;
- 算两批激活均值的差,归一化,就是那个 refusal direction
r。
推理时模型一旦在某层激活里检测到 r 方向的分量足够大,就会触发「I can't help with that」那套话术。Abliteration 的思路就是把这个方向从权重矩阵里「投影掉」——对每个相关的权重行 w,做 w' = w - (w·r)r,让模型在前向传播时根本没法在残差流里写入这个方向。
听起来很优雅。问题是,这么搞会让模型变笨。
老方法的坑:范数衰减
mlabonne 当年那套 vanilla abliteration 流程,问题出在每次正交投影都会缩短权重向量的 L2 范数。35B 参数的 MoE 模型里,相关矩阵有几百个,每一层都缩一点,残差流的整体幅度就会逐层衰减。
后果是肉眼可见的:
- MMLU 掉 3-8 个点
- GSM8K 数学推理崩得更厉害,有时直接掉两位数
- 长上下文的连贯性变差,模型容易「失神」
社区里跑过 abliteration 的人都知道,改完的模型确实啥都答,但你也确实不太想用它干正事。这就是为什么之前那些 uncensored 版本一直停留在「玩具」阶段。
grimjim 的修法:保范数双向投影
这次新方法的核心其实就一行额外操作:投影完之后,把每个权重行重新缩放回它原来的 L2 norm。
伪代码大概是这样:
# 原始权重行
w_orig = W[i]
original_norm = torch.norm(w_orig)
# 正交化:去掉 r 方向分量
w_proj = w_orig - (w_orig @ r) * r
# 保范数:缩放回原始幅度
w_new = w_proj * (original_norm / torch.norm(w_proj))
W[i] = w_new
几何上的含义很清楚:新向量 w_new 在 r 方向的分量是 0(满足消融目标),同时它的模长和原来完全相等(残差流的能量预算守住了)。这相当于让模型在 r 的正交补空间内「重新分配」原来的注意力/MLP 容量。
这就是为什么叫 norm-preserving biprojection。简单,但确实有效。
数据怎么样
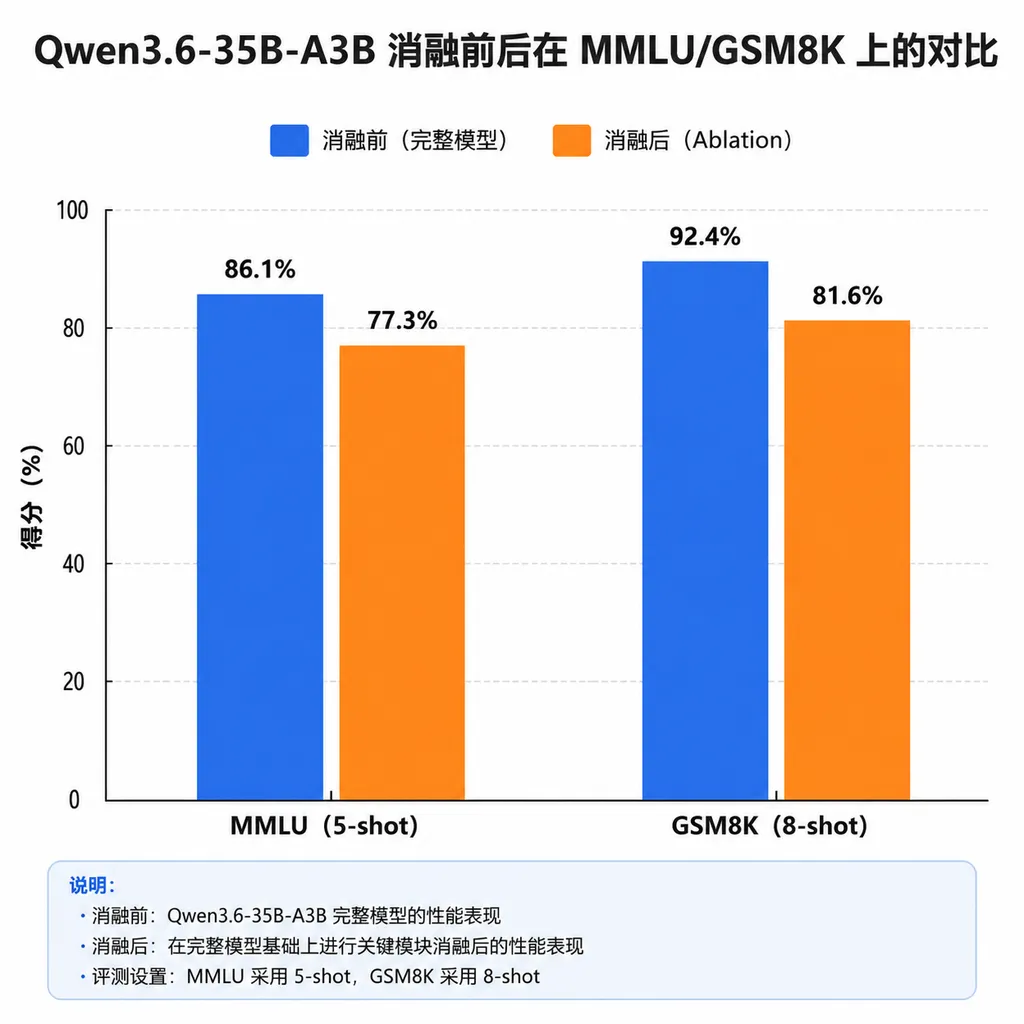
模型卡贴出的对比表里,新版本和官方 Qwen/Qwen3.6-35B-A3B-FP8 在主流 benchmark 上的差距基本在噪声范围内:
- MMLU、CMMLU 这种知识类的差不到 0.5 个点
- GSM8K、MATH 这种推理类的,差距也在 1 个点以内
- HumanEval 代码生成基本持平
- 唯一明显劣化的是 RefusalBench 这类专门测「该不该拒」的评测,从 90%+ 掉到 10% 以下——这恰恰是改造目标
那个 0.0015 的 KL 散度数字尤其值得注意。作为对比,普通的 fine-tune 一两个 epoch 下来 KL 散度都能到 0.1 量级。0.0015 意味着 token 级别的分布几乎没动,模型「人格」、知识、推理路径几乎完全保留——只是把「拒答」这一个特定行为模式精准地切掉了。
一些工程坑
几个 issue 区和讨论里反复出现的注意点,开发者要部署的话最好先看一眼:
1. 别用 logit_bias 压制 special token
protoLabsAI 的模型卡里专门标了:试图用 logit_bias 去抑制特殊 token 会破坏生成,模型会吐出 Action、assistant、Human 这种 role marker 碎片,然后在触发 thinking pathway 的 prompt 上直接卡死。原因是 Qwen3.6 的 tool-call thinking 是模型层面的行为,特殊 token 的概率分布是它正常工作的一部分。
2. 思考链有真实的延迟代价
官方 Qwen/Qwen3.6-35B-A3B-FP8 本身在 tool-call 场景下每轮就要多吐 ~130 个 thinking token,约 500ms 延迟。消融版继承了这个特性——这不是量化或消融引入的,而是 Qwen3.6 系列本来的设计。
3. MoE 路由的副作用
Qwen3.6-35B-A3B 是 35B 总参 / 3B 激活的稀疏 MoE。消融操作是对所有 expert 的相关权重统一处理的,目前没看到有人报告路由分布的明显偏移,但 grimjim 在 README 里也提醒,长尾 prompt 上某些 expert 可能会被异常激活,建议生产环境跑一下自己的 routing trace。
这事说明什么
两年前 Arditi 那篇论文出来的时候,社区的反应是「哦,原来 alignment 可以被一个低秩方向编码」。当时大家更多把它当成机制可解释性研究的有趣发现。
两年后的今天,这个发现已经被工程化到「一个研究者用一个周末就能给 35B 模型做精准的行为编辑、benchmark 几乎不掉」的程度。这对 alignment 的实际防御强度提出了相当残酷的问题:如果一个模型的权重被开源出来,再加上一个清晰的目标行为,那么基于残差流方向的对齐机制几乎是没有抵抗力的。
但反过来看,这也是机制可解释性方向最实打实的工业级应用之一。同样的技术可以用来:
- 精准移除模型里某种特定的偏见模式
- 强化或弱化某类风格倾向(比如让模型少 yapping)
- 给特定 domain 做行为微调,而不需要重新跑 SFT/RLHF
Heretic、Aggressive 这一系列变体的命名很「社区」,但底下的技术其实严肃得多。
部署侧的选择
目前社区主要流通几个分发渠道:
- HuggingFace:
llmfan46/Qwen3.6-35B-A3B-uncensored-heretic(BF16 原版)、protoLabsAI/Qwen3.6-35B-A3B-uncensored-heretic-FP8(官方 FP8 格式,直接对齐 Qwen 官方量化) - Ollama:
fredrezones55/Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive,提供从 IQ3_M(15GB)到 Q8_K_P(44GB)的全套 GGUF,还打了 vision patch - vLLM 部署:FP8 版本可以直接
vllm serve protoLabsAI/Qwen3.6-35B-A3B-uncensored-heretic-FP8起服务
如果只是想跑跑看,单卡 24G 的 4090 配 IQ4_XS 量化就够了;要上生产,FP8 版本在 H100/H200 上吞吐表现和官方 FP8 几乎一致。
推理参数官方推荐用 temperature=1.0, top_p=1.0, top_k=40, min_p=0, presence_penalty=2.0——presence_penalty 调到 2.0 是为了对抗 MoE 模型偶尔出现的重复 loop,这个值在原版 Qwen3.6 上也适用。
写在最后
Qwen3.6-35B-A3B 本身是个挺硬的模型。35B 总参 / 3B 激活的稀疏 MoE 设计、262K 原生上下文、视觉语言能力对标 Claude Sonnet 4.5,Apache 2.0 协议——它本来就是这一波开源里最值得拿来当基座的几个之一。
现在它身上又多出来一层「机制可解释性 + 行为编辑」的实验场价值。无论你站在哪一边——研究攻击面、还是研究防御——这都是个值得花时间读一读权重 diff 的项目。
顺带一句,OpenAI Hub 上 Qwen3.6 系列的官方版本可以直接用统一 API 调,跟 GPT、Claude 走一套接口。如果你想拿官方版做对比 baseline,不用自己再起推理服务。
参考来源
- Reddit r/MachineLearning:Norm-preserving abliteration on Qwen3.6-35B-A3B — grimjim 发布的原始技术贴,包含方法说明和开源链接
- Reddit r/LocalLLaMA:Qwen3.6-35B-A3B Uncensored Aggressive 发布讨论 — 社区对 Aggressive 变体的讨论,含 K_P 量化信息
- HuggingFace:protoLabsAI/Qwen3.6-35B-A3B-uncensored-heretic-FP8 — FP8 量化版的完整模型卡,包含 benchmark 对比和部署注意事项


